Python爬虫笔记:Scrapy框架
目录
- 1、Scrapy框架安装与运行原理
- 2、框架的命令介绍
- 2.1 全局命令
- 2.2 项目命令
- 3、创建工程
- 模块详解
- I. Spider
- II. ItemPipeline
- 数据保存
- 项目实践
1、Scrapy框架安装与运行原理
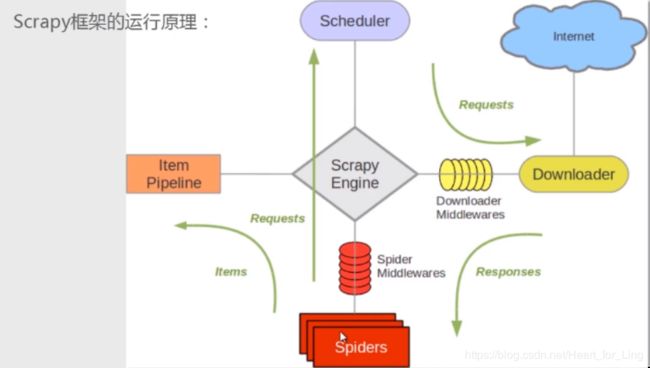
引擎是核心,将请求发送到进程Schedule,进程将之交给下载器从互联网获取请求,得到responses返回给spider,一个项目下的spider可以有多个。
spider的功能是执行爬取动作,然后解析响应,得到数据或者新的url,然后将数据递交给Item Pipeline或是将url递交给Schedule。
Item Pipeline则进行数据的清洗,补充与保存。
——————
scrapy框架的安装:pip install scrapy
2、框架的命令介绍
Scrapy 命令分为两种:全局命令(使用scrapy –h可以查看) 和项目命令
- 全局命令:在哪里都能使用。
- 项目命令:只能在爬虫项目里面使用。
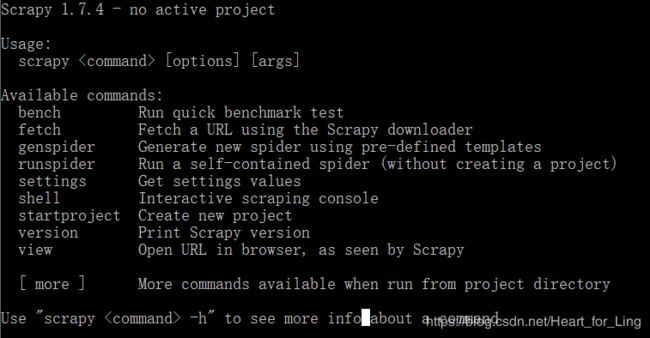
打开命令行(这里可以Win+R:打开运行;输入cmd来打开命令行),输入scrapy:
2.1 全局命令
以下是全局命令:
'''
Usage:
scrapy [options] [args] #用法:命令 选项 参数
Available commands:
bench Run quick benchmark test
#运行快速基准测试
fetch Fetch a URL using the Scrapy downloader
#使用scrapy下载器获取URL的内容
genspider Generate new spider using pre-defined templates
#使用预设置模板生成新的爬虫
runspider Run a self-contained spider (without creating a project)
#无需创建项目的情况下。运行一个独立的爬虫
settings Get settings values
#获取配置信息
shell Interactive scraping console
#互动式爬取控制台,用于临时的交互的爬虫操作
startproject Create new project
#创建一个新爬虫项目
version Print Scrapy version
#获得scrapy的版本
view Open URL in browser, as seen by Scrapy
#使用Scrapy下载器获取URL并在浏览器中显示其内容
[ more ] More commands available when run from project directory
'''
命令行输入"scrapy -h"以获取命令的详细信息
2.2 项目命令
项目命令的详细必须进入项目后执行:scrapy -h结果如下:许多命令与全局命令重复,重点补充不重复的命令。
Available commands:
bench Run quick benchmark test
check Check spider contracts
crawl Run a spider
#执行爬虫 接爬虫名称
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
#显示当前项目下的所有爬虫名称
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
Use "scrapy -h" to see more info about a command
3、创建工程
D:\python\Python37\Practise>cd scrapy
D:\python\Python37\Practise\Scrapy>scrapy startproject demo
D:\python\Python37\Practise\Scrapy_inn>cd demo
D:\python\Python37\Practise\Scrapy_inn\demo>scrapy genspider fang fang.5i5j.com
Created spider ‘fang’ using template ‘basic’ in module:
demo.spiders.fang
在scrapy文件夹下创建好了demo项目:

- demo 项目
- spiders 爬虫主体
- __init__.py 配置文件
- items.py 定义数据结构
- middlewares.py
- pipelines.py 定义数据管道
- settings.py 项目全局配置
- scrapy.cfg scrapy部署时的配置文件
这样得到的爬虫主体 fang.py:
# -*- coding: utf-8 -*-
import scrapy
class FangSpider(scrapy.Spider):
name = 'fang'
allowed_domains = ['fang.5i5j.com']
start_urls = ['https://fang.5i5j.com']
def parse(self, response):
pass
模块详解
I. Spider
• 在Scrapy中抓取网站的链接配置、抓取逻辑、解析逻辑里都是在Spider中配置的。
• Spider要做的事就是有两件:定义抓取网站的动作 和 分析爬取下来的网页。
——
• 对应Spider类,整个抓取循环过程如下所述:
- 以初始URL初始化Request,并设置回调函数。请求成功时得到Response并作为参数传给该回调函数。
- 在回调函数内分析返回的Response。得到两种形式:一种为字典或Item数据对象;另 一种是解析到下一个链接。
- 然后将解析到的内容
yield传递出去。 - 如果返回的是字典或Item对象,我们可以将结果存入文件,也可以使用Pipeline处理并保存
- 如果返回Request,则调用
scrapy.Request(url=url,callback=self.parse)。#传入url,并设置回调函数
——
Spider类分析:基类
• Spider类继承自scrapy.spiders.Spider.
• Spider类这个提供了start_requests()方法的默认实现,读取并请求start_urls属性,并调用parse()方法解析结果。
——
- Spider类的属性和方法:
- name:爬虫名称,必须唯一,但是一个项目下可以有多个爬虫,数量没有限制。
- allowed_domains: 允许爬取的域名,是可选配置,不在此范围的链接不会被跟进爬取。
- start_urls: 它是起始URL列表,当我们没有实现
start_requests()方法时,默认会从这个列表开 始抓取。 - custom_settings: 它是一个字典,专属于Spider的配置,此设置会覆盖项目全局的设置,必须 定义成类变量。
- crawler:它是由
from_crawler()方法设置的,Crawler对象包含了很多项目组件,可以获取 settings等配置信息。 - settings: 利用它我们可以直接获取项目的全局设置变量。
- start_requests(): 使用start_urls里面的URL来构造Request,而且Request是GET请求方法。
- parse(): 当Response没有指定回调函数时,该方法会默认被调用。
- closed(): 当Spider关闭时,该方法会调用
————
————
爬虫是在命令行执行的。命令行会显示执行的细节。
执行爬虫时首先得到相应,值为200正常,之后scrapy会访问robots.txt,如果协议拒绝爬虫访问,那么就会抛出异常,结束访问。
解决方法:打开项目下的settings,找到ROBOTSTXT_OBEY将之修改为False即可。
但是这样得到的爬虫数据是禁止商业使用的,否则会发生法律纠纷。
——
解析出来的url通过response.urljoin(url)来构建绝对地址。
II. ItemPipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件按照 一定的顺序 执行对Item的处理。
每个item pipeline组件是实现了简单方法的 Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
——
以下是item pipeline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- *查重(并丢弃) *
- 将爬取结果保存到数据库中
————
————
每个item pipiline组件是一个独立的 Python类,同时必须实现以下方法:
- process_item(item, spider) 必须
每个item pipeline都会调用该方法,且必须返回item或抛出Dropitem异常,返回异常则之后的item pipeline不会再操作这个item。spider是爬取这个item的爬虫 - open_spider(spider) 可选
当爬虫被调用时执行该方法 - close_spider(spider) 可选
当爬虫结束调用时执行该方法,这两个方法适用于保存数据时的打开和关闭数据库。
————
————
当需要封装数据时,需要先修改项目下的items.py文件,我们创建的item类是继承自scrapy.Item。
封装的数据的格式如name=scrapy.Field(),有多少类数据需要封装就创建多少条目。
数据保存
item pipeline执行数据保存框架:
import pymysql
def open_spider(self,spider):
self.db=pymysql.connect(self.host,self.user,self.password,self.database,self.port,charset="utf8")
self.cursor=self.db.cursor()
def process_item(self,item,spider):
#这里的csdnedu是表名
sql="insert into csdnedu(title,url,pic,teacher,time,price) value(%s,%s,%s,%s,%s,%s)"%()
self.cursor.execute(sql)
self.db.commit()
return item
def close_spider(self,spider):
self.db.close()
————
————
那么如何连接数据库?在self.db=pymysql.connect()里添加账号密码?事实上项目是会转移的,如果这里写死了参数转移后就需要修改,所以一个好的方法是将数据放在settings里,而连接数据库这里采用模块的写法。
给item pipeline做初始化:
class CsdneduPipeline(object):
def __init__(self,host,user,password,database,port):
self.host=host
self.user = user
self.password = password
self.database = database
self.port = port
@classmethod
def from_crawler(cls,crawler):
return cls(
host=crawler.settings.get("MYSQL_HOST"),
user = crawler.settings.get("MYSQL_USER"),
password = crawler.settings.get("MYSQL_PASSWORD"),
database=crawler.settings.get("MYSQL_DATABASE"),
port=crawler.settings.get("MYSQL_PORT"),
)
给settings做修改:
ITEM_PIPELINES = {
'csdnedu.pipelines.setPipeline': 300,
'csdnedu.pipelines.CsdneduPipeline': 301,
}
MYSQL_HOST="localhost"
MYSQL_DATABASE=""
MYSQL_USER="root"
MYSQL_PASSWORD=""
MYSQL_PORT=""
即可。
项目实践
1、scrapy实践I :csdn学院网课信息