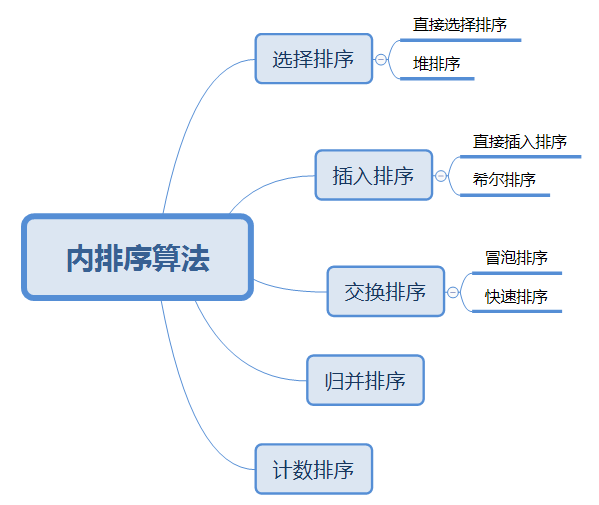
常见排序算法及JAVA实现
排序算法的分类
先看维基百科中的一张关于排序算法的表

我们主要了解常见的一些排序算法。像Bogo排序,臭皮匠排序这类完全不实用的排序可以置之不理。
我们这里要说的排序算法都是内排序,也就是只在内存中进行,涉及到对磁盘等外部存储设备中的数据进行排序称之为外排序,关于外排序的内容可以查看维基百科。
简单选择排序(SelectSort)
选择排序思想很简单,对所有元素进行遍历,选出最小(或最大)的元素与第一个元素进行交换,然后逐次缩小遍历的范围。
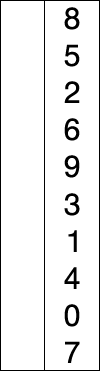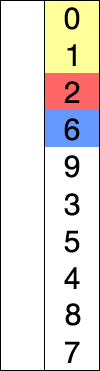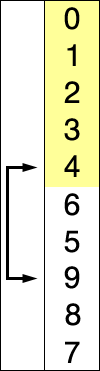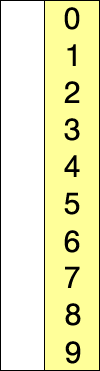
关于八大排序算法的动态图,这里有一个网站我觉得特别好。
Java实现
import org.junit.Test;
public class SelectSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
for (int i = 0; i < items.length; i++) {
int minIndex = i;
for (int j = i; j < items.length; j++) {
if (items[j].compareTo(items[minIndex]) < 0) {
// items[j] < items[maxIndex]
minIndex = j;
}
}
TYPE temp = items[i];
items[i] = items[minIndex];
items[minIndex] = temp;
}
}
// 测试代码
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testSelectSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序后:");
System.out.println(Arrays.toString(testItems));
}
}
运行结果
排序前:[3, 6, 2, 5, 9, 0, 1, 7, 4, 8]
排序后:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
进阶版选择排序----堆排序(HeapSort)
堆排序就是对上面的选择排序进行了优化。从上面的简单选择排序实现中,我们可以看出,内部的循环负责比较选出最小值,然后进行一次交换。也就是说循环n次最后只选了个最小值和最前面的进行交换,前面的循环比较得出来的结果就这样抛弃了。举个很简单的例子“8, 9, 4, 6”这个无序的数组,第一次循环中已经得到8 < 9和8 > 6这个结论,第二次循环又将9和6进行比较,很明显第一次循环已经可以得出了9>6这个结论了,9和6比较完全是浪费的,但是简单选择就是这么傻逼无脑,那有没有一种方法让前面循环进行比较得到的结果能保存起来。这就涉及到一个概念了-----二叉堆。
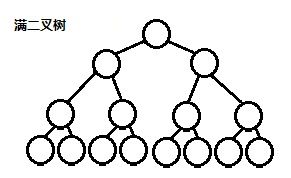
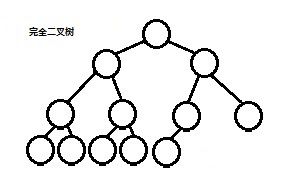
二叉堆听起来很牛逼的样子,其实说白了就是一个完全二叉树。完全二叉树是什么?就是去掉满二叉树后面若干个叶子结点,看下图:
树有很多特性,我们可以利用其层次性,让较小的元素下沉,较大的元素往上排。
二叉堆就是满足对于任意的子树都有父节点大于其子孙结点,于是最大的元素就到树顶的根节点了,这种堆就叫做大顶堆;相反小元素往上排,那就叫小顶堆了。因为二叉堆是完全二叉树,而且我们已经知道二叉堆最大的元素个数就是我们要排序的元素个数,我们的二叉堆可以就地取材直接用数组实现,所以堆排序不需要重新分配内存,空间复杂度为O(1),记得大一看“堆排序”这个名字老以为要多分配一份内存。
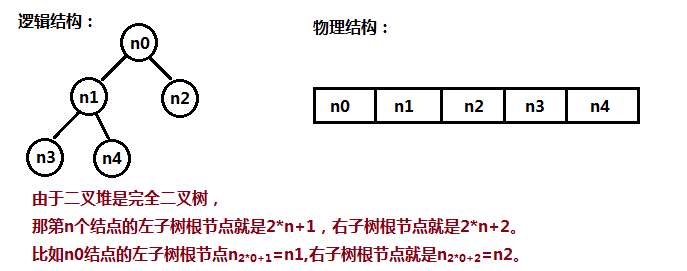
看上图的时候需要注意,这里的索引是从0开始的,和我们常用的从1开始编号得到的结论可能不同:
- 索引值为n的左结点索引值为
2*n+1,右结点索引值为2*n+2; - 索引值为n的父节点索引值为
(n-1)/2,这里的“/”是整型变量相除得到的结果也是整型变量(学计算机的都懂_)。 - 结点数为size的完全二叉树非叶子结点数目为
size/2,所以最后的那个非叶子结点的索引应该为size/2-1(因为从0开始,所以要减一) - 结点数为size的完全二叉树叶子结点数目为
size/2或size/2+1,这个结论在具体实现的时候用不到
下面这张Gif图完美地呈现了堆排序的过程:用大顶堆选出最大的,然后与最后项交换。

看图容易实现难呐,难点主要在两个地方:
- 怎么将无序的数组构造成二叉堆。
- 将堆顶最大值与最后项交换后,如何再次调整二叉堆。
JAVA实现
import org.junit.Test;
public class HeapSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
// 构造二叉堆
// 从最末端也就是最下面的非叶子结点开始进行调整
// 从而使得最大值上移到二叉堆顶端
for (int i = items.length / 2 - 1; i >= 0; i--) {
adjust(items, i, items.length);
}
for (int i = items.length - 1; i > 0; i--) {
// 将最大值与最后项进行交换
TYPE temp = items[0];
items[0] = items[i];
items[i] = temp;
// 取出最大值之后,重新调整二叉堆
// 二叉堆也随着变量i慢慢缩小
adjust(items, 0, i);
}
}
private <TYPE extends Comparable<? super TYPE>> void adjust(TYPE[] items, int index, int heapSize) {
int leftChild = 2 * index + 1;
int rightChild = 2 * index + 2;
// 在三个结点中选出最大的结点
int indexOfMax = index;
if (leftChild < heapSize) {// 左子树存在性检验
if (items[leftChild].compareTo(items[indexOfMax]) > 0) {
indexOfMax = leftChild;
}
}
if (rightChild < heapSize) {// 右子树存在性检验
if (items[rightChild].compareTo(items[indexOfMax]) > 0) {
indexOfMax = rightChild;
}
}
if (indexOfMax != index) {
// 将较大值上移
TYPE temp = items[index];
items[index] = items[indexOfMax];
items[indexOfMax] = temp;
// 千万别漏了这个等号,我调试了半天才发现这个错误
if (indexOfMax <= heapSize / 2 - 1) {
// 如果被调整后的结点也是非叶子结点
// 需要对该子树进行调整
adjust(items, indexOfMax, heapSize);
}
}
}
// 测试代码
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testHeapSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序后:");
System.out.println(Arrays.toString(testItems));
}
}
有一个“平滑排序”算法和堆排序有点类似,“平滑排序”使用的是另一种二叉树----Leonardo树。关于“平滑排序”的各种说明,这里有篇文章可供参考。
简单插入排序(InsertSort)
插入排序原理也很简单,和整理扑克牌有点像。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UbwmXhjZ-1581237081330)(http://docs.huihoo.com/c/linux-c-programming/images/sortsearch.sortcards.png)]
在未排序的部分选择一个元素,插入到已排序的部分,插入时会将比这个值大的所有元素往后挤。下面有动态图,看的很清楚。
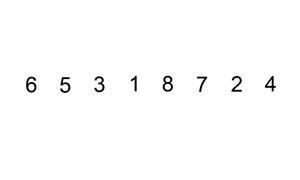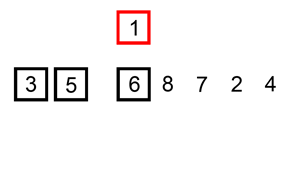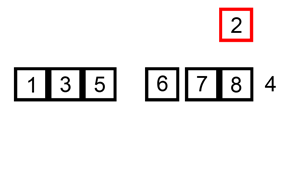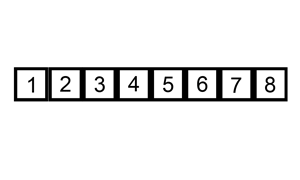
JAVA实现
import org.junit.Test;
public class InsertSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
for (int i = 1; i < items.length; i++) {
TYPE current = items[i];
int j = i - 1;
do {
if (current.compareTo(items[j]) < 0) {
items[j + 1] = items[j];// 后移
} else {
break;
}
j--;
} while (j >= 0);
items[j + 1] = current; // 插入
}
}
// 测试代码
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testInsertSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序后:");
System.out.println(Arrays.toString(testItems));
}
}
进阶版插入排序----希尔排序(ShellSort)
希尔排序也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序这名字可能不好理解,因为这是设计者的名字,但是提到“缩小增量排序”这个名字,可能你就已经理解一小半了。
既然说插入排序不是最高效的,那我们来想想怎么能将其进行优化吧。从上面的代码可以看出内层的循环是负责为current找到插入的位置,这是在有序的数组中查找位置,我第一个想到的就是二分查找(可能是对二分查找太敏感),但是细想之后,你会发现即使你找到那个插入点,但是你还是得将插入点后面的元素往后移动腾出个空位,这始终避免不了上面实现代码的内层循环操作。
维基百科中是这样概括插入排序的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
于是呢,“希尔”大神发明了一种算法,让插入排序移动的步伐变大,元素可以一次性朝最终目标前进一大步,从而避免了大量的数据移动。希尔排序图片不好找,下面的图片凑合着看吧:

步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。当步长为1时,算法变为插入排序,这就保证了数据一定会被排序。
Donald Shell最初建议步长选择为 n/2 ,并且对步长取半直到步长达到1。虽然这样取可以比 O(n*n) 类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在迭代过程中会打乱以前的顺序,那就不会以如此短的时间完成排序了。----摘自维基百科
从维基百科的解释可以看出步长序列的选择是希尔排序的关键,一般来说我们选择的初始步长都为n/2,然后依次取半,直至为1,而且最终步长为1后才能终止,否则序列中某些元素仍是乱序。下面的JAVA实现中的步长就是依据以此。
维基百科中也提到了一些特殊步长序列,这些步长序列经过精心设计,而且使用这些精心设计的步长序列,排序速度会得到提升,详细可参考维基百科
JAVA实现
import org.junit.Test;
public class ShellSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
for (int step = items.length / 2; step > 0; step /= 2) {
// 内层其实就是一个步长为step的插入排序
for (int i = step; i < items.length; i++) {
TYPE current = items[i];
int j = i - step;
do {
if (current.compareTo(items[j]) < 0) {
items[j + step] = items[j];// 后移
} else {
break;
}
j -= step;
} while (j >= 0);
items[j + step] = current;// 插入
}
}
}
// 测试代码
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testShellSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序后:");
System.out.println(Arrays.toString(testItems));
}
}
冒泡排序(BubbleSort)
冒泡可能是这八大排序中最简单的。“冒泡”两字很形象----大的元素慢慢的浮上去。冒泡排序只对相邻的两个元素进行交换。不多说,看图好理解。
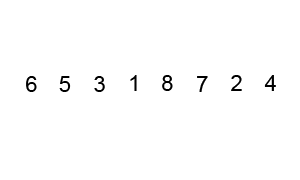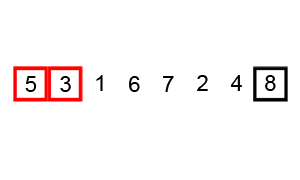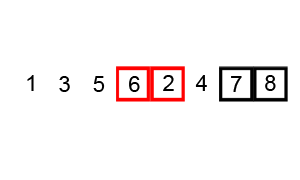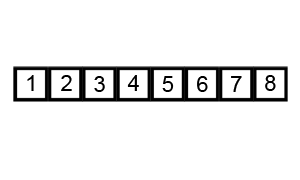
JAVA实现
import org.junit.Test;
public class BubbleSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
for (int i = 0; i < items.length; i++) {
for (int j = 0; j < items.length - i - 1; j++) {
if (items[j].compareTo(items[j + 1]) > 0) {
TYPE temp = items[j];
items[j] = items[j + 1];
items[j + 1] = temp;
}
}
}
}
// 测试代码
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testBubbleSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序后:");
System.out.println(Arrays.toString(testItems));
}
}
冒泡排序的简单优化
冒泡排序可能是所有排序中最简单最容易理解的一种,但是也是效率最低的一种:无论原始数组是否接近有序,它都需要循环n(n-1)次,虽然并不是每次循环都进行交换,但仍然影响效率。举个例子,1、2、5、4、6、7,这个序列中基本接近有序,只需进行一次交换即可完成排序,但未优化的冒泡排序则必须循环6*7次才完成排序,所以我们可以进行以下优化:
public void sort(int[] items) {
for (int i = 0; i < items.length; i++) {
boolean noswap = true;
for (int j = 0; j < items.length - i - 1; j++) {
if (items[j] > items[j + 1]) {
noswap = false;
int temp = items[j];
items[j] = items[j + 1];
items[j + 1] = temp;
}
}
if (noswap) break;//快速终止
}
}
冒泡排序变形版----鸡尾酒排序(CocktailSort)
上面的冒泡排序每次循环都是从前到后进行相邻的比较。而鸡尾酒是前后来回地进行交换,有点像调鸡尾酒来回搅动,也有人把它叫做“双向冒泡排序”。鸡尾酒排序只是在冒泡排序的基础上做了些轻微改动,在效率上冒泡排序和鸡尾酒排序相差不了多少。
JAVA实现
import org.junit.Test;
public class CocktailSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
int left = 0, right = items.length - 1;
while (left < right) {
for (int i = left; i < right; i++) {
if (items[i].compareTo(items[i + 1]) > 0) {
TYPE temp = items[i];
items[i] = items[i + 1];
items[i + 1] = temp;
}
}
right--;
for (int i = right; i > left; i--) {
if (items[i - 1].compareTo(items[i]) > 0) {
TYPE temp = items[i];
items[i] = items[i - 1];
items[i - 1] = temp;
}
}
left++;
}
}
// 测试代码
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testCocktailSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序后:");
System.out.println(Arrays.toString(testItems));
}
}
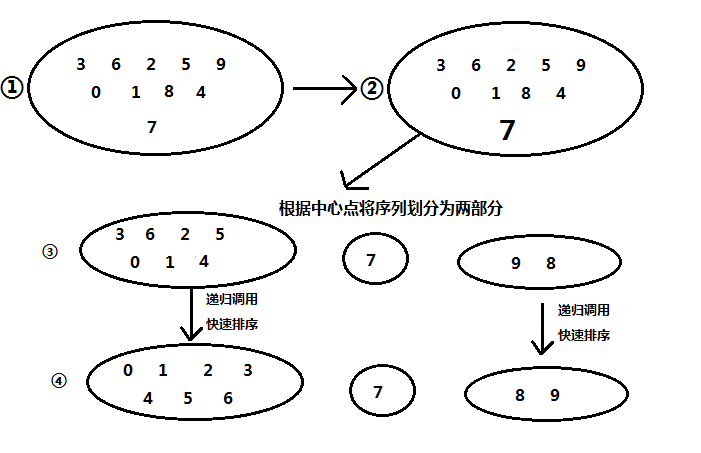
快速排序(QuickSort)
快速排序使用的是分治思想,把原有问题分成两个子问题进行递归解决,步骤如下:
- 如果待排序的数组项数为0或1,直接返回。(递归出口)
- 在待排序的数组中任选一个元素,作为中心点(pivot)
- 将小于中心点的元素,大于中心点的元素划分为开来。也就是将小于中心点的元素放在中心点前面,大于中心点的元素放在中心点后面。
- 对前面小于中心点的元素进行快速排序,对大于中心点的元素进行快速排序
- 返回前部分的快速排序结果,接上中心点,再跟上后部分的快速排序结果。
画了个图,有点丑,凑合凑合看吧
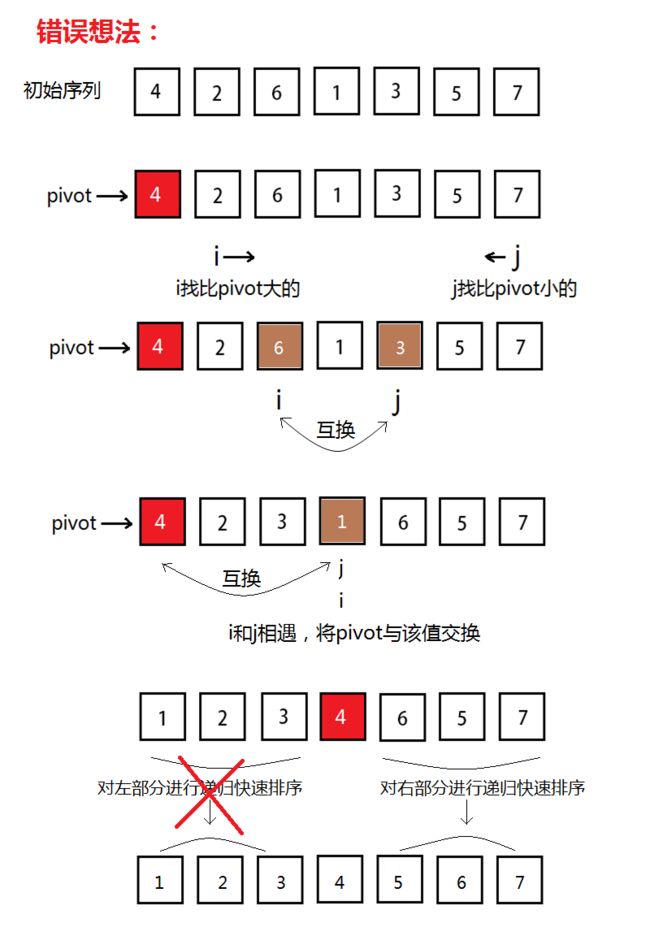
选择pivot中心点是个很关键的问题,常见的做法是:直接使用序列的第一个元素或最后一个元素作为中心点,但是这要解决一个问题:怎么把小于中心点的元素放到中心元素左边,大于中心点的元素放到中心点的右边。
先看一下这张图,这是我在想实现方法的时候碰到的一种错误解决方法,贴在这引以为鉴((__) )
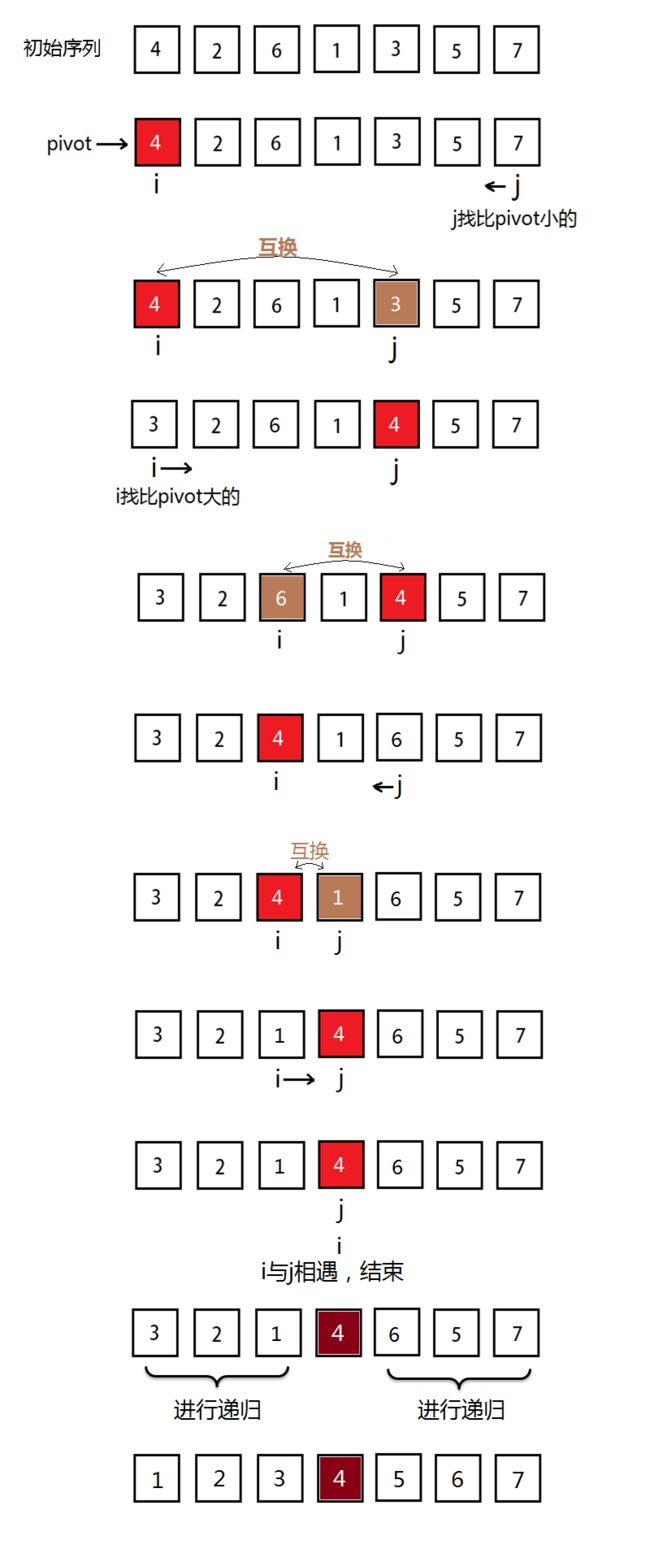
后来细想一遍应该这样:
真正写代码的时候才发现,干嘛要进行互换呢,互换要三条赋值语句,一句赋值多干净,覆盖了它也没啥事。
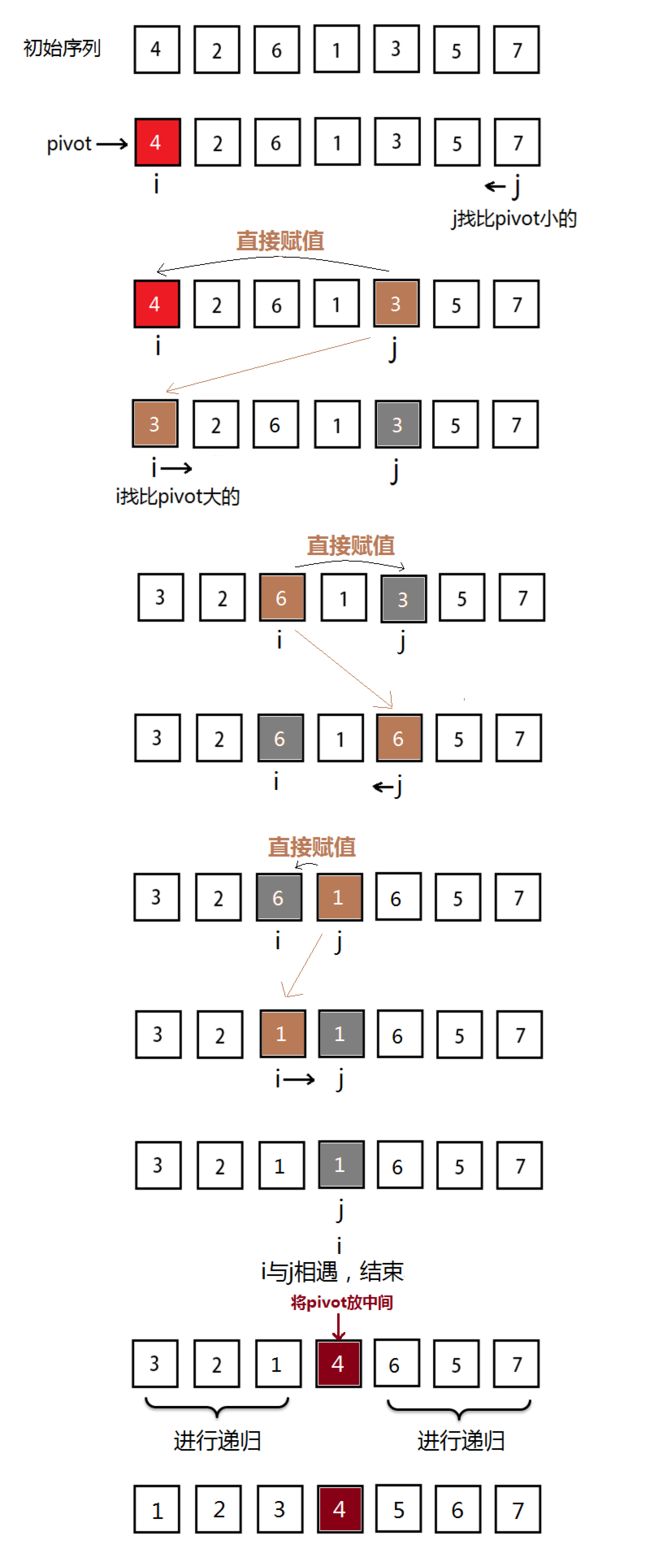
JAVA实现
import org.junit.Test;
public class QuickSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
quickSort(items, 0, items.length - 1);
}
private <TYPE extends Comparable<? super TYPE>> void quickSort(TYPE[] items, int start, int end) {
if (start < end) {
TYPE pivot = items[start];
int i = start;
int j = end;
while (i < j) {
// 找到一个小于中心点
while (i < j) {
if (items[j].compareTo(pivot) < 0) {
items[i] = items[j];
break;
}
j--;
}
// 找到一个大于中心点
while (i < j) {
if (items[i].compareTo(pivot) > 0) {
items[j] = items[i];
break;
}
i++;
}
}
items[i] = pivot;
quickSort(items, start, i - 1);
quickSort(items, i + 1, end);
}
}
// 测试代码
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testQuickSort() {
System.out.print("排序前:");
for (int i = 0; i < testItems.length; i++) {
testItems[i] = (int) (Math.random() * 100);
}
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序后:");
System.out.println(Arrays.toString(testItems));
}
}
归并排序(MergeSort)
归并排序使用的也是分治思想,不同的是它是直接将序列分为两个子序列进行递归排序。
归并排序主要分为一下几个步骤:
- 如果待排序的序列项数为0或1,直接返回。(递归出口)
- 对等分的两个部分分别进行递归排序。
- 将排好序的两部分合并为一个有序数组。
具体过程看下面的动态图
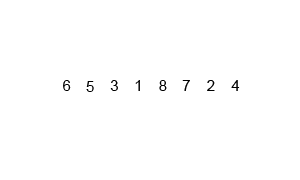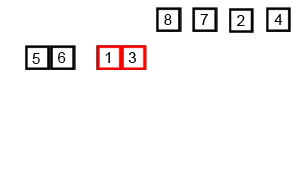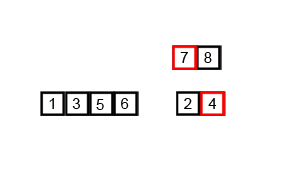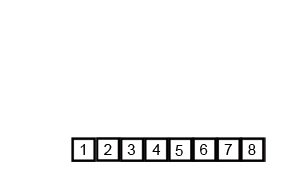
- 归并排序是外排序的基础
- 有序数组进行归并排序能在线性时间内完成
JAVA实现
import org.junit.Test;
public class MergeSort implements SortAlgorithm {
public <TYPE extends Comparable<? super TYPE>> void sort(TYPE[] items) {
@SuppressWarnings("unchecked")
// 后面递归调用都使用这个临时缓冲区。
TYPE[] tmpArray = (TYPE[]) new Comparable[items.length];
mergeSort(items, tmpArray, 0, items.length - 1);
}
private <TYPE extends Comparable<? super TYPE>> void mergeSort(TYPE[] items, TYPE[] tmpArray, int startIndex,
int endIndex) {
if (startIndex < endIndex) {
int centerIndex = (startIndex + endIndex) >> 1;
mergeSort(items, tmpArray, startIndex, centerIndex);
mergeSort(items, tmpArray, centerIndex + 1, endIndex);
merge(items, tmpArray, startIndex, centerIndex, endIndex);
}
}
private <TYPE extends Comparable<? super TYPE>> void merge( // 合并左右序列
TYPE[] items, // 原始数组
TYPE[] tmpArray, // 临时数组,用来合并
int leftPos, // 左序列起始位置
int leftEnd, // 左序列结束位置
int rightEnd // 右序列结束位置
) {
int rightPos = leftEnd + 1; // 右序列的起始位置
int tmpPos = leftPos; // 合并时的临时索引
int eleCount = rightEnd - leftPos + 1; // 左右序列元素的总数
while (leftPos <= leftEnd && rightPos <= rightEnd) {
if (items[leftPos].compareTo(items[rightPos]) < 0) {
// 左序列的值较小,将左序列元素放入临时数组
tmpArray[tmpPos++] = items[leftPos++];
} else {
// 右序列的值较小,将右序列元素放入临时数组
tmpArray[tmpPos++] = items[rightPos++];
}
}
// 左序列剩余元素放入临时数组
while (leftPos <= leftEnd) {
tmpArray[tmpPos++] = items[leftPos++];
}
// 右序列剩余元素放入临时数组
while (rightPos <= rightEnd) {
tmpArray[tmpPos++] = items[rightPos++];
}
// 将合并后的数据拷贝回原始数组
int startIndex = rightEnd - eleCount + 1;
System.arraycopy(tmpArray, startIndex, items, startIndex, eleCount);
}
// 测试代码
private final Integer[] testItems = { 3, 6, 2, 5, 9, 0, 1, 7, 4, 8 };
@Test
public void testMergeSort() {
System.out.print("排序前:");
System.out.println(Arrays.toString(testItems));
sort(testItems);
System.out.print("\n排序后:");
System.out.println(Arrays.toString(testItems));
}
}
接下来要讲的所有排序算法和上面的排序算法思想完全不同,没有交换、选择,插入等操作,都是使用统计计数来实现的。
注意:由于网上的很多资料与书籍都没有将计数排序,基数排序,鸽巢排序,桶排序划分清楚,大多数算法都只是伪代码(图书馆里找了很多书籍,也在网上查了很多资料,很难找到一个准确的说法,或者是长篇大论,未明所云,或者大篇幅的伪代码解释,无法上机验证),所以下面的排序算法名称和算法的真正实现原理可能不吻合,如果您对以下算法有不同的看法,还望指点一二,笔者不胜感激。
计数排序(CountingSort)
因为后面的基数排序是从计数排序优化得到的,所以我们先讲讲计数排序。
计数排序有两种实现,先来看第一种比较直观的:
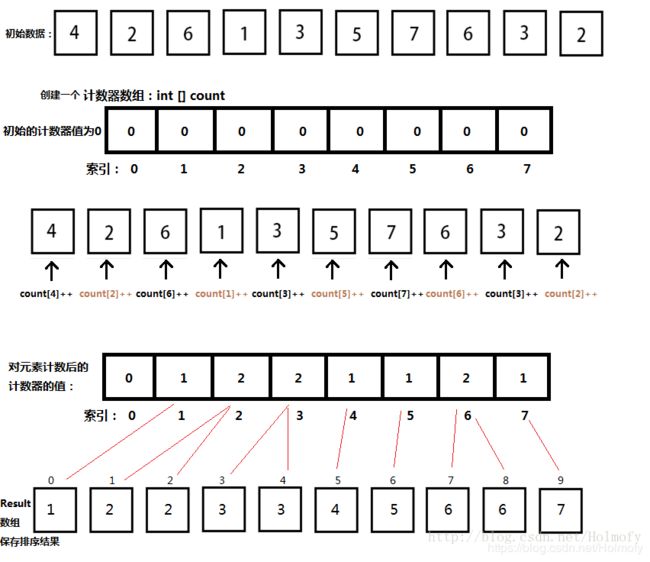
实现代码如下:
import java.util.Arrays;
import org.junit.Test;
/**
* 简单计数排序
*
* @author Holmofy
*/
public class CountingSort {
public int[] countingSort(int[] items, int max) {
// 前提是数组中的数据满足 item[n]>=0 && item[n]<=k
int[] counter = new int[max + 1]; // 索引从0开始,所以这里计数器数组长度为max+1
// 计数
for (int item : items) {
counter[item] += 1;
}
int index = 0;
for (int i = 0; i < counter.length; i++) {
for (int j = 0; j < counter[i]; j++) {
items[index++] = i;
}
}
return items;
}
// 测试代码
private final int[] testItems = new int[]{16, 2, 10, 14, 7, 9, 3, 2, 8, 1};
@Test
public void testCountSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
System.out.println("排序后:" + Arrays.toString(countingSort(testItems, 16)));
}
}
还有一种实现通过统计小于某个值的个数从而确定一个值的存放位置,这中实现方式可能不是很好理解:
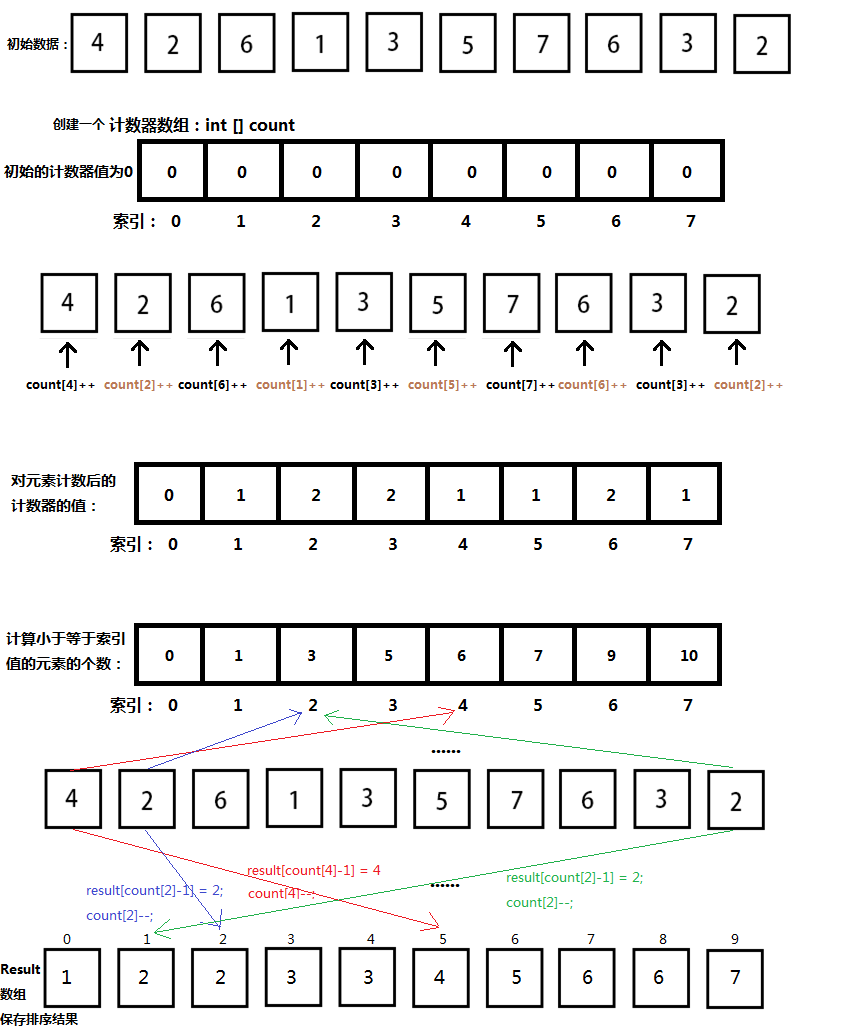
上面的图可能画的有点乱,如果还不理解可以看看下面的实现代码。
##优化前的代码
import java.util.Arrays;
import org.junit.Test;
/**
* 简单计数排序
*
* @author Holmofy
*
*/
public class CountingSort {
public int[] countingSort(int[] items, int max) {
int[] result = new int[items.length];
// 前提是数组中的数据满足 item[n]>=0 && item[n]<=k
int k = max + 1;// 索引从0开始
countingSort(items, result, k);
return result;
}
private void countingSort(int[] items, int[] result, int k) {
int[] counter = new int[k];
// 计数
for (int j = 0; j < items.length; j++) {
int a = items[j];
counter[a] += 1;
}
// 求计数和
for (int i = 1; i < k; i++) {
counter[i] = counter[i] + counter[i - 1];
}
// 整理出新序列
// 注意这里需要从后开始读取
for (int j = items.length - 1; j >= 0; j--) {
int a = items[j];
result[--counter[a]] = a;
}
}
// 测试代码
private final int[] testItems = new int[] { 16, 2, 10, 14, 7, 9, 3, 2, 8, 1 };
@Test
public void testCountSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
System.out.println("排序后:" + Arrays.toString(countingSort(testItems, 16)));
}
}
运行结果
排序前:[16, 2, 10, 14, 7, 9, 3, 2, 8, 1]
排序后:[1, 2, 2, 3, 7, 8, 9, 10, 14, 16]
源码面前了无秘密。
##计数排序的优化
事实上,上面实现的计数排序有很大的限制,对于一个未知序列我们无法得知序列中的最大值是多少,从而无法分配合理大小的计数器数组,而且如果序列的最小值小于0,我们通过索引取计数器时将会发生错误。所以我们可以遍历一遍序列获取序列最大值和最小值,从而确定计数器数组大小。看一看优化后的代码。
##优化后的代码
import org.junit.Test;
import java.util.Arrays;
public class CountSort {
public int[] countSort(int[] items) {
int[] result = new int[items.length];
// 遍历一遍来获取序列的最大值和最小值
int max = items[0], min = items[0];
for (int i : items) {
if (i > max) {
max = i;
}
if (i < min) {
min = i;
}
}
// 这里k的大小是要排序的数组中,元素大小的极值差+1
int k = max - min + 1;
int counter[] = new int[k];
// 计数
for (int i = 0; i < items.length; i++) {
counter[items[i] - min]++;// 优化过的地方,减小了数组c的大小
}
// 求计数和
for (int i = 1; i < counter.length; i++) {
counter[i] = counter[i] + counter[i - 1];
}
// 整理出新序列
for (int i = items.length - 1; i >= 0; i--) {
int item = items[i];
result[--counter[item - min]] = item;// 按存取的方式取出c的元素
}
return result;
}
// 测试代码
private final int[] testItems = new int[] { -1, -3, 16, 2, 10, 14, 7, 9, 3, 2, 8, 1, -4 };
@Test
public void testCountSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
System.out.println("排序后:" + Arrays.toString(countSort(testItems)));
}
}
运行结果:
排序前:[-1, -3, 16, 2, 10, 14, 7, 9, 3, 2, 8, 1, -4]
排序后:[-4, -3, -1, 1, 2, 2, 3, 7, 8, 9, 10, 14, 16]
上面的计数排序和前面讲到的交换,插入的排序相比,还有很多缺点:
- 因为对序列中的数据计数依赖数组索引,所以计数排序只能用来对整型数据进行排序。
- 空间复杂度较高,存储结果的Result数组,以及计数器数组都需要分配内存,而且如果需要排序的数据比较稀疏,计数器数组会占用很大的内存空间。
计数排序的另一种优化方式----基数排序(RadixSort)
上面虽然对计数排序进行了优化,但是如果对于数据稀疏的序列进行计数排序,那计数器数组中将有很多空间会浪费掉。举个例子,比如说我们有一个序列3,100,10086,404,6,57,2048,对于这样小的一个序列,如果用计数排序我们最少需要分配10086-3=10083个内存长度的计数器,⊙﹏⊙这得浪费多少内存呐,因此基数排序应运而生。
基数排序首先需要选择一个基数(Radix)。什么是基数呢,其实就是我们常说的进制中的基数,二进制的基数是2,8进制的基数是8,十进制的基数是10…,通常我们选择的基数是10,看起来比较直观,调试也方便。有了基数后我们怎么用它来优化计数排序呢,核心步骤和计数排序相同,只是根据位数的多少进行了多轮计数。具体看下图。
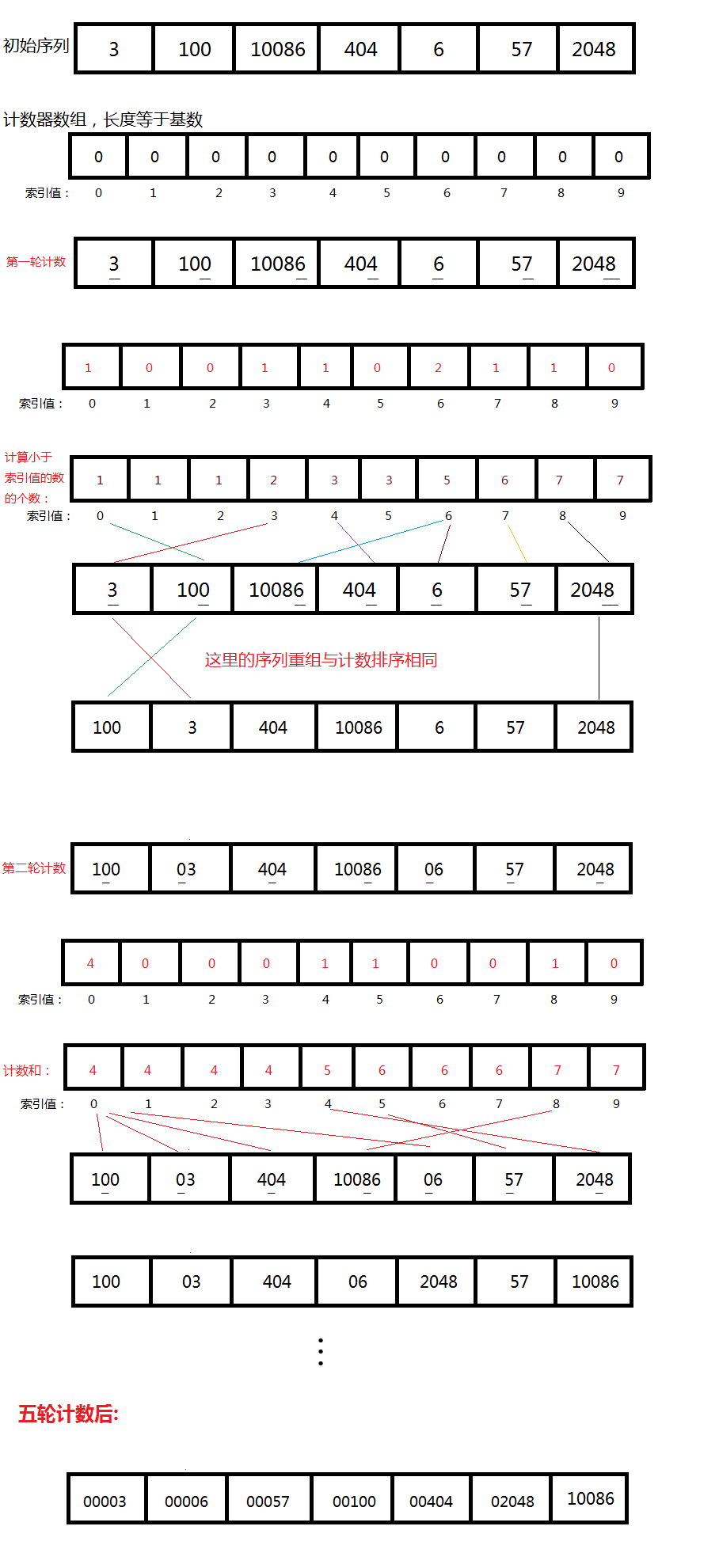
import java.util.Arrays;
import org.junit.Test;
/**
* 基数排序
*
* @author Holmofy
*
*/
public class RadixSort {
public void radixSort(int[] items) {
radixSort(items, 10);
}
public void radixSort(int[] items, int radix) {
int maxLength = 0;
for (int i = 0; i < items.length; i++) {
int itemLength = length(items[i], radix);
if (maxLength < itemLength) {
maxLength = itemLength;
}
}
int[] counter = new int[radix];
int[] result = new int[items.length];
for (int i = 0, r = 1; i < maxLength; i++, r *= radix) {
Arrays.fill(counter, 0);
// 内部就是一个计数排序
// 计数
for (int j = 0; j < items.length; j++) {
counter[(items[j] / r) % radix]++;
}
// 计数和
for (int j = 1; j < radix; j++) {
counter[j] += counter[j - 1];
}
// 整理出新序列
for (int j = items.length - 1; j >= 0; j--) {
int item = items[j];
result[--counter[(item / r) % radix]] = item;
}
System.arraycopy(result, 0, items, 0, items.length);
}
}
private int length(int num, int radix) {
int l = 1;
for (; num >= radix; num /= radix, l++);// 这里有个分号
return l;
}
// 测试代码
private final int[] testItems = new int[] { 17, 256, 100, 404, 7, 9, 333, 2048, 10086, 100 };
@Test
public void testRadixSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
radixSort(testItems);
System.out.println("排序后:" + Arrays.toString(testItems));
}
}
运行结果:
排序前:[17, 256, 100, 404, 7, 9, 333, 2048, 10086, 100]
排序后:[7, 9, 17, 100, 100, 256, 333, 404, 2048, 10086]
到了这里基数排序还有一个缺陷:对于序列中的负数无能为力了,因为这里的算法和未优化的计数排序类似,如果你有更好的方案对基数排序进行优化,可以和大家分享一下。
鸽巢排序(PigeonholeSort)
讲桶排序之前,先来说说鸽巢排序,其实鸽巢排序和前面的计数排序原理类似,这里说的鸽巢其实就是计数器,不同的是后面的数据重排过程,鸽巢排序相对于计数排序来说更好理解,我就直接画张图贴在这了。
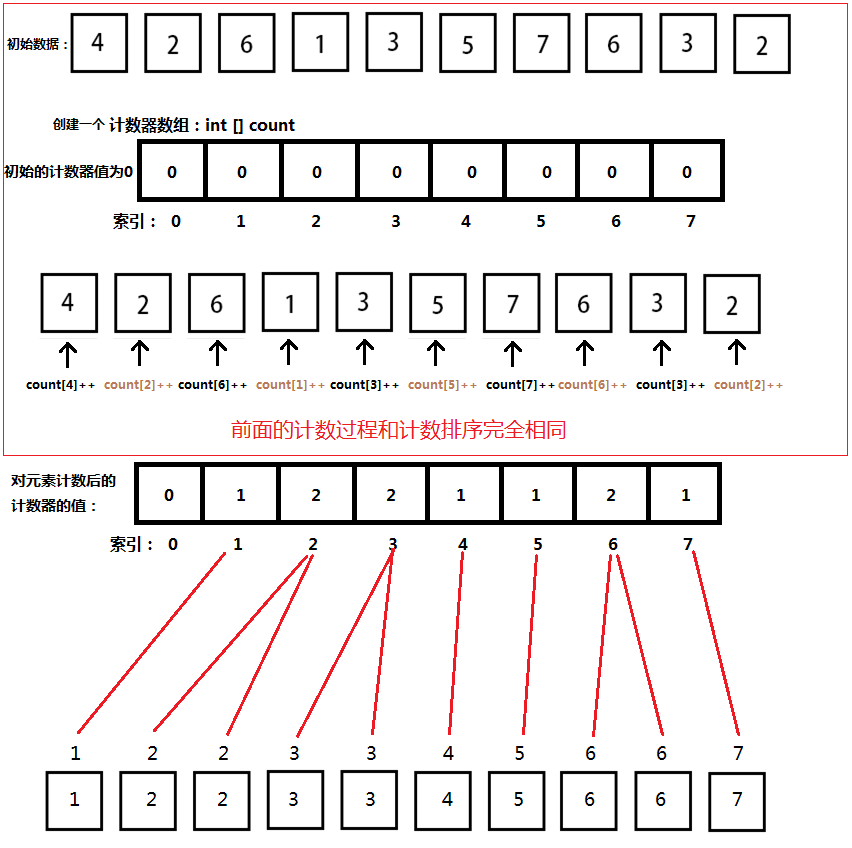
可以看出鸽巢排序是直接将遍历计数器中的记录,并对应的索引填入到数组中。
JAVA实现
import java.util.Arrays;
import org.junit.Test;
public class PigeonholeSort {
public void pigeonholeSort(int[] items, int max) {
// 假设A中的数据a'有,0<=a' && a' < k并且k=17
int[] hole = new int[max + 1];
for (int i = 0; i < items.length; i++)
hole[items[i]]++;
for (int i = 0, j = 0; i < hole.length; i++)
for (int k = 0; k < hole[i]; k++)
items[j++] = i;
}
// 测试代码
private final int[] testItems = new int[] { 16, 2, 10, 14, 7, 9, 3, 2, 8, 1 };
@Test
public void testPigeonholeSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
pigeonholeSort(testItems, 16);
System.out.println("排序后:" + Arrays.toString(testItems));
}
}
和计数排序一样,上面的算法无法解决负数出现的问题,下面是对其进行优化后的算法:
import java.util.Arrays;
import org.junit.Test;
public class PigeonholeSort {
public void pigeonholeSort(int[] items) {
// 遍历一遍来获取序列的最大值和最小值
int max = items[0], min = items[0];
for (int i : items) {
if (i > max) {
max = i;
}
if (i < min) {
min = i;
}
}
int size = max - min + 1;
int[] hole = new int[size];
for (int i = 0; i < items.length; i++)
hole[items[i] - min]++;
for (int i = 0, j = 0; i < hole.length; i++)
for (int k = 0; k < hole[i]; k++)
items[j++] = i + min;
}
// 测试代码
private final int[] testItems = new int[] { 16, 2, 10, 14, 7, 9, 3, 2, 8, 1 };
@Test
public void testPigeonholeSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
pigeonholeSort(testItems);
System.out.println("排序后:" + Arrays.toString(testItems));
}
}
计数排序与鸽巢排序的比较
这个算法和计数排序其实很相似,与计数排序的不同点在于:计数排序通过使用辅助数组result来降低时间复杂度,而鸽巢排序相比计数排序的时间复杂度高很多,鸽巢排序有时甚至不如直接选择,直接插入等排序算法效率高,因为当序列数据比较稀疏的时候,鸽巢hole数组(你也可以把它理解为计数器)将会很大,进而导致内层循环执行次数增多。
桶排序(BucketSort)
桶排序和基数排序原理差不多,不同的是:桶排序将数据按照指定位的值分开装进不同的桶中,然后倒回原数组,而不像基数排序那样巧妙的使用计数器计算出元素的位置。这里所说的桶本质上就是一个线性表,而线性表可以使用数组实现,也可以使用链表实现,所以桶排序也有两种实现方式。
数组实现
这个很容易理解,直接上图了
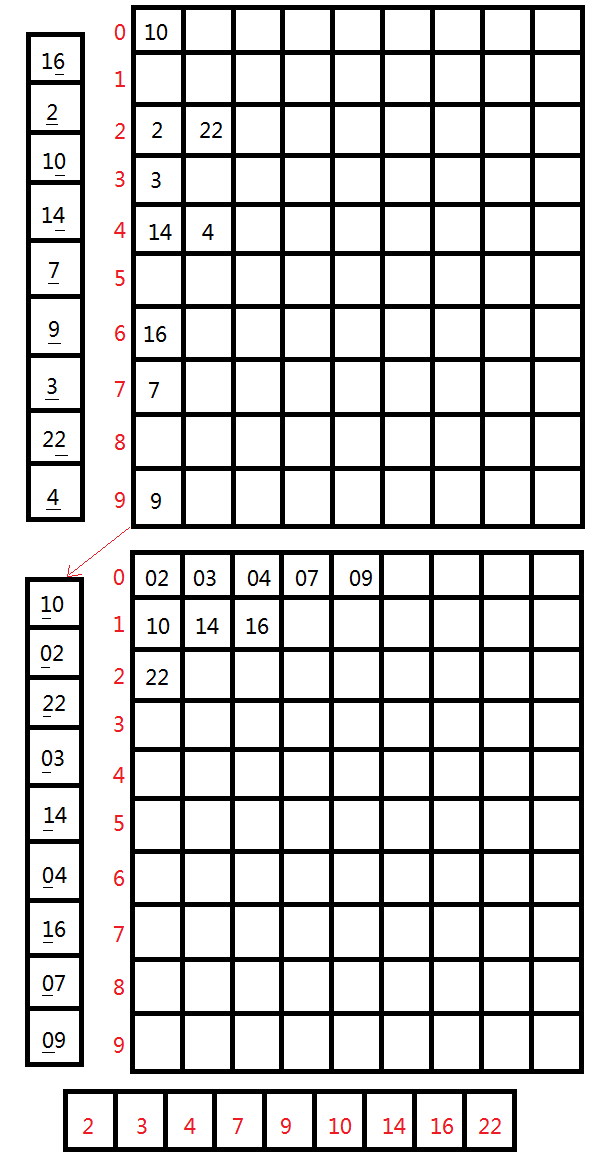
JAVA实现代码
import java.util.Arrays;
import org.junit.Test;
public class ArrayBucketSort {
public void bucketSort(int items[]) {
bucketSort(items, 10);
}
public void bucketSort(int items[], int radix) {
int n = items.length;
int bucket[][] = new int[radix][n];// 要考虑最坏的情况,所有的元素入同一个桶
int counter[] = new int[radix];
int maxLength = 0;
for (int i = 0; i < items.length; i++) {
int itemLength = length(items[i], radix);
if (maxLength < itemLength) {
maxLength = itemLength;
}
}
for (int i = 0, r = 1; i < maxLength; i++, r *= radix) {
Arrays.fill(counter, 0);// 上一轮的计数器置空
// 入桶
for (int j = 0; j < items.length; j++) {
int digit = (items[j] / r) % radix;
bucket[digit][counter[digit]++] = items[j];
}
// 出桶
for (int j = 0, index = 0; j < radix; j++) {
for (int k = 0; k < counter[j]; k++) {
items[index++] = bucket[j][k];
}
}
}
}
private int length(int num, int radix) {
int l = 1;
for (; num >= radix; num /= radix, l++) ;
return l;
}
// 测试代码
private final int[] testItems = new int[] { 16, 2, 10, 14, 7, 9, 3, 2, 8, 1 };
@Test
public void testCountSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
bucketSort(testItems);
System.out.println("排序后:" + Arrays.toString(testItems));
}
}
链表实现
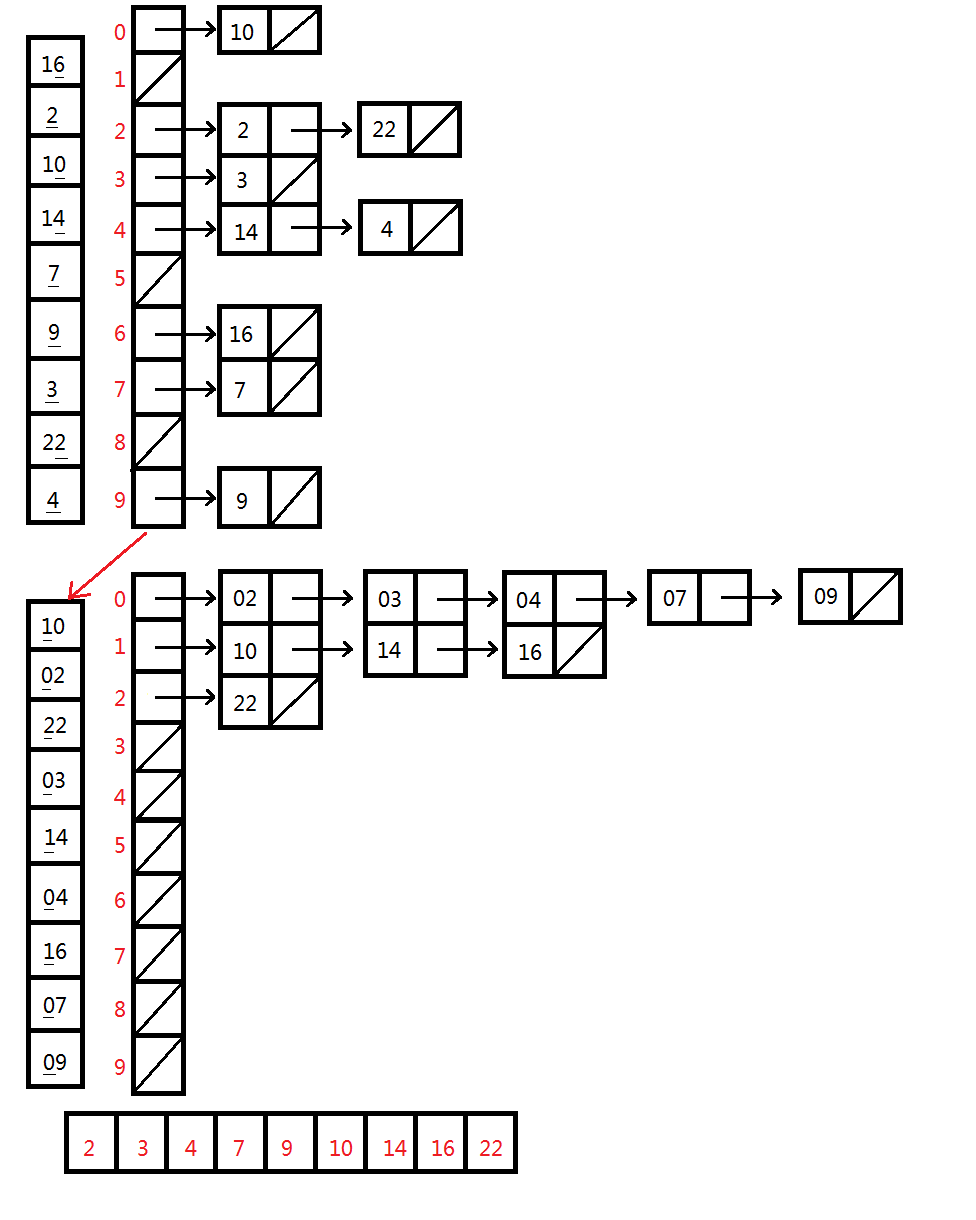
JAVA实现代码
import java.util.Arrays;
import org.junit.Test;
public class LinkBucketSort {
private class Node {
Node(Node next, int value) {
this.next = next;
this.value = value;
}
Node next;
int value;
}
public void bucketSort(int items[]) {
bucketSort(items, 10);
}
public void bucketSort(int items[], int radix) {
Node[] bucket = new Node[radix];
int maxLength = 0;
for (int i = 0; i < items.length; i++) {
int itemLength = length(items[i], radix);
if (maxLength < itemLength) {
maxLength = itemLength;
}
}
for (int i = 0, r = 1; i < maxLength; i++, r *= radix) {
// 入桶
for (int j = 0; j < items.length; j++) {
int digit = (items[j] / r) % radix;
enter(bucket, digit, items[j]);
}
// 出桶
for (int j = 0, index = 0; j < radix; j++) {
for (Node curr = bucket[j]; curr != null; curr = curr.next) {
items[index++] = curr.value;
}
bucket[j] = null;// 把桶清空
}
}
}
// 入桶
private void enter(Node[] bucket, int bucketNum, int value) {
Node curr = bucket[bucketNum];
if (curr == null) {
bucket[bucketNum] = new Node(null, value);
return;
}
while (curr.next != null)
curr = curr.next;
curr.next = new Node(null, value);
}
private int length(int num, int radix) {
int l = 1;
for (; num >= radix; num /= radix, l++)
;
return l;
}
// 测试代码
private final int[] testItems = new int[] { 16, 2, 10, 14, 7, 9, 3, 2, 8, 1 };
@Test
public void testCountSort() {
System.out.println("排序前:" + Arrays.toString(testItems));
bucketSort(testItems);
System.out.println("排序后:" + Arrays.toString(testItems));
}
}
排序算法大比拼
随机生成1000个一万以内的数据
int[] testItems = new int[1000];
System.out.print("排序前:");
for (int i = 0; i < testItems.length; i++) {
testItems[i] = (int) (Math.random() * 10000);
System.out.print(testItems[i] + " ");
}
然后依次使用各个排序算法进行排序并计时
start = System.nanoTime();
SortAlgorithm.sort(tmp);
end = System.nanoTime();
最终得到的结果(单位已经从纳秒换算成毫秒了):
SelectSort耗时:6.257215
HeapSort耗时:1.153163
InsertSort耗时:3.09207
ShellSort耗时:0.614966
BubbleSort耗时:8.024113
CocktailSort耗时:5.349134
QuickSort耗时:0.496325
MergeSort耗时:0.675724
CountSort耗时:0.354283
RadixSort耗时:0.461429
PigeonholeSort耗时:0.309536
ArrayBucketSort耗时:0.403546
LinkBucketSort耗时:2.520621
可以看出冒泡排序是最耗时的,计数排序速度最快(果真是线性时间)。
数组实现的桶排序ArrayBucketSort和链表实现的桶排序LinkBucketSort时间差别还是很大,应该是LinkBucketSort在排序过程中需要new Node()的原因,所以说new对象耗时还是巨大的。
最后呢,再贴一张维基百科中对各个排序的对比作为整篇文章的总结:
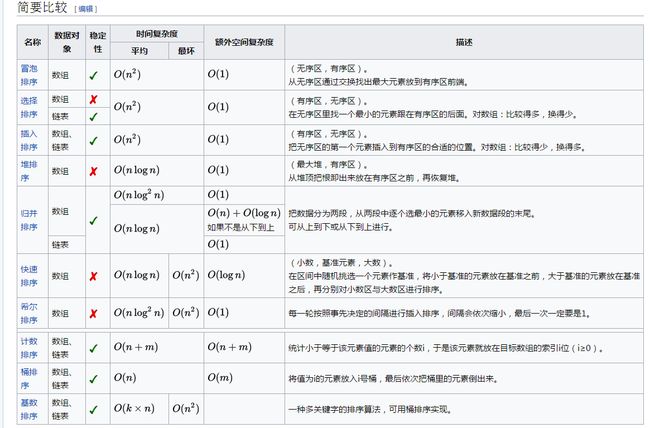
代码下载地址
CSDN:点击这里下载全部代码
Github:https://github.com/holmofy/algorithm/tree/master/Sort
参考资料:
- 维基百科:https://zh.wikipedia.org/wiki/%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95
- 八大排序各显神通:http://blog.csdn.net/u010850027/article/details/49362279
- 希尔排序:http://www.cnblogs.com/jingmoxukong/p/4303279.html