SpringBoot - 信息检索与ElasticSearch入门
【1】检索
我们的应用经常需要添加检索功能,开源的 ElasticSearch 是目前全文搜索引擎的首选。他可以快速的存储、搜索和分析海量数据。Spring Boot通过整合Spring Data ElasticSearch(Spring Data的子项目)为我们提供了非常便捷的检索功能支持。
ElasticSearch是一个分布式搜索服务,提供Restful API,底层基于Lucene,采用多shard(分片)的方式保证数据安全,并且提供自动resharding的功能,github等大型的站点也是采用了ElasticSearch作为其搜索服务。
Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
ElasticSearch官网地址:https://www.elastic.co/。
【2】面向文档
在应用程序中对象很少只是一个简单的键和值的列表。通常,它们拥有更复杂的数据结构,可能包括日期、地理信息、其他对象或者数组等。
也许有一天你想把这些对象存储在数据库中。使用关系型数据库的行和列存储,这相当于是把一个表现力丰富的对象挤压到一个非常大的电子表格中:你必须将这个对象扁平化来适应表结构–通常一个字段>对应一列–而且又不得不在每次查询时重新构造对象。
Elasticsearch 是 面向文档 的,意味着它存储整个对象或 文档。Elasticsearch 不仅存储文档,而且 _索引 每个文档的内容使之可以被检索。在 Elasticsearch 中,你 对文档进行索引、检索、排序和过滤–而不是对行列数据。这是一种完全不同的思考数据的方式,也是 Elasticsearch 能支持复杂全文检索的原因。
Elasticsearch 使用 JavaScript Object Notation 或者 JSON 作为文档的序列化格式。JSON 序列化被大多数编程语言所支持,并且已经成为 NoSQL 领域的标准格式。 它简单、简洁、易于阅读。
【3】Docker下简易安装ElasticSearch
① 查找镜像
docker search elasticsearch② 拉取镜像,这里使用加速
docker pull registry.docker-cn.com/library/elasticsearch③ 启动容器
elasticsearch默认会占用2G内存空间,这里启动的时候通过参数进行限制。另外9200是客户端服务器交互端口,9300是集群之间交互端口。
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 --name ES01 bbb1111fe3d3(镜像id)![]()
使用浏览器进行测试:

【4】几个重要概念
假设一个业务需求就是存储雇员数据。 这将会以 雇员文档 的形式存储:一个文档代表一个雇员。存储数据到 Elasticsearch 的行为叫做 索引 ,但在索引一个文档之前,需要确定将文档存储在哪里。
一个 Elasticsearch 集群可以 包含多个 索引 ,相应的每个索引可以包含多个 类型 。 这些不同的类型存储着多个 文档 ,每个文档又有 多个 属性 。
索引 这个词在 Elasticsearch 语境中包含多重意思其相关说明如下。
索引(名词):
如前所述,一个 索引 类似于传统关系数据库中的一个 数据库 ,是一个存储关系型文档的地方。 索引 (index) 的复数词为 indices 或 indexes 。
索引(动词):
索引一个文档 就是存储一个文档到一个 索引 (名词)中以便它可以被检索和查询到。这非常类似于 SQL 语句中的 INSERT 关键词,除了文档已存在时新文档会替换旧文档情况之外。
倒排索引:
关系型数据库通过增加一个 索引 比如一个 B树(B-tree)索引 到指定的列上,以便提升数据检索速度。Elasticsearch 和 Lucene 使用了一个叫做 倒排索引 的结构来达到相同的目的。
默认的,一个文档中的每一个属性都是 被索引 的(有一个倒排索引)和可搜索的。一个没有倒排索引的属性是不能被搜索到的。
类似关系:
索引—数据库
类型—表
文档—表中的记录
属性—列
图示如下:

Elasticsearch权威指南地址:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
【5】REST风格测试
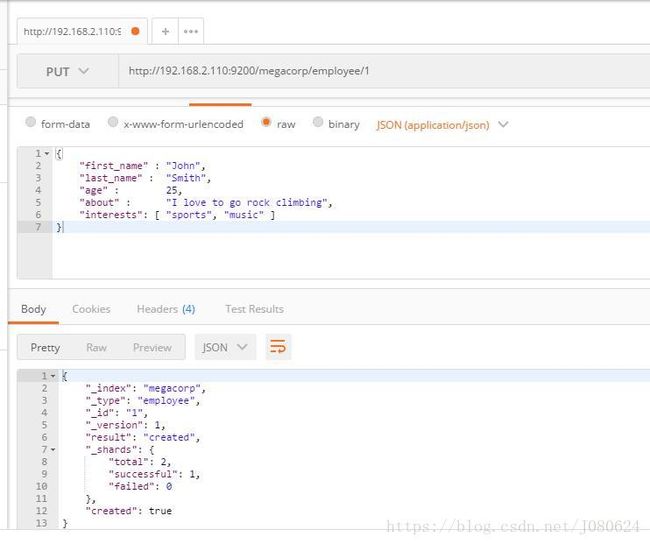
① PUT命令索引文档
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}使用Postman测试如下:
同样添加另外两条数据:
PUT /megacorp/employee/2
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
PUT /megacorp/employee/3
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}② GET命令检索文档
执行 一个 HTTP GET 请求并指定文档的地址——索引库、类型和ID。 使用这三个信息可以返回原始的 JSON 文档:
GET /megacorp/employee/1返回结果包含了文档的一些元数据,以及 _source 属性,其内容为原始 JSON 文档:

③ Head命令检查文档是否存在
HEAD /megacorp/employee/1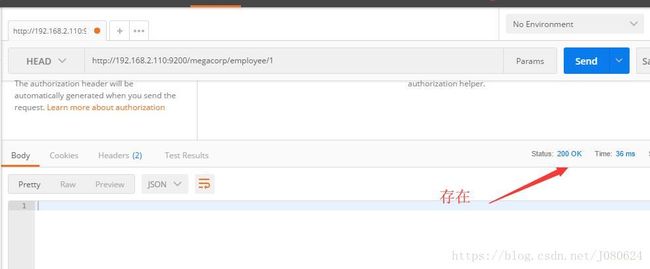
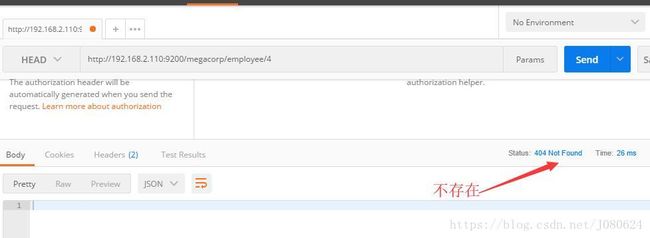
④ DELETE命令删除文档
DELETE /megacorp/employee/1⑤ _search 搜索所有数据
使用下列请求来搜索所有雇员:
GET /megacorp/employee/_search可以看到,我们仍然使用索引库 megacorp 以及类型 employee,但与指定一个文档 ID 不同,这次使用_search 。返回结果包括了所有三个文档,放在数组 hits 中。一个搜索默认返回十条结果。
{
"took": 91,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 1,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "3",
"_score": 1,
"_source": {
"first_name": "Douglas",
"last_name": "Fir",
"age": 35,
"about": "I like to build cabinets",
"interests": [
"forestry"
]
}
}
]
}
}注意:返回结果不仅告知匹配了哪些文档,还包含了整个文档本身:显示搜索结果给最终用户所需的全部信息。
⑥ URL参数条件查找
一般涉及到一个 查询字符串 (query-string) 搜索,通过一个URL参数来传递查询信息给搜索接口:
GET /megacorp/employee/_search?q=last_name:Smith我们仍然在请求路径中使用 _search 端点,并将查询本身赋值给参数 q= 。返回结果给出了所有的 Smith:
{
"took": 31,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.2876821,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 0.2876821,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.2876821,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
}
]
}
}⑦ 查询表达式搜索
Query-string 搜索通过命令非常方便地进行临时性的即席搜索 ,但它有自身的局限性(参见 官方文档轻量搜索 )。Elasticsearch 提供一个丰富灵活的查询语言叫做 查询表达式 , 它支持构建更加复杂和健壮的查询。
领域特定语言 (DSL), 指定了使用一个 JSON 请求。我们可以像这样重写之前的查询所有 Smith 的搜索 :
POST /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}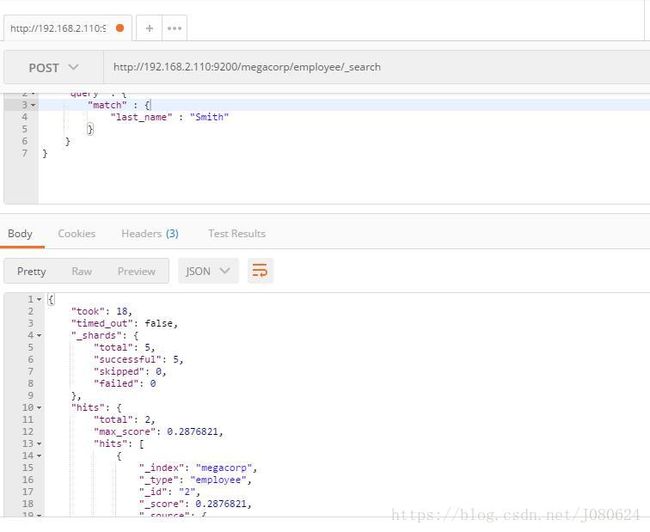
返回结果与之前的查询一样,但还是可以看到有一些变化。其中之一是,不再使用 query-string 参数,而是一个请求体替代。这个请求使用 JSON 构造,并使用了一个 match 查询。
⑧ 查询表达式复杂搜索
现在尝试下更复杂的搜索。 同样搜索姓氏为 Smith 的雇员,但这次我们只需要年龄大于 30 的。查询需要稍作调整,使用过滤器 filter ,它支持高效地执行一个结构化查询。
POST /megacorp/employee/_search
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}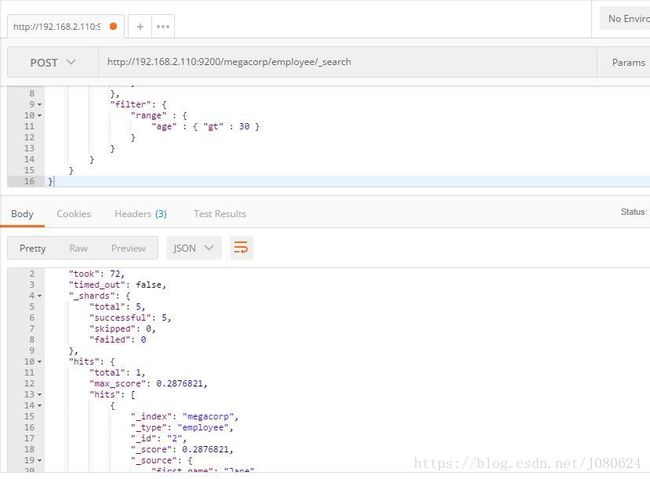
总结如下:
这部分与我们之前使用的 match 查询 一样。
这部分是一个 range 过滤器 , 它能找到年龄大于 30 的文档,其中 gt 表示_大于(_great than)。
⑨ 全文搜索
截止目前的搜索相对都很简单:单个姓名,通过年龄过滤。现在尝试下稍微高级点儿的全文搜索——一项 传统数据库确实很难搞定的任务。
搜索下所有喜欢攀岩(rock climbing)的雇员:
POST /megacorp/employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}显然我们依旧使用之前的 match 查询在about 属性上搜索 “rock climbing” 。得到两个匹配的文档:
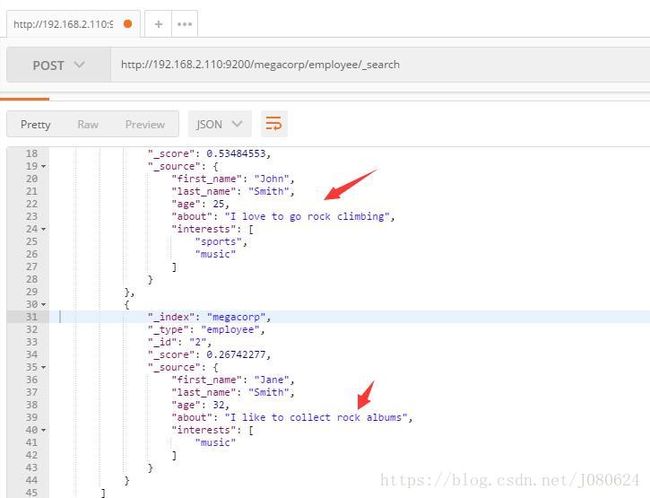
Elasticsearch 默认按照相关性得分排序,即每个文档跟查询的匹配程度。第一个最高得分的结果很明显:John Smith 的 about 属性清楚地写着 “rock climbing” 。
但为什么 Jane Smith 也作为结果返回了呢?原因是她的 about 属性里提到了 “rock” 。因为只有 “rock” 而没有 “climbing” ,所以她的相关性得分低于 John 的。
这是一个很好的案例,阐明了 Elasticsearch 如何 在 全文属性上搜索并返回相关性最强的结果。Elasticsearch中的 相关性 概念非常重要,也是完全区别于传统关系型数据库的一个概念,数据库中的一条记录要么匹配要么不匹配。
⑩ 短语搜索
找出一个属性中的独立单词是没有问题的,但有时候想要精确匹配一系列单词或者短语 。 比如, 我们想执行这样一个查询,仅匹配同时包含 “rock” 和 “climbing” ,并且 二者以短语 “rock climbing” 的形式紧挨着的雇员记录。
为此对 match 查询稍作调整,使用一个叫做 match_phrase 的查询:
POST /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}
毫无悬念,返回结果仅有 John Smith 的文档。

(11)高亮搜索
许多应用都倾向于在每个搜索结果中 高亮 部分文本片段,以便让用户知道为何该文档符合查询条件。在 Elasticsearch 中检索出高亮片段也很容易。
再次执行前面的查询,并增加一个新的 highlight 参数:
POST /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}当执行该查询时,返回结果与之前一样,与此同时结果中还多了一个叫做 highlight 的部分。这个部分包含了 about 属性匹配的文本片段,并以 HTML 标签封装:

更多内容参考官方文档:Elasticsearch权威指南