【leveldb】SSTable(十三):Filter Block
上一篇主要介绍了DataBlock,本篇则开始讲解Filter Block,其在SSTable中的结构可点此链接SSTable结构说明。
Filter Block中存的都是Data Block中的key(key是经过处理再存入到FilterBlock中),其作用就是提高SSTable的读取效率。当查询一个key时,可以快速定位这个key是否在当前SSTable中,其流程是当进行一个key查询时,先通过index block中的二分法确定key在哪个Data Block中,取出这个Data Block的offset,凭借这个Offset和要查询的key去Filter Block中去查找确定,若判断不存在,则无需对这个DataBlock进行数据查找。这里为便于理解展示下FilterBlock的结构:
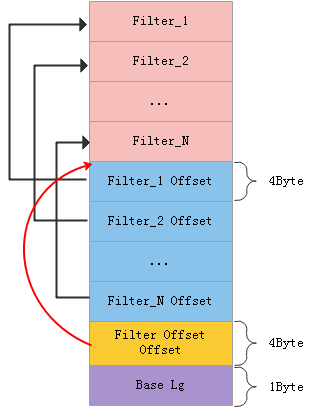
图1
Filter_Block.h
namespace leveldb {
<!过滤策略基类>
class FilterPolicy;
// A FilterBlockBuilder is used to construct all of the filters for a
// particular Table. It generates a single string which is stored as
// a special block in the Table.
//
// The sequence of calls to FilterBlockBuilder must match the regexp:
// (StartBlock AddKey*)* Finish
class FilterBlockBuilder {
public:
explicit FilterBlockBuilder(const FilterPolicy*);
FilterBlockBuilder(const FilterBlockBuilder&) = delete;
FilterBlockBuilder& operator=(const FilterBlockBuilder&) = delete;
<!是否要新起一个Fileter>
void StartBlock(uint64_t block_offset);
<!往Filter中添加key>
void AddKey(const Slice& key);
<!完成当前Filter Block的数据状态>
Slice Finish();
private:
<!产生一个Filter>
void GenerateFilter();
const FilterPolicy* policy_;
<!追加保存用于产生Filter的key>
std::string keys_; // Flattened key contents
<!存储keys_中每个key的offset>
std::vector<size_t> start_; // Starting index in keys_ of each key
<!用于存放Filter Block的存储体>
std::string result_; // Filter data computed so far
<用于产生Filter的临时key结构>
std::vector<Slice> tmp_keys_; // policy_->CreateFilter() argument
<!保存每个Filter中当前Filter Block中的偏移位>
std::vector<uint32_t> filter_offsets_;
};
<!读取Filter Block类>
class FilterBlockReader {
public:
<!创建一个用于读取Filter Block的实体>
// REQUIRES: "contents" and *policy must stay live while *this is live.
FilterBlockReader(const FilterPolicy* policy, const Slice& contents);
<!判断当前Filter Block是否存在Key>
bool KeyMayMatch(uint64_t block_offset, const Slice& key);
private:
const FilterPolicy* policy_;
<!指向Filter Block的数据首地址>
const char* data_; // Pointer to filter data (at block-start)
<!Filter Offset数组的起始偏移>
const char* offset_; // Pointer to beginning of offset array (at block-end)
<!Filter Offset个数>
size_t num_; // Number of entries in offset array
<!Filter Block结束标志,也用于表示每个Filter的大小>
size_t base_lg_; // Encoding parameter (see kFilterBaseLg in .cc file)
};
} // namespace leveldb
Filter_Block.cc
namespace leveldb {
// See doc/table_format.md for an explanation of the filter block format.
<!每个Filter是2BK左右>
// Generate new filter every 2KB of data
static const size_t kFilterBaseLg = 11;
static const size_t kFilterBase = 1 << kFilterBaseLg;
<!构造一个FilterBlockBuilder,用于按照FilterBlock格式去生存FilterBlock,
这里要传一个过滤策略进去,用于生存Filter和过滤检查Key时使用。
>
FilterBlockBuilder::FilterBlockBuilder(const FilterPolicy* policy)
: policy_(policy) {}
<!根据Data Block在SSTable中的偏移位block_offset来判定要不要新生存一个Filter,
若要生存Filter,则由GenerateFilter()去生成。
>
void FilterBlockBuilder::StartBlock(uint64_t block_offset) {
uint64_t filter_index = (block_offset / kFilterBase);
assert(filter_index >= filter_offsets_.size());
while (filter_index > filter_offsets_.size()) {
GenerateFilter();
}
}
<!往FilterBlock中添加一个key,
1.start_是个vector类型,其主要存储每个key的大小,其实就是偏移位,根据这个偏移位
就可以去keys_中找到这个key。
2.keys_是个string类型,所有的key都追加添加进去。
当用start_和keys_生成完一个Filter之后,就将二者清空。
>
void FilterBlockBuilder::AddKey(const Slice& key) {
Slice k = key;
start_.push_back(keys_.size());
keys_.append(k.data(), k.size());
}
<!当SSTable要写FilterBlock时,则调用此Finish(),
Finish()就是完成FilterBlock格式的封装。
参照FilterBlock的格式,就很容易明白此方法的流程了。
>
Slice FilterBlockBuilder::Finish() {
<!当前start_存有key size,则需要新生存一个Filter>
if (!start_.empty()) {
GenerateFilter();
}
<!此刻restlt中存的都是Filter,然后将filter offset追加到后面>
// Append array of per-filter offsets
const uint32_t array_offset = result_.size();
for (size_t i = 0; i < filter_offsets_.size(); i++) {
PutFixed32(&result_, filter_offsets_[i]);
}
<!此刻result中存的是Filter、filter offset,
此时将filter offset这个数组的起始偏移位array_offset
写入result。
>
PutFixed32(&result_, array_offset);
<!走到此步,只需在尾部添加一个标志“11”,则完成了整个FilterBlock>
result_.push_back(kFilterBaseLg); // Save encoding parameter in result
return Slice(result_);
}
<!生成一个Filter>
void FilterBlockBuilder::GenerateFilter() {
<!获取当前有多少key用于生存Filter>
const size_t num_keys = start_.size();
if (num_keys == 0) {
<!如果key个数为0,那新添加的filter_offset指向当前
最后一个Filter尾部,也是下一个Filter的起始处
(不一定有下一个Filter了)
>
// Fast path if there are no keys for this filter
filter_offsets_.push_back(result_.size());
return;
}
<!下文在将key放到tmp_keys_中时,求key的长度都是后一起i+1 - 前一个i,
为了能计算最后一个key的长度,所以这里要把整个key的长度再次放入到
vector类型start_中。
>
// Make list of keys from flattened key structure
start_.push_back(keys_.size()); // Simplify length computation
<!这里就是将key封装为Slice,放入到tmp_keys_中用于计算Filter>
tmp_keys_.resize(num_keys);
for (size_t i = 0; i < num_keys; i++) {
const char* base = keys_.data() + start_[i];
size_t length = start_[i + 1] - start_[i];
tmp_keys_[i] = Slice(base, length);
}
<!新Filter的起始偏移位就是当前已存在Filter大小,
起始这里往filter_offset中存的就是
新Filter的起始偏移位。
>
// Generate filter for current set of keys and append to result_.
filter_offsets_.push_back(result_.size());
<!按照过滤策略生存Filter,并存于result_中>
policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
<!清空用于生存Filter的临时变量>
tmp_keys_.clear();
keys_.clear();
start_.clear();
}
<!构造一个解析FilterBlock的类,其实就是按FilterBlock的格式去解析>
FilterBlockReader::FilterBlockReader(const FilterPolicy* policy,
const Slice& contents)
: policy_(policy), data_(nullptr), offset_(nullptr), num_(0), base_lg_(0) {
size_t n = contents.size();
if (n < 5) return; // 1 byte for base_lg_ and 4 for start of offset array
base_lg_ = contents[n - 1];
<!整个last_word就是FilterBlock中的Filter_N Offset,
即Filter Offset数组在FilterBlock中的偏移位。
>
uint32_t last_word = DecodeFixed32(contents.data() + n - 5);
if (last_word > n - 5) return;
data_ = contents.data();
offset_ = data_ + last_word; //Filter Offset数组的起始偏移,实际地址
num_ = (n - 5 - last_word) / 4; //Filter Offset个数
}
<!匹配key是否在block_offset对应的Filter中>
bool FilterBlockReader::KeyMayMatch(uint64_t block_offset, const Slice& key) {
<!通过block_offset算出整个key应该在哪个Filter中去查找>
uint64_t index = block_offset >> base_lg_;
<!这里如果index 大于最大的Filter offset个数,
这里还是会返回true,默认匹配。实际去DataBlock中去定位查找。
>
if (index < num_) {
<!Filter Offset都是4Byte大小的,所以这里都是*4。
start是这个Filter在FilterBlock中的起始偏移位,
limit就是这个Filter的大小。
>
uint32_t start = DecodeFixed32(offset_ + index * 4);
uint32_t limit = DecodeFixed32(offset_ + index * 4 + 4);
if (start <= limit && limit <= static_cast<size_t>(offset_ - data_)) {
<!将Filter封装到Slice中,通过过滤策略内部实现去查找确定是否有对应的key>
Slice filter = Slice(data_ + start, limit - start);
return policy_->KeyMayMatch(key, filter);
} else if (start == limit) {
<!如果start == limit,表示不存在这个Filter,所以肯定不存在匹配>
// Empty filters do not match any keys
return false;
}
}
return true; // Errors are treated as potential matches
}
} // namespace leveldb
总结
至于FilterBlock中用到的过滤策略FilterPolicy,这里不做讲解,后续文章会介绍。