行人重识别CUHK03数据集及MATLAB cell array介绍---史上最全总结
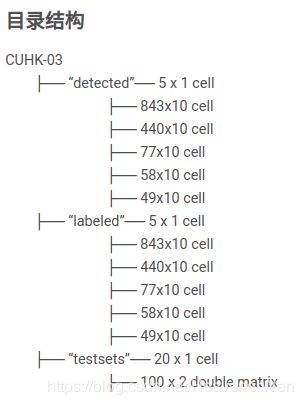
1. 数据集整体描述
该数据集采集于港中文校园,是以MATLAB MAT file的格式来存储的,是收集了1467个identities, 这1467个identities又是收集自5 different pairs of camera views. 5对摄像机,什么意思? 是10个相机? 对的,是10个相机. 5对摄像机(或者也叫5个摄像机组)是有分工的,不是同一个人会路过5对(10个)全部摄像头。a pair of camera 一对摄像机负责收取 M ∗ 10 M*10 M∗10个cells的数据, M M M代表the number of identities.
For each identity, cell 1-5 are images from one camera and cell 6-10 are images from another camera. However, some identities may have less than 10 images. 但是, 有的人10张图像不全有,可能缺一张这种,比如在detected cell里就没有1_003_2_05.png这张图像. 也就是没有编号为5的图像.
那么,每一对里,一个负责干啥,另一个负责干啥?
第一个摄像头拍摄一个人的正面或侧面5张,第二个摄像头也拍摄这个人的5张(一定是与第一个摄像机不同视角的,比如背面),然后也没像人脸一样把他们放到以identity命名的文件夹里。
因为这就是正所谓的一对camera views,一个camera view,另一个不同的camera view,总共只有两个view.
上述图片引用自gmHappy的CSDN博客
在弄清数据是具体怎么组织之前,有必要先介绍下如何理解MATLAB Cell Array,如果您清楚MATLAB Cell Array请忽略这部分内容
1.1 数据的组织形式
由MATLAB读进去Workspace后,我们得到如下组织结构的数据:
- detected 5x1 cell which means the bounding boxes are estimated by pedestrian detector
- labeled 5x1 cell which means the bounding boxes are labeled by human
- testsets 20x1 cell which contains the testing protocols
先说detected:
这个是个5x1的cell, 这个子cell arrary的组织形式如下:
– 843x10 cell 第一个摄像机组,第一对摄像机(pair1)对于843x10这个cell的元素也是cell.
– 440x10 cell 第二个摄像机组,第二对摄像机(pair2)同上
– 77x10 cell 第三个摄像机组,第三对摄像机(pair3)同上
– 58x10 cell 第四个摄像机组,第四对摄像机(pair4)同上
– 49x10 cell 第五个摄像机组,第五对摄像机(pair5)同上
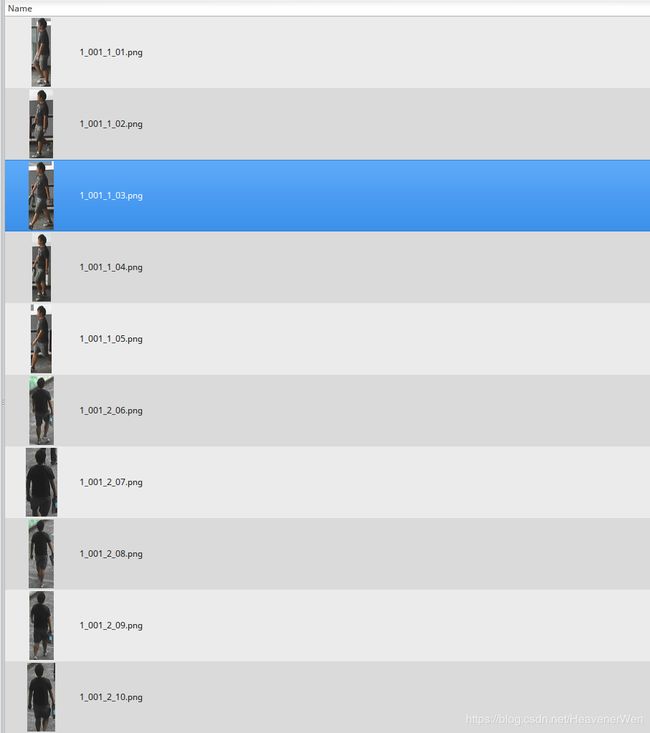
举个例子说明下,图像的命名规则:
- 第一个数字:代表拍摄的摄像机组的编号,这意思是第一组
- 第二个由三个数组成的数据: 代表identity的编号,因为每个摄像机组获得的identity都不会超过843,所以三位数就够了。
- 第三个数字:代表摄像机组里的1号相机或者2号相机
- 第四个数字:代表这个人的第多少张图像,最多10张(从1到10).
%以843x10的cell的元素即子cell为例:
%也就是具体到特定人的特定1/10的具体那张图像
应该不再是cell,而是一个三维数据.
(比如:W×Hx3(从图片看是宽乘以高)(还是HxWx3还得确认下)的数据类型为uint8的不带着boundingbox但是框好的长方形图像)
再说labeled
the bounding boxes are labeled by human. 其数据组织形式(格式)同detected.
再说testsets
测试协议。
-
测试协议1:single-shot setting
具体地说,即随机选出100个行人identity作为测试集,1160个行人identity作为训练集,100个行人identity作为验证集(这里总共1360个行人而不是1467个,这是因为实验中没有用到摄像头组pair 4和5的数据, pair1+pair2+pair3=843+440+77=1360),重复二十次。这种测试协议是single-shot setting.
-
测试协议2:
20 x 1 cells and each contains the identities used for testing. 那么具体的测试用的identities怎么组织的还看100x2的格式.
为了更好的弄明白,到底测试时候的数据是怎么被使用的?
我创建个简单的20x1的数据来进行解释。
c=cell(20,1)
c =
20×1 cell array
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
{0×0 double}
可见,上面为20个0x0 double 类型的矩阵组成的。
同理,由 20 个 100 x 2 double 类型矩阵组成 (重复二十次), 无非就是维度与模拟cell的元素的维度不同而已。
而100 x 2 double,100 行代表 100 个测试样本identity(是specific identity, 具体到哪个相机拍的,哪个人的, 但是具体不到那个人的第几张图片),第 1 列为摄像头 pair 索引(即1,2,3,4,5),第 2 列为行人identity索引(即identity的索引,这个索引的范围还没确定,不过应该不是1467)。
100 x 2 matrix A, where A(i, 1) is the index of camera pair and A(i, 2) is the index of identity.
看看具体都张什么样子呢?
%第一个100x2
A=testsets{1,1}
A =
1 266
1 818
1 787
1 660
1 833
1 624
1 231
1 423
1 588
1 128
1 416
1 65
1 301
1 294
1 300
1 543
1 401
1 120
1 462
1 18
1 236
1 4
1 336
1 274
1 580
1 473
1 360
1 30
1 741
1 749
1 566
1 192
1 144
1 500
1 709
1 83
1 545
1 61
1 252
1 380
1 630
1 331
1 346
1 839
1 98
1 685
1 105
1 535
1 197
1 418
1 325
1 220
1 254
1 173
1 414
1 313
1 601
1 600
1 752
1 142
1 404
1 757
2 28
2 99
2 93
2 432
2 222
2 407
2 394
2 203
2 410
2 397
2 19
2 334
2 286
2 95
2 45
2 32
2 348
2 387
2 126
2 333
2 439
2 111
2 389
2 270
2 267
2 146
2 110
2 299
2 362
2 211
2 147
2 60
3 2
3 17
3 70
3 13
3 43
3 72
然后看看100x2的(1,1)和(1,2):
A(1,1)
ans =
1 %这个1代表pair1
%
A(1,2)
ans =
266 %这个266代表index_identity
2. MATLAB cell 介绍
其实就是MATLAB的Cell array. A cell array is a data type with indexed data containers called cells(具有单元格的数据类型), where each cell can contain any type of data(每个单元格中包含的数据类型又可以不一样). Cell arrays commonly contain either lists of text, combinations of text and numbers, or numeric arrays of different sizes.
Refer to sets of cells by enclosing indices in smooth parentheses, (). Access the contents of cells by indexing with curly braces, {}.
通过将索引括在圆括号()中来引用单元格集合。 通过使用大括号{}进行索引来访问单元格的内容。
2.1 创建一个MATLAB cell 数组
create the array using the cell array construction operator,{}.
先创建一个最简单的0×0 empty cell array
C={}
C=
0x0 empty cell array
可见,{}就是创建cell array用的语法。
C={1,2,3;
'text', rand(5,10,2), {11;22;33}}
在弄清这个Cell Array的维度之前,有必要了解下MATLAB里面semicolon和comma的作用.
x =[1,2,3] % comma 这样的话,就和python创建list时候一样
% creates a 1x3 row vector.
x =
1 2 3
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 而如果是semicolon的情形呢:
x=[1;2;3] %此时创建的列向量而不再是行向量。
% creates a 3x1 column vector
x =
1
2
3
结合上面给出的semicolon和comma的用法
我们知道
- 1,2,3; 代表1,2,3占一行的位置
- ‘text’,rand(5,10,2),{11; 22; 33} 占一行的位置
- 再结合两部分在空间上形成对应,所以确实是2x3 cell array.
因此,得到的2x3 cell array数组如下所示:
C = {1,2,3;
'text',rand(5,10,2),{11; 22; 33}}
C=2×3 cell array
{[ 1]} {[ 2]} {[ 3]}
{'text'} {5x10x2 double} {3x1 cell}
这是2x3 cell array的情形,但是子cell的元素并不是cell而是11 22 33这种单个的数。
在高维图像数据中,我们更关注如果子cell里面的元素还是cell array的情形, 我们假设{3x1 cell}的每个元素又是个2x1的cell array, 所以新的代码应该为:
C ={1,2,3;
'text',rand(5,10,2),{{1;2};{1;2};{1;2}}}
% 这样的话,我们得到:
C =
2×3 cell array
{[ 1]} {[ 2]} {[ 3]}
{'text'} {5×10×2 double} {3×1 cell}
2.2 访问一个MATLAB cell 数组中的元素
但如果我们通过cell array的index来取出这个3x1的cell单独研究的话,我们会得到如下:
- 我们先看Content Indexing with Curly Braces, {}的Case: 用花括号{}进行内容索引的情形
% For example, to access the contents of the last cell of C, use curly braces.
last = C{2,3}
last =
3×1 cell array
{2×1 cell}
{2×1 cell}
{2×1 cell}
3. 跑程序时的打印结果:
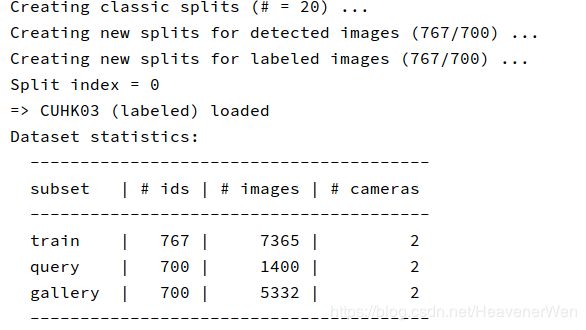
然后,经过DEBUG我们看到,dataset里面的
num_train_pids=767
综上,我们知道,这就是train会用到的number of identities. 所以,在data_manager.py里面的pid指的就是train里面第几个identities.
- train是一组identities很正常
- query也是一组identities而不是一个identity.
- gallery是一组identities这很自然啊。
参考文献
- hyk_1996的CSDN博客
- gmHappy的CSDN博客