实战篇之二:使用class_name定位多页信息
经过上一篇介绍,我们已经基本完成了我们的目标,但其中还存在很多问题:
1、页面时动态的,更新了当前Xpath路径就不再指向刚才的目标了
2、如何爬取整一页,爬取多页操作
通过本篇文章将进行一一解答上述存在的问题
首先来分析页面Xpath路径的特点,想要知道内在关系,只好一层一层剥开
先以两个利好的Xpath为例子进行比较

Xpath路径:
/html/body/div/div[2]/div/div[1]/section/section[2]/section/div/div[2]/div[2]/ul/li[10]/div[2]/div/div[1]/div[1]/span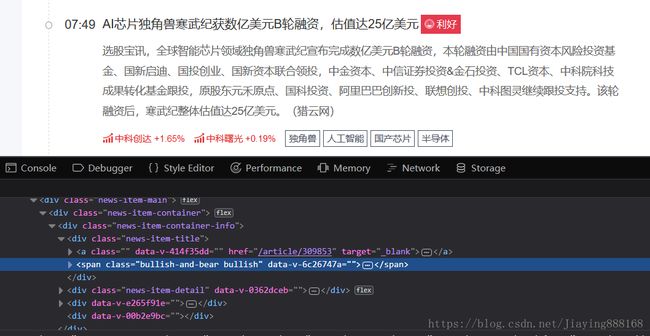
Xpath路径:
/html/body/div/div[2]/div/div[1]/section/section[2]/section/div/div[2]/div[2]/ul/li[28]/div[2]/div/div[1]/div[1]/span通过比较我们发现不同利好对应不同的li标签,有这个规律爬取一个网页一页就好办了,从第一个开始遍历即可
![]()
from selenium import webdriver
import time
import re
from pyquery import PyQuery
driver = webdriver.Firefox()#打开浏览器
driver.maximize_window()#最大化浏览器
driver.get("https://xuangubao.cn/")#目标网站
index = 1
for index in range(index,index*21):
try:
bullish = driver.find_element_by_xpath("//li["+str(index)+"]/div/div/div/div/span[1]")#为了简便好看,此处采用相对路径方式
print(bullish.text)#输出标签
except:
print("当前路径找不到目标,正在继续爬取下一个目标")
continue以上代码解决了爬取一页“利好”标签的缺陷,注意:网页li标签的下标是从1开始的,所以index一开始为1
继续爬取属于利好标签下的股票
from selenium import webdriver
import time
import re
from pyquery import PyQuery
driver = webdriver.Firefox()#打开浏览器
driver.maximize_window()#最大化浏览器
driver.get("https://xuangubao.cn/")#目标网站
index = 1
for index in range(index,index*24):
try:
bullish = driver.find_element_by_xpath("//li["+str(index)+"]/div/div/div/div/span[1]")#为了简便好看,此处采用相对路径方式
index1 = 1
try:
while(1):
stock = driver.find_element_by_xpath("//li["+str(index)+"]/div/div/div/div/div/ul/li["+str(index1)+"]/a/span[1]")#循环爬取利好股票,直到不存在
index1 += 1
print("利好股票:"+stock.text)
except:
pass#当前路径找不到股票,跳过此循环,也就是没有股票了
except:
continue#当前路径找不到利好图标,继续循环寻找下一个利好以上代码完整的爬取了一页利好股票的信息

下面介绍点击事件,在页面的底部有一个点击加载更多的按钮

首先我们还是要定位到当前按钮,找出class_name,即采用class名字定位,因为采用Xpath路径多变的,而class_name则一成不变,我们只需要在定位代码后面添加点击操作即可
driver.find_element_by_class_name("home-news-footer").click()所以想要爬取多少页就点击多少次就行啦
from selenium import webdriver
import time
import re
from pyquery import PyQuery
driver = webdriver.Firefox()#打开浏览器
driver.maximize_window()#最大化浏览器
driver.get("https://xuangubao.cn/")#目标网站
for num in range(1,101):#加载多次
driver.find_element_by_class_name("home-news-footer").click()#加载更多
index = 1
for index in range(index,num*25):#寻找多个页面数据
try:
bullish_and_bear = driver.find_element_by_xpath("//li["+str(index)+"]/div/div/div/div/span[1]")#为了简便好看,此处采用相对路径方式
index1 = 1
try:
while(1):
stock = driver.find_element_by_xpath("//li["+str(index)+"]/div/div/div/div/div/ul/li["+str(index1)+"]/a/span[1]")#循环爬取利好股票,直到不存在
index1 += 1
if(bullish_and_bear.text == '利好'):
print("利好股票:"+stock.text)
elif(bullish_and_bear.text == '利空'):
print("利空股票:"+stock.text)
except:
pass#当前路径找不到股票,跳过此循环,也就是没有股票了
except:
continue#当前路径找不到利好图标,继续循环寻找下一个利好
至此所有工作已经完成,后续可将所有利好股票存于文本中,以供以后研究
本博客以后将会分享关于嵌入式软件方面的知识(stm32+ARM)和物联网解决方案(智能家居)