Introduction to Convex Optimization Basic Concepts 详细
往期文章链接目录
文章目录
- 往期文章链接目录
- Optimization problem
- Optimization Categories
- Different initialization brings different optimum (if not convex)
- Affine sets
- Affine combination
- Affine hull
- Convex Sets
- Convex combination
- Convex hull
- Cones
- Hyperplanes and halfspaces
- Polyhedra
- Linearly Independent v.s. Affinely Independent
- Simplexes
- What is the key distinction between a convex hull and a simplex?
- Convex Functions
- First-order conditions
- Second-order conditions
- Examples of Convex and Concave Functions
- 往期文章链接目录
Optimization problem
All optimization problems can be written as:

Optimization Categories
-
convex v.s. non-convex
Deep Neural Network is non-convex -
continuous v.s.discrete
Most are continuous variable; tree structure is discrete -
constrained v.s. non-constrained
We add prior to make it a constrained problem -
smooth v.s.non-smooth
Most are smooth optimization
Different initialization brings different optimum (if not convex)
Idea: Give up global optimal and find a good local optimal.
-
Purpose of pre-training: Find a good initialization to start training, and then find a better local optimal.
-
Relaxation: Convert to a convex optimization problem.
-
Brute force: If a problem is small, we can use brute force.
Affine sets
A set C ⊆ R n C \subseteq \mathbf R^n C⊆Rn is affine if the line through any two distinct points in C C C lies in C C C, i.e., if for any x 1 x1 x1, x 2 ∈ C x2 \in C x2∈C and θ ∈ R \theta \in \mathbf R θ∈R, we have θ x 1 + ( 1 − θ ) x 2 ∈ C . \theta x_1 + (1-\theta) x_2 \in C. θx1+(1−θ)x2∈C.
Note: The line passing throught x 1 x_1 x1 and x 2 x_2 x2: y = θ x 1 + ( 1 − θ ) x 2 y=\theta x_1 + (1-\theta)x_2 y=θx1+(1−θ)x2.
Affine combination
We refer to a point of the form θ 1 x 1 + θ 2 x 2 + . . . + θ k x k \theta_1 x_1 + \theta_2 x_2 + ... + \theta_k x_k θ1x1+θ2x2+...+θkxk, where θ 1 + θ 2 + . . . + θ k = 1 \theta_1 + \theta_2 + ... + \theta_k = 1 θ1+θ2+...+θk=1 as an affine combination of the points x 1 , x 2 , . . . , x k x_1, x_2, ..., x_k x1,x2,...,xk. An affine set contains every affine combination of its points.
Affine hull
The set of all affine combinations of points in some set C ⊆ R n C \subseteq \mathbf R^n C⊆Rn is called the affine hull of C C C, and denoted a f f C \mathbf{aff}\, C affC:
a f f C = { θ 1 x 1 + θ 2 x 2 + . . . + θ k x k ∣ x 1 , x 2 , . . . , x k ∈ C , θ 1 + θ 2 + . . . + θ k = 1 } . \mathbf{aff}\, C =\{\theta_1 x_1 + \theta_2 x_2 + ... + \theta_k x_k \, | x_1, x_2, ..., x_k \in C, \theta_1 + \theta_2 + ... + \theta_k = 1\}. affC={θ1x1+θ2x2+...+θkxk∣x1,x2,...,xk∈C,θ1+θ2+...+θk=1}.
The affine hull is the smallest affine set that contains C C C, in the following sense: if
S S S is any affine set with C ⊆ S C \subseteq S C⊆S, then aff C ⊆ S \operatorname{aff} C \subseteq S affC⊆S.
Affine dimension: We define the affine dimension of a set C C C as the dimension of its affine hull.
Convex Sets
A set C C C is convex if the line segment between any two points in C C C lies in C C C, i.e., if for any x 1 x1 x1, x 2 ∈ C x2 \in C x2∈C and any θ \theta θ with 0 ≤ θ ≤ 1 0 \leq \theta \leq 1 0≤θ≤1, we have
θ x 1 + ( 1 − θ ) x 2 ∈ C . \theta x_1 + (1-\theta) x_2 \in C. θx1+(1−θ)x2∈C.
Roughly speaking, a set is convex if every point in the set can be seen by every other
point. Every affine set is also convex, since it contains the entire line between any two distinct points in it, and therefore also the line segment between the points.
Convex combination
We call a point of the form θ 1 x 1 + θ 2 x 2 + . . . + θ k x k \theta_1 x_1 + \theta_2 x_2 + ... + \theta_k x_k θ1x1+θ2x2+...+θkxk, where θ 1 + θ 2 + . . . + θ k = 1 \theta_1 + \theta_2 + ... + \theta_k = 1 θ1+θ2+...+θk=1 and θ i ≥ 0 , i = 1 , 2 , . . . k \theta_i \geq 0, i = 1,2,...k θi≥0,i=1,2,...k, a convex combination of the points x 1 , . . . , x k x_1, ..., x_k x1,...,xk.
Convex hull
The convex hull of a set C C C, denoted c o n v C \mathbf{conv} \, C convC, is the set of all convex combinations of points in C C C:
c o n v C = { θ 1 x 1 + θ 2 x 2 + . . . + θ k x k ∣ x i ∈ C , θ i ≥ 0 , i = 1 , . . . , k , θ 1 + θ 2 + . . . + θ k = 1 } . \mathbf{conv}\, C =\{\theta_1 x_1 + \theta_2 x_2 + ... + \theta_k x_k \, | x_i \in C, \theta_i \geq 0, i=1,...,k, \theta_1 + \theta_2 + ... + \theta_k = 1\}. convC={θ1x1+θ2x2+...+θkxk∣xi∈C,θi≥0,i=1,...,k,θ1+θ2+...+θk=1}.
The convex hull conv C \operatorname{conv} C convC is always convex. It is the smallest convex set that contains C C C: If B B B is any convex set that contains C C C, then conv C ⊆ B \operatorname{conv} C \subseteq B convC⊆B.
Cones
A set C C C is called a cone, or nonnegative homogeneous, if for every x ∈ C x \in C x∈C and θ ≥ 0 \theta \geq 0 θ≥0 we have θ x ∈ C \theta x \in C θx∈C. A set C C C is a convex cone if it is convex and a cone, which means that for any x 1 , x 2 ∈ C x_1, x_2 \in C x1,x2∈C and θ 1 , θ 2 ≥ 0 \theta_1, \theta_2 \geq 0 θ1,θ2≥0, we have
θ 1 x 1 + θ 2 x 2 ∈ C \theta_1 x_1 + \theta_2 x_2 \in C θ1x1+θ2x2∈C

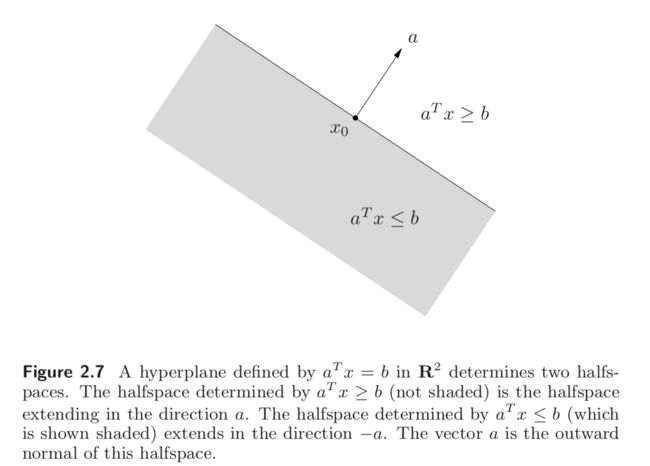
Hyperplanes and halfspaces
A hyperplane is a set of the form
{ x ∣ a T x = b } , \{ x \, | a^T x = b\}, {x∣aTx=b},
where a ∈ R n , a ≠ 0 a \in \mathbf R^n, a \neq 0 a∈Rn,a=0, and b ∈ R b \in \mathbf R b∈R.
This geometric interpretation can be understood by expressing the hyperplane in the form
{ x ∣ a T ( x − x 0 ) = 0 } , \{ x \, | a^T (x - x_0) = 0\}, {x∣aT(x−x0)=0},
where x 0 x_0 x0 is any point in the hyperplane.
A hyperplane divides R n \mathbf R^n Rn into two halfspaces. A (closed) halfspace is a set of the form
{ x ∣ a T x ≤ b } . \{x \, | a^T x \leq b \}. {x∣aTx≤b}.
where x 0 ≠ 0 x_0 \neq 0 x0=0. Halfspaces are convex but not affine. The set $ {x | a^T < b }$ is called an open halfspace.
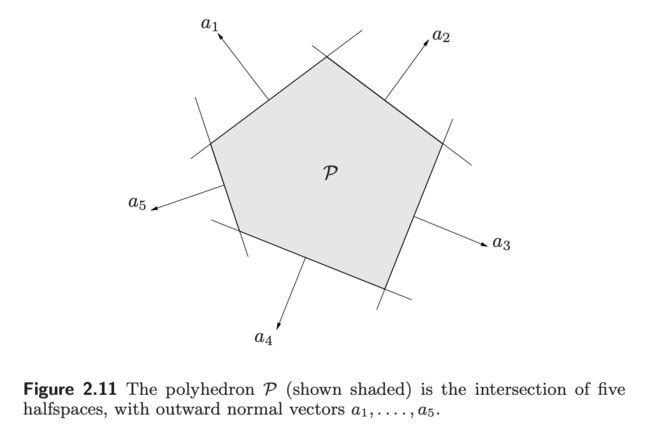
Polyhedra
A polyhedron is defined as the solution set of a finite number of linear equalities and inequalities:
P = { x ∣ a j T ≤ b j , j = 1 , . . . , m , c j T x = d j , j = 1 , . . . , p } P = \{ x\, | a_j^T \leq b_j, j=1,...,m, c_j^T x = d_j, j = 1, ..., p\} P={x∣ajT≤bj,j=1,...,m,cjTx=dj,j=1,...,p}
A polyhedron is thus the intersection of a finite number of halfspaces and hyperplanes. Here is the compact notations:
P = { x ∣ A x ⪯ b , C x = d } P = \{ x\, | Ax \preceq b, Cx=d\} P={x∣Ax⪯b,Cx=d}
Linearly Independent v.s. Affinely Independent
Consider the vectors (1,0), (0,1) and (1,1). These are affinely independent, but not independent. If you remove any one of them, their affine hull has dimension one. In contrast, the span of any two of them is all of R 2 \mathbf R^2 R2, and hence these are not independent.
Simplexes
Suppose the k + 1 k+1 k+1 points v 0 , . . . , v k ∈ R n v_0, ..., v_k \in \mathbf R^n v0,...,vk∈Rn are affinely independent, which means v 1 − v 0 , . . . , v k − v 0 v_1 - v_0, ..., v_k - v_0 v1−v0,...,vk−v0 are linearly independent. The simplex determined by them is given by
C = c o n v { v 0 , . . . , v k } = { θ 0 v 0 + . . . + θ k v k ∣ θ ⪰ 0 , 1 T θ = 1 } C = \mathbf{conv}\{ v_0, ..., v_k\} = \{ \theta_0 v_0 + ... + \theta_k v_k \,| \theta \succeq 0, \mathbf 1^T \theta = 1\} C=conv{v0,...,vk}={θ0v0+...+θkvk∣θ⪰0,1Tθ=1}
Note:
- The affine dimension of this simplex is k k k.
A 1-dimensional simplex is a line segment; a 2-dimensional simplex is a triangle (including its interior); and a 3-dimensional simplex is a tetrahedron.
What is the key distinction between a convex hull and a simplex?
If the elements of the set on which the convex hull is defined are affinely independent, then the convex hull and the simplex defined on this set are the same. Otherwise, simplex can’t be defined on this set, but convex hull can.
Convex Functions
- A function f : R n → R f: \mathbf{R}^n \rightarrow \mathbf{R} f:Rn→R is convex if dom f f f is a convex set and if for all x x x, y ∈ d o m f y \in \mathbf{dom} \, f y∈domf, and θ \theta θ with $ 0 \leq \theta \leq 1$, we have
f ( θ x + ( 1 − θ ) y ) ≤ θ f ( x ) + ( 1 − θ ) f ( y ) . f(\theta x + (1-\theta)y) \leq \theta f(x) + (1-\theta) f(y). f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y).
-
We say f f f is concave is − f -f −f is convex, and strictly concave if − f -f −f is strictly convex.
-
A function is convex if and only if it is convex when restricted to any line that intersects its domain. In other words f is convex if and only if for all x ∈ d o m f x \in \mathbf{dom} \, f x∈domf and all v v v, the function g ( t ) = f ( x + t v ) g(t) = f(x + tv) g(t)=f(x+tv) is convex (on its domain, { t ∣ x + t v ∈ d o m f } \{t \, | \, x + tv \in \mathbf{dom} \, f \} {t∣x+tv∈domf}).
First-order conditions
- Suppose f f f is differentiable, then f f f is convex if and only if d o m f \mathbf{dom} \, f domf is convex and
f ( y ) ≥ f ( x ) + ∇ f ( x ) T ( y − x ) f(y) \geq f(x) + \nabla f(x)^{T}(y-x) f(y)≥f(x)+∇f(x)T(y−x) holds for all x , y ∈ d o m f x,y \in \mathbf{dom} \, f x,y∈domf

-
For a convex function, the first-order Taylor approximation is in fact a global underestimator of the function. Conversely, if the first-order Taylor approximation of a function is always a global underestimator of the function, then the function is convex.
-
The inequality shows that from local information about a convex function (i.e., its value and derivative at a point) we can derive global information (i.e., a global underestimator of it).
Second-order conditions
-
Suppose that f f f is twice differentiable. The f f f is convex if and only if d o m f \mathbf{dom} \, f domf is convex and its Hessian is positive semidefinite: for all x ∈ d o m f x \in \mathbf{dom} f x∈domf,
∇ 2 f ( x ) ⪰ 0. \nabla^2f(x) \succeq 0. ∇2f(x)⪰0. -
f f f is concave if and only if d o m f \mathbf{dom} f domf is convex and ∇ 2 f ( x ) ⪯ 0 \nabla^2f(x) \preceq 0 ∇2f(x)⪯0 for all x ∈ d o m f x \in \mathbf{dom} \, f x∈domf.
-
If $ \nabla^2f(x) \succ 0$ for all x ∈ d o m f x \in \mathbf{dom} \, f x∈domf, then f f f is strictly convex. The converse is not true. e.x. f ( x ) = x 4 f(x) = x^4 f(x)=x4 has zero second derivative at x = 0 x=0 x=0 but is strictly convex.
-
Quadratic functions: Consider the quadratic function f : R n → R f:\mathbf{R}^n \rightarrow \mathbf{R} f:Rn→R, with d o m f = R n \mathbf{dom} \, f = \mathbf{R}^n domf=Rn, given by
f ( x ) = ( 1 / 2 ) x T P x + q T x + r , f(x) = (1/2)x^{T}Px + q^Tx + r, f(x)=(1/2)xTPx+qTx+r,
with P ∈ S n , q ∈ R n P \in \mathbf{S}^n, q \in \mathbf R^n P∈Sn,q∈Rn, and r ∈ R r \in \mathbf{R} r∈R. Since ∇ 2 f ( x ) = P \nabla^2f(x) = P ∇2f(x)=P for all x, f is convex if and only if P ⪰ 0 P \succeq 0 P⪰0 (and concave if and only if P ⪯ 0 P \preceq 0 P⪯0).
Examples of Convex and Concave Functions
-
Exponential. e a x e^{ax} eax is convex on R \mathbf{R} R, for any a ∈ R a \in \mathbf{R} a∈R.
-
Powers. x a x^a xa is convex on R + + \mathbf R_{++} R++ when a ≥ 1 a \geq 1 a≥1 or a ≤ 0 a \leq 0 a≤0, and concave for 0 ≤ a ≤ 1 0 \leq a \leq 1 0≤a≤1.
-
Powers of absolute value. ∣ x ∣ p |x|^p ∣x∣p, for p ≥ 1 p \geq 1 p≥1, is convex on R \mathbf R R.
-
Logarithm. l o g x log \, x logx is concave on R + + R_{++} R++.
-
Negative Entropy. x l o g x x\,log\,x xlogx (either on R + + \mathbf{R}_{++} R++, or on R + \mathbf R_+ R+, defined as 0 0 0 for x = 0 x = 0 x=0) is convex.
-
Norms. Every norm on R n \mathbf{R}^n Rn is convex.
-
Max function. f ( x ) = m a x { x 1 , . . . , x n } f(x) = max \{ x_1, ..., x_n\} f(x)=max{x1,...,xn} is convex on R n \mathbf R^n Rn.
-
Quadratic-over-linear function. The function f ( x , y ) = x 2 / y f(x,y) = x^2/y f(x,y)=x2/y, with
d o m f = R × R + + = { ( x , y ) ∈ R 2 ∣ y > 0 } , \mathbf{dom} \, f = \mathbf R \times \mathbf R_{++} = \{ (x,y) \in \mathbf R^2\, | y > 0\}, domf=R×R++={(x,y)∈R2∣y>0}, is convex. -
Log-sum-exp. The function f ( x ) = l o g ( e x 1 + ⋅ ⋅ ⋅ + e x n ) f(x) = log (e^{x_1} + · · · + e^{x_n} ) f(x)=log(ex1+⋅⋅⋅+exn) is convex on R n \mathbf R^n Rn.
-
Geometric mean. The geometric mean f ( x ) = ( ∏ i = 1 n x i ) 1 / n f(x) = (\prod^n_{i = 1} x_i)^{1/n} f(x)=(∏i=1nxi)1/n is concave on d o m f = S + + n \mathbf {dom} \, f = \mathbf S^n_{++} domf=S++n
-
Log-determinant. The function f ( X ) = l o g d e t X f(X) =\mathrm{log \, det \,} X f(X)=logdetX is concave.
Reference: Convex Optimization by Stephen Boyd and Lieven Vandenberghe.