计算机视觉中的注意力机制(Attention Mechanism)
文章目录
- 1. 简介
- 2. 不同的注意力机制
- 2.1 SEBlock
- 2.1.1 SEBlock结构
- 2.1.2 实现
- 2.1.2.1 SEBlock的实现
- 2.2 PAM and CAM
- 2.2.1 Position Attention Module
- 2.2.2 Channel Attention Module
- 2.2.3 代码实现
- 2.3 CBAM
- 2.3.1 CBAM结构
- 2.3.1.1 Channel-Wise Attention
- 2.3.1.2 Spatial Attention Module
- 2.3.2 代码实现
- 2.4 Attention Gate
- 2.4.2 代码实现
- 2.5 Criss-Cross Attention
- 2.5.1 Criss-Cross Attention
- 2.5.2 Recurrent Criss-Cross Attention
- 2.6 Point-wise Spatial Attention
- 2.6.1 Bi-Direction
- 2.6.2 Point-Wise Spatial Attention Module
- 2.6.3 Point-Wise Spatial Attention
- 2.6.4 代码
1. 简介
深度学习中的注意力机制借鉴了人类的注意力思维方式。因此,我们首先简单介绍人类视觉的选择性注意力。视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是所说的注意力焦点,然后对这一区域投入更多的注意力资源,以获取更多所需要关注目标的细节信息,从而抑制其它无用信息。这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制。人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
Attention 机制最早出现于NLP领域之后被广泛应用于计算机视觉。下面总结下计算机视觉中的Attention,持续更新。
2. 不同的注意力机制
2.1 SEBlock
论文地址:Squeeze-and-Excitation Networks
2.1.1 SEBlock结构

上图便是SEBlock的结构,其中 X ∈ R H ′ ∗ W ′ ∗ C ′ X\in R^{H^{'}*W^{'}*C^{'}} X∈RH′∗W′∗C′是网络的输入,其中 F t r F_{tr} Ftr为一些列卷积操作的集合 V = [ v 1 , v 2 , . . . , v C ] V=[v_1,v_2,...,v_C] V=[v1,v2,...,vC]表示卷积操作, U ∈ R H ∗ W ∗ C U\in R^{H*W*C} U∈RH∗W∗C为经过一系列卷积操作的输出, U = [ u 1 , u 2 , . . . , u C ] U=[u_1,u_2,...,u_C] U=[u1,u2,...,uC]:
u C = v C ∗ X = ∑ s = 1 C ′ v C s ∗ X s , ∗ 是 卷 积 操 作 , v C s 是 卷 积 在 单 个 通 道 上 的 操 作 u_C=v_C*X=\sum_{s=1}^{C^{'}}v_C^s*X^s, *是卷积操作,v_C^s是卷积在单个通道上的操作 uC=vC∗X=s=1∑C′vCs∗Xs,∗是卷积操作,vCs是卷积在单个通道上的操作
以上就是基本的输入输出。SEBlock分为三个部分Sequeez,Excitation, Scale。
Sequeeze:
Sequeeze操作是将 U U U输出压缩成 Z ∈ R 1 ∗ 1 ∗ C Z\in R^{1*1*C} Z∈R1∗1∗C,作者认为传统的卷积操作过于集中于局部地区,而无法提取上下文关系(context),可以通过使用GAP(global average pooling)实现这一点来作用于每个通道上来进行通道选择。
z c = F s q ( u c ) = 1 H ∗ W ∑ i = 1 H ∑ j = 1 W u c ( i , j ) z_c=F_{sq}(u_c)=\frac{1}{H*W}\sum^{H}_{i=1}\sum_{j=1}^{W}u_c(i,j) zc=Fsq(uc)=H∗W1i=1∑Hj=1∑Wuc(i,j)
Excitation:
这一步是利用具有非线性的Sigmoid激活函数保证非线性的前提下进行通道选择。
s = F e x ( z , W ) = σ ( g ( z , w ) ) σ ( W 2 σ ( W 1 z ) ) s=F_{ex}(z,W)=\sigma(g(z,w))\sigma(W_2\sigma(W_1 z)) s=Fex(z,W)=σ(g(z,w))σ(W2σ(W1z))
公式中 W 1 ∈ R C r ∗ C , W 2 ∈ R C ∗ C r W_1\in R^{\frac{C}{r}*C}, W_2\in R^{C*\frac{C}{r}} W1∈RrC∗C,W2∈RC∗rC σ \sigma σ为 r e l u relu relu,为了限制网络的复杂度,使用全连接层进行通道reduction。
Scale:
这部分就是将学习到的通道权重应用到原有的feature上去,就是个简单的乘法。
x c ~ = F s c a l e ( u c , s c ) = s c u c , X ~ = [ x 1 ~ , . . . , x C ~ ] \tilde{x_c}=F_{scale}(u_c, s_c)=s_cu_c,\tilde{X}=[\tilde{x_1},...,\tilde{x_C}] xc~=Fscale(uc,sc)=scuc,X~=[x1~,...,xC~]
2.1.2 实现
SEBlock可以作为子模块插入不同的网络,作者在不同部分的选择过程中进行大量的实验进行比较选择。下面是不同网络实现的内容

2.1.2.1 SEBlock的实现
SEBlock的实现基本结构是sequeeze + fn1 + fn2 + excitation,然后原始输入和该结构得到的通道权重相乘即可,而不同分不同实现效果不同,见下面的实验。fn1先将sequeeze得到的权重的通道降低到 C r \frac{C}{r} rC,然再恢复到 C C C。
Sequeeze:
Sequeeze操作主要使用GAP(global average pooling)和GMP(global max pooling),下面是不同的选择的结果

Excitation:
Excitation操作主要可用为ReLU, Tanh, Sigmoid三个操作,下面是不同操作的效果:

reduction:
在具体实现中在sequeeze和excitation操作之间使用了两个全连接层先进行通道调整,而这里的通道调整比例为 r r r,不同的 r r r取值效果如下:

插入方式:
SEBlock不同的插入方式:


code
class se_layer(nn.Module):
def __init__(self, channel, reduction=16):
super(se_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
def main():
import numpy as np
feature = torch.rand(1, 16,7,7)
block = se_layer(16)
feature = block(feature)
print(feature)
2.2 PAM and CAM
论文地址:Dual Attention Network for Scene Segmentation
2.2.1 Position Attention Module

途中PAM分为四个分支,其中生成Attention的上BC两个分支,D用来生成经过attention map处理的feature,最下面的是保留原有的feature保证信息不丢失。
基本的流程:
- 输入 A ∈ R C ∗ H ∗ W A\in R^{C*H*W} A∈RC∗H∗W,BCD三个分支分别经过conv+batch_norm+relu得到对应的输出 B ∈ R R ∗ H ∗ W B\in R^{R*H*W} B∈RR∗H∗W, C ∈ R C ∗ H ∗ W C\in R^{C*H*W} C∈RC∗H∗W, D ∈ R C ∗ H ∗ W D\in R^{C*H*W} D∈RC∗H∗W
- B , C B,C B,C经过reshape维度编程 R C ∗ N , N = H ∗ W R^{C*N},N=H*W RC∗N,N=H∗W,然后 B T ∗ C B^{T}*C BT∗C得到 S R N ∗ N S^{R^{N*N}} SRN∗N,得到的输出经过softmax得到 S ∈ R ( H ∗ W ) ∗ ( H ∗ W ) S\in R^{(H*W)*(H*W)} S∈R(H∗W)∗(H∗W)的相应图,其中 s j i s_ji sji表示feature上点 j j j对 i i i的影响。
s j i = e x p ( B i ⋅ C j ) ∑ i = 1 N e x p ( B i ⋅ C j ) s_{ji}=\frac{exp(B_i\cdot C_j)}{\sum^{N}_{i=1}exp(B_i\cdot C_j)} sji=∑i=1Nexp(Bi⋅Cj)exp(Bi⋅Cj) - 得到的attention map和输入进行相乘的操作;
- 最后和原有的输入进行加权的相加,如下公式,其中 α \alpha α初始化为0,是可学习的。
E j = α ∑ i = 1 N ( s j i D i ) + A j E_j=\alpha \sum_{i=1}^{N}(s_{ji}D_i)+A_j Ej=αi=1∑N(sjiDi)+Aj
下面为流程图,不会出现feature之类的标签,主要以维度为主如C*H*W表示feature或者attention map是 C C C通道高宽为 H , W H,W H,W。
2.2.2 Channel Attention Module

CAM模块的操作和PAM非常相似不同之处是操作室基于通道的生成的attention map S S S大小为 C ∗ C C*C C∗C,最后的加权参数为 β \beta β也是可学习的,得到的attention map上的点 s j i s_{ji} sji表示 j j j通道对 i i i的影响。不做赘述。下面为流程图
2.2.3 代码实现
CAM:
def hw_flatten(x):
return K.reshape(x, shape=[K.shape(x)[0], K.shape(x)[1]*K.shape(x)[2], K.shape(x)[3]])
def cam(x):
f = hw_flatten(x) # [bs, h*w, c]
g = hw_flatten(x) # [bs, h*w, c]
h = hw_flatten(x) # [bs, h*w, c]
s = K.batch_dot(K.permute_dimensions(hw_flatten(g), (0, 2, 1)), hw_flatten(f))
beta = K.softmax(s, axis=-1) # attention map
o = K.batch_dot(hw_flatten(h),beta) # [bs, N, C]
o = K.reshape(o, shape=K.shape(x)) # [bs, h, w, C]
x = gamma * o + x
return x
PAM:
def hw_flatten(x):
return K.reshape(x, shape=[K.shape(x)[0], K.shape(x)[1]*K.shape(x)[2], K.shape(x)[3]])
def pam(x):
f = K.conv2d(x, kernel= kernel_f, strides=(1, 1), padding='same') # [bs, h, w, c']
g = K.conv2d(x, kernel= kernel_g, strides=(1, 1), padding='same') # [bs, h, w, c']
h = K.conv2d(x, kernel= kernel_h, strides=(1, 1), padding='same') # [bs, h, w, c]
s = K.batch_dot(hw_flatten(g), K.permute_dimensions(hw_flatten(f), (0, 2, 1))) #[bs, N, N]
beta = K.softmax(s, axis=-1) # attention map
o = K.batch_dot(beta, hw_flatten(h)) # [bs, N, C]
o = K.reshape(o, shape=K.shape(x)) # [bs, h, w, C]
x = gamma * o + x
return x
2.3 CBAM
论文地址:CBAM: Convolutional Block Attention Module
2.3.1 CBAM结构

2.3.1.1 Channel-Wise Attention
通道注意力部分可以从图中看到基本和SEBlock相同,只是加了一个分支Maxpooling,中间共享一个mlp,最后将两部分的输出相加经过sigmoid。
M c ( F ) = σ ( M L P ( A v g P o o l ( F ) ) + M L P ( M a x P o o l ( F ) ) ) = σ ( W 1 ( W 0 ( F a v g c ) ) + W 1 ( W 0 ( F m a x c ) ) ) M_c(F)=\sigma(MLP(AvgPool(F)) + MLP(MaxPool(F)))=\sigma(W_1(W_0(F_{avg}^c))+W_1(W_0(F^c_{max}))) Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=σ(W1(W0(Favgc))+W1(W0(Fmaxc)))
其中 W 0 ∈ R C r ∗ C , W 1 ∈ R C ∗ C r W_0\in R^{\frac{C}{r*C}},W_1\in R^{C*\frac{C}{r}} W0∈Rr∗CC,W1∈RC∗rC表示两层mlp的权重,两个分之共享权重并使用relu激活函数, r r r为中间通道reduction的比例。
2.3.1.2 Spatial Attention Module
空间注意力的结构也简单,使用average pooling和max pooling对输入feature map 在通道层面上进行压缩操作,对输入特征分别在通道维度上做了mean和max操作。最后得到了两个二维的 feature,将其按通道维度拼接在一起得到一个通道数为2的feature map,之后使用一个包含单个卷积核层对其进行卷积操作,要保证最后得到的feature在spatial 维度上与输入的feature map一致。
M c ( F ) = σ ( f 7 ∗ 7 ( [ A v g P o o l ( F ) ; M a x P o o l ( F ) ] ) ) = σ ( F 7 ∗ 7 ( [ F a v g s ; F m a x s ] ) ) M_c(F)=\sigma(f^{7*7}([AvgPool(F);MaxPool(F)]))=\sigma(F^{7*7([F^s_{avg};F_{max}^s])}) Mc(F)=σ(f7∗7([AvgPool(F);MaxPool(F)]))=σ(F7∗7([Favgs;Fmaxs]))
可视化:
σ \sigma σ表示sigmoid函数, f 7 ∗ 7 f^{7*7} f7∗7表示 7 ∗ 7 7*7 7∗7卷积核, F a v g s ∈ R 1 ∗ H ∗ W F_{avg}^s \in R^{1*H*W} Favgs∈R1∗H∗W和 F m a x s ∈ R 1 ∗ H ∗ W F_{max}^s \in R^{1*H*W} Fmaxs∈R1∗H∗W表示经过通道维度上的maxpooling和avgpooling操作的结果。
2.3.2 代码实现
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
2.4 Attention Gate
论文地址:Attention U-Net:Learning Where to Look for the Pancreas
Attention Gate是作者根据Disan: Directional self-attention network for rnn/cnn-free language understanding实现的一个类似于低纬度fature和高纬度feature融合得到比较可靠的attention map的attention结构。Attention Gate的结构比较简单,建议看论文时候不要看作者的解释感觉太绕了,建议先看源码再看论文会清晰很多。大概说一下和其他attention不同的是支出之处主要是在生成attention map时引用了低层feature和高层feature,处理方式也很简单先经过1*1卷积核进行通道调整然后相加,之后的处理和普通的attention方法完全相同。
2.4.2 代码实现

class Attention_block(nn.Module):
def __init__(self,F_g,F_l,F_int):
super(Attention_block,self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self,g,x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1+x1)
psi = self.psi(psi)
return x*psi
2.5 Criss-Cross Attention
论文地址:CCNet: Criss-Cross Attention for Semantic Segmentation
Criss-Cross Attention可以认为是PAM(Position Attention Module)的改进版本,相对于PAM拥有更少的参数量,思想是单个Attention map只计算当前点对同行,同列的点的响应,然后使用两次Attention就可以解决无法达到边角的问题,既能保证性能,又能减少参数。
2.5.1 Criss-Cross Attention
Criss-Cross Attention模块的结构如下所示,输入feature为 H ∈ R C ∗ W ∗ H H\in \mathbb{R}^{C*W*H} H∈RC∗W∗H, H H H分为 Q , K , V Q,K,V Q,K,V三个分支,都通过1*1的卷积网络的进行降维得到 Q , K ∈ R C ′ ∗ W ∗ H {Q,K}\in \mathbb{R}^{C^{'}*W*H} Q,K∈RC′∗W∗H( C ′ < C C^{'}
d i , u = Q u Ω i , u T d_{i,u}=Q_u\Omega_{i,u}^{T} di,u=QuΩi,uT
其中 Q u ∈ R C ′ Q_u\in\mathbb{R}^{C^{'}} Qu∈RC′是在特征图Q的空间维度上的u位置的值。 Ω u ∈ R ( H + W − 1 ) C ′ \Omega_u\in\mathbb{R}^{(H+W-1)C^{'}} Ωu∈R(H+W−1)C′是 K K K上 u u u位置处的同列和同行的元素的集合。因此, Ω u , i ∈ R C ′ \Omega_{u,i}\in\mathbb{R}^{C^{'}} Ωu,i∈RC′是 Ω u \Omega_u Ωu中的第 i i i个元素,其中 i = [ 1 , 2 , . . . , ∣ Ω u ∣ ] i=[1,2,...,|\Omega_u|] i=[1,2,...,∣Ωu∣]。而 d i , u ∈ D d_{i,u}\in D di,u∈D表示 Q u Q_u Qu和 Ω i , u \Omega_{i,u} Ωi,u之间的联系的权重, D ∈ R ( H + W − 1 ) ∗ W ∗ H D\in \mathbb{R}^{(H+W-1)*W*H} D∈R(H+W−1)∗W∗H。最后对 D D D进行在通道维度上继续进行softmax操作计算Attention Map A A A。
另一个分支 V V V经过一个1*1卷积层得到 V ∈ R C ∗ W ∗ H V \in \mathbb{R}^{C*W*H} V∈RC∗W∗H的适应性特征。同样定义 V u ∈ R C V_u \in \mathbb{R}^C Vu∈RC和 Φ u ∈ R ( H + W − 1 ) ∗ C \Phi_u\in \mathbb{R}^{(H+W-1)*C} Φu∈R(H+W−1)∗C, Φ u \Phi_u Φu是 V V V上u点的同行同列的集合,则定义Aggregation操作为:
H u ′ ∑ i ∈ ∣ Φ u ∣ A i , u Φ i , u + H u H_u^{'}\sum_{i \in |\Phi_u|}{A_{i,u}\Phi_{i,u}+H_u} Hu′i∈∣Φu∣∑Ai,uΦi,u+Hu
该操作在保留原有feature的同时使用经过attention处理过的feature来保全feature的语义性质。

2.5.2 Recurrent Criss-Cross Attention
单个Criss-Cross Attention模块能够提取更好的上下文信息,但是下图所示,根据criss-cross attention模块的计算方式左边右上角蓝色的点只能够计算到和其同列同行的关联关系,也就是说相应的语义信息的传播无法到达左下角的点,因此再添加一个Criss-Cross Attention模块可以将该语义信息传递到之前无法传递到的点。
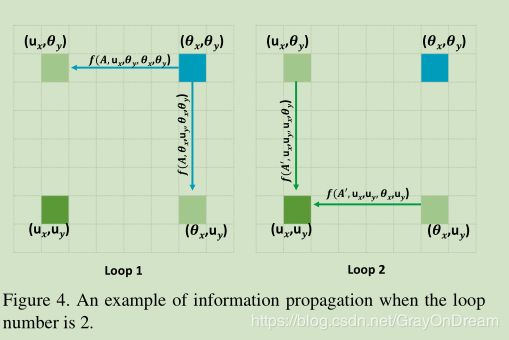
采用Recurrent Criss-Cross Attention之后,先定义loop=2,第一个loop的attention map为 A A A,第二个loop的attention map为 A ′ A^{'} A′,从原feature上位置 x ′ , y ′ x^{'},y^{'} x′,y′到权重 A i , x , y A_{i,x,y} Ai,x,y的映射函数为 A i , x , y = f ( A , x , y , x ′ , y ′ ) A_{i,x,y}=f(A,x,y,x^{'},y^{'}) Ai,x,y=f(A,x,y,x′,y′),feature H H H中的位置用 θ \theta θ表示,feature中 H ′ ′ H^{''} H′′用 u u u表示,如果 u u u和 θ \theta θ相同则:
H u ′ ′ ← [ f ( A , u , θ ) + 1 ] ⋅ f ( A ′ , u , θ ) ⋅ H θ H_u^{''}\leftarrow[f(A,u,\theta)+1]\cdot f(A^{'},u,\theta)\cdot H_{\theta} Hu′′←[f(A,u,θ)+1]⋅f(A′,u,θ)⋅Hθ
其中 ← \leftarrow ←表示加到操作,如果 u u u和 θ \theta θ不同则:
H u ′ ′ ← [ f ( A , u x , θ y , θ x , θ y ) ⋅ f ( A ′ , u x , u y , u x , θ y ) + f ( A , θ x , u y , θ x , θ y ) ⋅ f ( A ′ , u x , u y , θ x , θ y ) ] ⋅ H θ H_u^{''}\leftarrow[f(A,u_x,\theta_{y}, \theta_{x}, \theta_{y})\cdot f(A^{'},u_x,u_{y}, u_{x}, \theta_{y})+f(A,\theta_x,u_{y}, \theta_{x}, \theta_{y})\cdot f(A^{'},u_x,u_{y}, \theta_{x}, \theta_{y})]\cdot H_{\theta} Hu′′←[f(A,ux,θy,θx,θy)⋅f(A′,ux,uy,ux,θy)+f(A,θx,uy,θx,θy)⋅f(A′,ux,uy,θx,θy)]⋅Hθ
Cirss-Cross Attention模块可以应用于多种任务不仅仅是语义分割,作者同样在多种任务中使用了该模块,可以参考论文。

2.6 Point-wise Spatial Attention
论文地址:PSANet: Point-wise Spatial Attention Network for Scene Parsing
2.6.1 Bi-Direction
一般情况下将单个feature上的点和其他点之间的关系通过如下公式计算得到有效feature:
z i = 1 N ∑ ∀ j ∈ Ω ( i ) F ( x i , x j , △ i j ) x j z_i=\frac{1}{N}\sum_{\forall j\in \Omega(i)}F(x_i,x_j,\triangle_{ij})x_j zi=N1∀j∈Ω(i)∑F(xi,xj,△ij)xj
其中 z i z_i zi是整合之后的feature位置 i i i的值, x i x_i xi表示输入fearure在 i i i的值 ∀ j ∈ Ω ( i ) \forall j\in \Omega(i) ∀j∈Ω(i)表示feature中所有和 i i i位置相关的点, △ i j \triangle_{ij} △ij表示位置 i i i和 j j j之间的相对位置。 F ( x i , x j , △ i j ) F(x_i,x_j,\triangle_{ij}) F(xi,xj,△ij)表示学习到的点与点之间的相关关系。
对上式进行简化可以得到:
z i = 1 N ∑ ∀ j ∈ Ω ( i ) F △ i j ( x i , x j ) x j z_i=\frac{1}{N}\sum_{\forall j\in \Omega(i)}F_{\triangle_{ij}}(x_i,x_j)x_j zi=N1∀j∈Ω(i)∑F△ij(xi,xj)xj
其中 F △ i j F_{\triangle_{ij}} F△ij表示一些列的位置相关函数或映射。如果按照上面的公式计算计算量将会非常大,因此进一步简化公式:
F △ i j ( x i , x j ) ≈ F △ i j ( x i ) ⇒ z i = 1 N ∑ ∀ j ∈ Ω ( i ) F △ i j ( x i ) x j F_{\triangle_{ij}}(x_i,x_j)\thickapprox F_{\triangle_{ij}}(x_i) \Rightarrow z_i=\frac{1}{N}\sum_{\forall j\in \Omega(i)}F_{\triangle_{ij}}(x_i)x_j F△ij(xi,xj)≈F△ij(xi)⇒zi=N1∀j∈Ω(i)∑F△ij(xi)xj
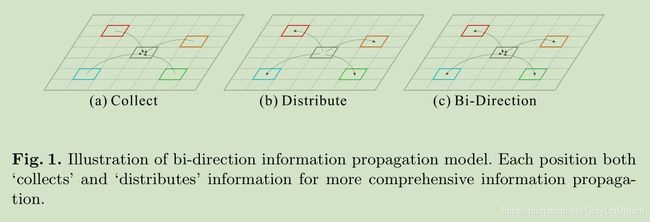
上面的式子表示所有点对点 i i i的影响,相对的 i i i也对其他点施加影响,因此:
F △ i j ( x i , x j ) ≈ F △ i j ( x i ) + F △ i j ( x j ) ⇒ z i = 1 N ∑ ∀ j ∈ Ω ( i ) F △ i j ( x i ) x j + 1 N ∑ ∀ j ∈ Ω ( i ) F △ i j ( x j ) x j ⇒ z i = 1 N ∑ ∀ j a i , j c x j + 1 N ∑ ∀ j a i , j d x j \begin{aligned} & F_{\triangle_{ij}}(x_i,x_j) \thickapprox F_{\triangle_{ij}}(x_i) + F_{\triangle_{ij}}(x_j) \\ \Rightarrow &z_i = \frac{1}{N}\sum_{\forall j\in \Omega(i)}F_{\triangle_{ij}}(x_i)x_j+\frac{1}{N}\sum_{\forall j\in \Omega(i)}F_{\triangle_{ij}}(x_j)x_j \\ \Rightarrow &z_i=\frac{1}{N}\sum_{\forall j}\mathrm{a}^c_{i,j}\mathrm{x}_j+\frac{1}{N}\sum_{\forall j}\mathrm{a}^d_{i,j}\mathrm{x}_j \end{aligned} ⇒⇒F△ij(xi,xj)≈F△ij(xi)+F△ij(xj)zi=N1∀j∈Ω(i)∑F△ij(xi)xj+N1∀j∈Ω(i)∑F△ij(xj)xjzi=N1∀j∑ai,jcxj+N1∀j∑ai,jdxj
其中 a i , j c \mathrm{a}^c_{i,j} ai,jc和 d i , j c \mathrm{d}^c_{i,j} di,jc表示collect和distribute两个分支的attention map A c A^c Ac和 A d A^d Ad中的值。
2.6.2 Point-Wise Spatial Attention Module
PSAM的结构很清晰如下图,该模块分为两个分支:Collect和Distribution。两个分支的基本结构基本相同:输入 X ∈ R H ∗ W ∗ C X\in \mathbb{R}^{H*W*C} X∈RH∗W∗C,经过1*1卷积核进行降维得到 X ∈ R H ∗ W ∗ C 1 , ( C 1 < C ) X\in \mathbb{R}^{H*W*C_1},(C_1 < C) X∈RH∗W∗C1,(C1<C),然后一个由1*1卷积和BN层、激活层组成的卷积层进行特征自适应得到 H ∈ R H ∗ W ∗ ( 2 H − 1 ) ∗ ( 2 W − 1 ) H\in \mathbb{R}^{H*W*(2H-1)*(2W-1)} H∈RH∗W∗(2H−1)∗(2W−1),然后经过Attention模块得到Attention map A ∈ R H ∗ W ∗ C A\in\mathbb{R}^{H*W*C} A∈RH∗W∗C和原feature融合得到各自的 Z c Z^c Zc和 Z d Z^d Zd之后经过concat和原feature融合得到最终的结果。

2.6.3 Point-Wise Spatial Attention
结构在上一节基本解释清楚主要说一下这里的通道数是 ( 2 H − 1 ) ( 2 W − 1 ) (2H-1)(2W-1) (2H−1)(2W−1)的原因是对该tensor进行reshape之后可以使得feature上每个点都能够在保证自身处于中心的情况下获取其他点的影响,如下图所示:
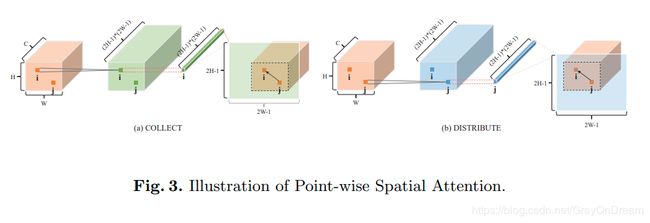
对于特征图生成 i i i位置即 ( k , l ) (k,l) (k,l)在Attention上的区域是从 [ H − k , W − l ] [H-k, W-l] [H−k,W−l]开始的大小为 H ∗ W H*W H∗W的区域:
a [ k , l ] , [ s , t ] c = h [ k , l ] , [ H − k + s , W − l + t ] c , ∀ s ∈ [ 0 , H ) , t ∈ [ 0 , W ) \mathrm{a}^c_{[k,l],[s,t]}=\mathrm{h}^c_{[k,l],[H-k+s,W-l+t]},\forall s\in[0,H),t\in [0,W) a[k,l],[s,t]c=h[k,l],[H−k+s,W−l+t]c,∀s∈[0,H),t∈[0,W)
a \mathrm{a} a表示Attention Map, h \mathrm{h} h表示输入。
另外说一句,两个模块实现本质上差不多,唯一的区别是最后得到的attention map之前的feature是如何取到的,collect是将其他点的响应收集到目标点,distribution是将当前点分发给其他点,带着这样的想法看下C++源码就可以理解了。
2.6.4 代码
从上面的配置文件看网络的机构基本相同都是两个1*1卷积核接一个attention模块,不同之处为attention的实现方式:
switch (this->layer_param_.pointwise_spatial_attention_param().psa_type()) {
case PointwiseSpatialAttentionParameter_PSAType_COLLECT:
PSAForward_buffer_mask_collect_cpu<Dtype>(num_, feature_H_, feature_W_,
mask_H_, mask_W_, half_mask_H_, half_mask_W_,
bottom[1]->cpu_data(), mask_buffer_.mutable_cpu_data());
break;
case PointwiseSpatialAttentionParameter_PSAType_DISTRIBUTE:
PSAForward_buffer_mask_distribute_cpu<Dtype>(num_, feature_H_, feature_W_,
mask_H_, mask_W_, half_mask_H_, half_mask_W_,
bottom[1]->cpu_data(), mask_buffer_.mutable_cpu_data());
break;
default:
LOG(FATAL) << "Unknown PSA type.";
}
Collect:
template <typename Dtype>
void PSAForward_buffer_mask_collect_cpu(const int num_,
const int feature_H_, const int feature_W_,
const int mask_H_, const int mask_W_,
const int half_mask_H_, const int half_mask_W_,
const Dtype* mask_data, Dtype* buffer_data) {
for(int n = 0; n < num_; n++) {
for(int h = 0; h < feature_H_; h++) {
for(int w = 0; w < feature_W_; w++) {
// effective mask region : [hstart, hend) x [wstart, wend) with mask-indexed
const int hstart = max(0, half_mask_H_ - h);
const int hend = min(mask_H_, feature_H_ + half_mask_H_ - h);
const int wstart = max(0, half_mask_W_ - w);
const int wend = min(mask_W_, feature_W_ + half_mask_W_ - w);
// (hidx, widx ) with mask-indexed
// (hidx + h - half_mask_H_, widx + w - half_mask_W_) with feature-indexed
for (int hidx = hstart; hidx < hend; hidx++) {
for (int widx = wstart; widx < wend; widx++) {
buffer_data[(n * feature_H_ * feature_W_ + (hidx + h - half_mask_H_) * feature_W_ + (widx + w - half_mask_W_)) * feature_H_ * feature_W_ + h * feature_W_ + w] =
mask_data[((n * mask_H_ * mask_W_ + hidx * mask_W_ + widx) * feature_H_ + h) * feature_W_ + w];
}
}
}
}
}
}
Distribution:
template <typename Dtype>
void PSAForward_buffer_mask_distribute_cpu(const int num_,
const int feature_H_, const int feature_W_,
const int mask_H_, const int mask_W_,
const int half_mask_H_, const int half_mask_W_,
const Dtype* mask_data, Dtype* buffer_data) {
for(int n = 0; n < num_; n++) {
for(int h = 0; h < feature_H_; h++) {
for(int w = 0; w < feature_W_; w++) {
// effective mask region : [hstart, hend) x [wstart, wend) with mask-indexed
const int hstart = max(0, half_mask_H_ - h);
const int hend = min(mask_H_, feature_H_ + half_mask_H_ - h);
const int wstart = max(0, half_mask_W_ - w);
const int wend = min(mask_W_, feature_W_ + half_mask_W_ - w);
// (hidx, widx ) with mask-indexed
// (hidx + h - half_mask_H_, widx + w - half_mask_W_) with feature-indexed
for (int hidx = hstart; hidx < hend; hidx++) {
for (int widx = wstart; widx < wend; widx++) {
buffer_data[(n * feature_H_ * feature_W_ + h * feature_W_ + w) * feature_H_ * feature_W_ + (hidx + h - half_mask_H_) * feature_W_ + (widx + w - half_mask_W_)] =
mask_data[((n * mask_H_ * mask_W_ + hidx * mask_W_ + widx) * feature_H_ + h) * feature_W_ + w];
}
}
}
}
}
}
唯一的区别就是这里:
buffer_data[(n * feature_H_ * feature_W_ + (hidx + h - half_mask_H_) * feature_W_ + (widx + w - half_mask_W_)) * feature_H_ * feature_W_ + h * feature_W_ + w] =
mask_data[((n * mask_H_ * mask_W_ + hidx * mask_W_ + widx) * feature_H_ + h) * feature_W_ + w];
buffer_data[(n * feature_H_ * feature_W_ + h * feature_W_ + w) * feature_H_ * feature_W_ + (hidx + h - half_mask_H_) * feature_W_ + (widx + w - half_mask_W_)] =
mask_data[((n * mask_H_ * mask_W_ + hidx * mask_W_ + widx) * feature_H_ + h) * feature_W_ + w];
图中第一项实在相同的feautre中索引不同的位置,第二项实在不同的feature中索引相同的位置。
![]()
第一行是索引相同通道上的某个点,第二个是索引具体某个通道。