【AutoGluon】图像识别与分类实战教程
【AutoGluon】图像识别与分类实战
全网首发实战博客??哈哈哈假的
官方使用指南
AutoGluon背后的原理是什么?—— 推荐阅读:
ProxylessNAS
ENAS
经过研究发现,其实在权重里面,并非所有的参数都是有效的,有些参数去掉了也基本不会影响推理的结果,这就涉及到我们平时说的模型蒸馏,模型压缩。ProxylessNAS和ENAS就是有这样剪枝的技术,AutoGluon中也会提供给我们这样的‘supernet’。
话不多说,开始摸鱼 。
安装与demo使用
AutoGluon requires Python version 3.6 or 3.7. Linux is the only operating system fully supported for now (complete Mac OSX and Windows versions will be available soon).
暂时只有linux版本哦嘻嘻,对python3.5也是不支持的,我们可以用anaconda新建一个3.6的虚拟环境哦(如果你已经是python3.6以上的环境就跳过这步吧)
conda env list #查看你现在有的环境
conda env remove -n env_name #删除
conda create -n env_name python=3.6 python36 #python36是环境的名字,自己搞哈
conda create --name python36 python=3.6
conda activate env_name #激活环境
conda activate python36 #进入虚拟环境
# 有旧版anaconda的是用 source activate python36
conda deactivate #退出虚拟环境 有的旧版anaconda是用 source deactivate
我们进入虚拟环境安装相关的一些包,我选择用的是gpu版本的,相应的cuda要求是10.0以上哦,这里给出楼主找得的版本搭配方案,有时候这些东西还是挺烦人的。
PS:如果你已经安装了mxnet的话要先卸载掉,不然会有冲突
pip install mxnet-cu100==1.5.1
pip install autogluon==0.0.3
pip install numpy==16.2
pip install gluoncv==0.7.0b20200115
pip install future #future 都是新环境中没有的但是又必须用到的包哦,负责解决python2、3兼容性的问题

导入没问题的话,我们就可以运行官方github上autogluon/examples/object_detection/demo.py文件,可以出现训练过程的话就说明安装彻底没问题啦,给公子上注释的代码~(官方这个例子,他们的gpu是32gb的,楼主的单卡8gb显存不足,out of memory了,改天用8卡的服务器试试)
PS:数据集没那工具不好下,给你一个传送门 传送门 提取码:nzu2
import autogluon as ag
from autogluon import ObjectDetection as task
import os
root = './'
# filename_zip = ag.download('https://autogluon.s3.amazonaws.com/datasets/tiny_motorbike.zip',path=root)
# filename = ag.unzip(filename_zip, root=root)
filename = 'tiny_motorbike'
data_root = os.path.join(root, filename)
dataset_train = task.Dataset(data_root, classes=('motorbike', ))
time_limits = 5*60*60 # 5 days
epochs = 30
#fit函数是将数据集和模型进行适配,其过程就是训练、推理、根据推理结果反馈得到最优的超参
#autogluon会自动把数据集划分为训练集和测试集
detector = task.fit(dataset_train,
num_trials=2, #要配置的超参数的个数
epochs=epochs, #训练的周期
lr=ag.Categorical(5e-4, 1e-4), #两种学习率的设置
ngpus_per_trial=1, #gpu的数量
time_limits=time_limits) #训练的时间限制(对于已经在训练的epoch是不会停止的)
# Evaluation on test dataset
dataset_test = task.Dataset(data_root, index_file_name='test', classes=('motorbike',))
test_map = detector.evaluate(dataset_test)
print("mAP on test dataset: {}".format(test_map[1][1]))
# visualization
image = '000467.jpg'
image_path = os.path.join(data_root, 'JPEGImages', image)
print(image_path)
ind, prob, loc = detector.predict(image_path)
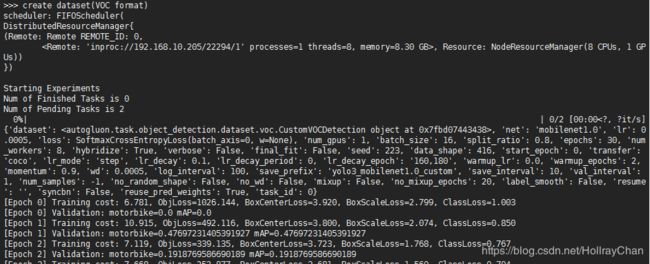
最后会输出超参数配置的结果:The best config: {'lr.choice': 1, 'net.choice': 0}选择第二个超参数更好
主要功能模块
细看官网例子的代码,发现autogluon的编程喜欢用python函数修饰器来实现参数的传递。
- autogluon.space:
Search space of possible hyperparameter values to consider.可以理解为用来存放需要autogluon搜索超参数据的一个容器 - autogluon.core:用于用户自定义对象和函数,应用在超参数调优的装饰器。
- autogluon.task:autogluon提供了四种深度学习方向的支持,包括分类、检测、文本类和表格类,.task就是用于设置具体的任务参数,数据的设置
- autogluon.scheduler:训练的任务管理器,涉及参数,数据的导入和管理。
- autogluon.searcher:根据推理的结果来对参数进行寻优
pytorch + autogluon —— 超参数和层参数的调参实现
原来我还怕需要重新写一个mxnet的网络来进行训练,其实不用。AutoGluon is a framework agnostic HPO toolkit, which is compatible with any training code written in Python.
官网下的MNIST Training in PyTorch例子,使用的方法和工程实现的原理其实很简单:
- 在原来的项目上,需要在推理的函数中,添加上一个reporter,用于存储在不同超参数设置下实现的性能。
- 把你想要调试的超参写到 autogluon.args() 中,再把他传到Scheduler管理器中,这样就可以自动检测,根据训练和推理的效果来优化你的超参数。
- 以上是autogluon超参数的实现中主要涉及到的三个重要工具,而具体某一层参数的自动调参,则也是通过把层写到 autogluon.args() 中去,在__init__添加修饰过的层,然后在forward中调用就可以了。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from tqdm.auto import tqdm
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# the datasets
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
#更多的数据形式还需要到官网中进行查看。
def train_mnist(args, reporter):
# get variables from args
lr = args.lr
wd = args.wd
epochs = args.epochs
net = args.net
print('lr: {}, wd: {}'.format(lr, wd))
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Model
net = net.to(device)
if device == 'cuda':
net = nn.DataParallel(net)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=wd)
# datasets and dataloaders
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
# Training
def train(epoch):
net.train()
train_loss, correct, total = 0, 0, 0
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
def test(epoch):
net.eval()
test_loss, correct, total = 0, 0, 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
acc = 100.*correct/total
reporter(epoch=epoch, accuracy=acc)
for epoch in tqdm(range(0, epochs)):
train(epoch)
test(epoch)
更多功能例子
- 指定具体的网络:貌似暂时model_zoo里面可供使用的‘supernet’还不多,期待更新~
import gluoncv as gcv
@ag.func(
multiplier=ag.Categorical(0.25, 0.5),
)
def get_mobilenet(multiplier):
return gcv.model_zoo.MobileNetV2(multiplier=multiplier, classes=4)
net = ag.space.Categorical('mobilenet0.25', get_mobilenet())
print(net)
更多例子请看官网手册哦~