手把手和你抓取博客园(cnblog)的200页博客数据
教科书版手写多线程爬虫抓取博客园首页的200页数据, 涉及多线程, 又开始考验我的JAVA线程基础啦, 还记得当初大二写一个min爬虫框架, 一多线程就挂, 各种问题, 哈哈哈 这次也算是完成一年前的一个小目标吧…
上一个智联的爬虫就暂停一下, 昨天有一个朋友说觉得爬虫有点意思, 然后想尝试抓取一下, 但是遇到了不少问题, 比较经典的就是如下问题啦
"为什么你用gradle构建项目?">> gradle是大势所趋, 国外很多项目都是gradle构建了
"为什么你知道是这个url返回数据的">> 嗯呐嗯呐, 再怎么说我也算是有一年多的爬虫经验的人(业务)才(爱好者)好嘛
"你说url会变化, 我怎么看都是一个url, 怎么肥事?">> 我看看是什么流弊的网站先, 后面讲到
"你抓取返回来的是JSON数据, 为什么我的带有HTML标签的?">> 这就说明这个网站接口不是绝对前后端分离啦
其实我原本五一是玩一下自己的小项目的, 但是他叫我搞一下, 所以一大早起来就帮忙写一下了, 所以新故事就这么开始啦…
二话不说, 昨晚他就发来一个链接https://www.cnblogs.com/, 我一看到cnblog, 咦, 这不是博客园吗?我的天, 胃口还不小, 一写爬虫就搞博客园, 博客园那里得罪你了[捂脸]
故事背景来源于一次交流…
下面考虑实现的问题啦
步骤1 : 打开博客园
https://www.cnblogs.com/
步骤2 : 浏览器抓包
详情抓包步骤请浏览器下图, 很多细节都在图说明了, 有浏览器步骤 0 1 2 3 4等

说明:
- url : https://www.cnblogs.com/mvc/AggSite/PostList.aspx
- 我们就可以猜到博客园的后台是使用微软的 .NET
- 查看请求体就知道了是JSON, 然后参数是
{“CategoryId”: 808, “CategoryType”: “SiteHome”, “ItemListActionName”: “PostList”, “PageIndex”: 2, “ParentCategoryId”: 0, “TotalPostCount”: 4000}
所以改变PageIndex就是改变了页数了, 注意页数是1开始- CategoryId: 808
- CategoryType: “SiteHome”
- ItemListActionName: “PostList”
- PageIndex: 2
- ParentCategoryId: 0
- TotalPostCount: 4000
步骤3 : 网络请求获取接口数据
根据上一步骤, 知道了请求的实体是JSON, 那么我们就可以知道了请求的参数了, 下面就是使用我封装的一个工具类HttpUtil,
调用
doPost(String url, Map
具体请看源码使用
/**
* 请求网页源码
*/
public String getHtml(int pageIndex){
System.err.println("正在请求页数:" + pageIndex);
Map<String, Object> body = new HashMap<>(8);
String JSONStr = "{\"CategoryId\": 808, \"CategoryType\": \"SiteHome\", \"ItemListActionName\": \"PostList\", \"PageIndex\": %d, \"ParentCategoryId\": 0, \"TotalPostCount\": 4000}";
JSONStr = String.format(JSONStr, pageIndex);
body.put("JSON", JSONStr);
// String url, Map header, int postType, Map body, String bodyCharset, Map proxy, String htmlCharset
String html = httpUtil.doPost(BASE_URL, DEFAULT_HEADER, HttpUtil.PostType.JSON, body, "UTF-8", null, "UTF-8");
System.out.println(html);
return html;
}
控制台输出
<div class="post_item">
<div class="digg">
<div class="diggit" onclick="DiggPost('edison0621',10805354,152901,1)">
<span class="diggnum" id="digg_count_10805354">1</span>
</div>
<div class="clear"></div>
<div id="digg_tip_10805354" class="digg_tip"></div>
</div>
<div class="post_item_body">
<h3><a class="titlelnk" href="https://www.cnblogs.com/edison0621/p/10805354.html" target="_blank">微服务探索与实践—服务注册与发现</a></h3>
<p class="post_item_summary">
<a href="https://www.cnblogs.com/edison0621/" target="_blank"><img width="48" height="48" class="pfs" src="//pic.cnblogs.com/face/533598/20130529110206.png" alt=""/></a> 前言 微服务从大规模使用到现在已经有很多年了,从之前的探索到一步步的不断完善与成熟,微服务已经成为众多架构选择中所必须面对的一个选项。服务注册与发现是相辅相成的,所以一般会合起来思索。其依托组件有很多,比如Zookeeper,Consul,Eureka等等。 本文,我们将探讨服务注册和发现的概念及其 ...
</p>
<div class="post_item_foot">
<a href="https://www.cnblogs.com/edison0621/" class="lightblue">艾心❤</a>
发布于 2019-05-03 15:44
<span class="article_comment"><a href="https://www.cnblogs.com/edison0621/p/10805354.html#commentform" title="2019-05-03 16:39" class="gray">
评论(1)</a></span><span class="article_view"><a href="https://www.cnblogs.com/edison0621/p/10805354.html" class="gray">阅读(116)</a></span></div>
</div>
<div class="clear"></div>
</div>
省略...
<div class="post_item">
<div class="digg">
<div class="diggit" onclick="DiggPost('pythonista',10803387,485203,1)">
<span class="diggnum" id="digg_count_10803387">0</span>
</div>
<div class="clear"></div>
<div id="digg_tip_10803387" class="digg_tip"></div>
</div>
<div class="post_item_body">
<h3><a class="titlelnk" href="https://www.cnblogs.com/pythonista/p/10803387.html" target="_blank">听说苏州是互联网的荒漠,真的吗?</a></h3>
<p class="post_item_summary">
我国互联网存在着巨大的地域性偏差,除了北上广深杭外,其它省市的互联网都很弱小。去年 8 月,某个公众号发布了一篇《上海不相信互联网》的文章,引起了多方的讨论。CSDN 公众号以此为契机,陆续发布了关于南京、东北、西安、甚至德国等地的互联网发展情况的文章。 作为一个“苏漂”程序员,我有幸得到了 CSD ...
</p>
<div class="post_item_foot">
<a href="https://www.cnblogs.com/pythonista/" class="lightblue">豌豆花下猫</a>
发布于 2019-05-02 21:05
<span class="article_comment"><a href="https://www.cnblogs.com/pythonista/p/10803387.html#commentform" title="" class="gray">
评论(0)</a></span><span class="article_view"><a href="https://www.cnblogs.com/pythonista/p/10803387.html" class="gray">阅读(437)</a></span></div>
</div>
<div class="clear"></div>
</div>
步骤4 : 解析HTML数据
这里使用了Jsoup模块, 解析HTML的工具有很多, 还有很多, 我比较习惯Jsoup、htmlcleaner、XPath(webmagic封装的jsoup)
// 导入Jsonp依赖
compile group: ‘org.jsoup’, name: ‘jsoup’, version: ‘1.11.2’
代码如下:
/**
* 解析HTML
*/
public Object process(int pageIndex) {
String html = getHtml(pageIndex);
Document document = Jsoup.parse(html);
Elements post_items = document.getElementsByClass("post_item");
post_items.forEach( v -> {
Element titlelnk = v.selectFirst(".titlelnk");
// 文章标题
String title = titlelnk.text();
// 详情连接
String href = titlelnk.attr("href");
// 文章摘要
String summary = v.selectFirst(".post_item_summary").text();
// 所属作者
String lightblue = v.selectFirst(".lightblue").text();
// 发布时间
String time = v.selectFirst(".post_item_foot").text();
time = easyUtil.subStringBetween(time, "发布于 ", " 评论");
// 评论人数
String comment = v.selectFirst(".article_comment > .gray").text();
comment = comment.replace("评论(", "").replace(")", "");
// 阅读人数
String view = v.selectFirst(".article_view > .gray").text();
view = view.replace("阅读(", "").replace(")", "");
Map<String, Object> dataMap = new LinkedHashMap<>(8);
dataMap.put("文章标题", title);
dataMap.put("详情连接", href);
dataMap.put("文章摘要", summary);
dataMap.put("所属作者", lightblue);
dataMap.put("发布时间", time);
dataMap.put("评论人数", comment);
dataMap.put("阅读人数", view);
System.out.println(dataMap);
if (iscreatetableflag == 0){
synchronized (CnblogSpider.class){
// 确保只创建一次表
if (iscreatetableflag == 0){
DbUtil.createTable(tableName, dataMap.keySet().toArray(new String[]{}));
iscreatetableflag = 1;
}
}
}
DbUtil.insertData(tableName, dataMap);
});
System.out.println("解析完成页数:" + pageIndex);
return null;
}
控制台输出
{文章标题=004-python-列表、元组、字典, 详情连接=https://www.cnblogs.com/David-domain/p/10807968.html, 文章摘要=1. 什么是列表 列表是一个可变的数据类型 列表由[]来表示, 每一项元素使用逗号隔开. 列表什么都能装. 能装对象的对象. 列表可以装大量的数据 2. 列表的索引和切片 列表和字符串一样. 也有索引和切片. 只不过切出来的内容是列表 索引的下标从0开始 [起始位置:结束位置:步长] 3. 列表的增 ..., 所属作者=do康解U, 发布时间=2019-05-04 11:26, 评论人数=0, 阅读人数=7}
省略...
{文章标题=物联网架构_对AWS的Greengrass的认识与理解, 详情连接=https://www.cnblogs.com/Tiancheng-Duan/p/10804804.html, 文章摘要=物联网架构_对AWS的Greengrass的认识与理解 一,前言: 这段时间有许多的收获,分析,还有总结,其中包括新系统的设计与开发,以及其中新技术的踩坑等等等。 但是最近真的很忙,项目的推进,面试工作等,尤其五月份还有考试。所以,赶紧趁着五一假期有些空暇,先发一些东西。之后,有机会再对自己的素材( ..., 所属作者=血夜之末, 发布时间=2019-05-04 10:50, 评论人数=0, 阅读人数=26}
步骤6 : 数据入库
这里使用一个封装的工具类DbUtil
// 表名, 数据Map, Key 对应表字段, Value 对应一行数据
DbUtil.insertData(tableName, dataMap);
步骤7 : 多线程并发
这里因为页数比较多,一共200页数, 之前也有人给我留言说, 单线程, 如何提升效率, 问我能够升级一下改为多线程.
所以这次就写一个多线程的爬虫,我个人的话如果写多线程的爬虫应该是使用webmagic, 一个参考python的scrapy的优秀框架, 非常不错, 上手也快, 多线程只需要改一个参数就可以了, 不需要考虑线程安全问题, 自己写的话难免会有小BUG
我这里使用了多线程写法比较简单, 代码如下:
定义实现类
class MyRun implements Runnable{
private int pageIndex;
public MyRun(int pageIndex) {
this.pageIndex = pageIndex;
}
@Override
public void run() {
CnblogSpider cnblogSpider = new CnblogSpider();
cnblogSpider.process(pageIndex);
}
}
使用如下
// 阻塞队列固定大小
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<Runnable>(200);
// 线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 20, 1, TimeUnit.HOURS, queue);
for (int i = 1; i < 201; i++) {
// 提交任务
executor.execute(new MyRun(i));
}
// 关闭线程池
executor.shutdown();
说明:我这里使用了2条核心线程数量corePoolSize, 如果需要提高线程数量, 改变corePoolSize即可, 也就是new ThreadPoolExecutor(2, …)中的2
不建议太高, 有可能会封IP的哦, 如果你有IP池的话就没问题啦, 顺便玩, 但是本着人道主义, 不建议过火啦~~~
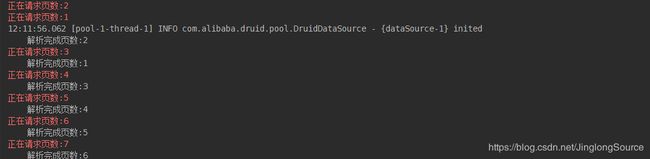
控制台输出如下:
步骤8 : 数据库展示
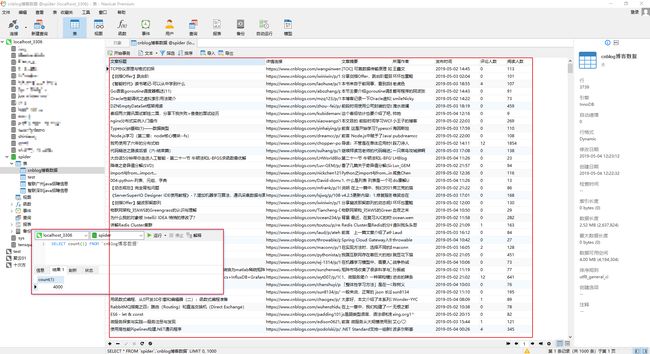
20 * 200 = 4000
所以看来数据没大问题, 比较顺利…
步骤9 : 献上整体代码
package cn.shaines.spider.module.cnblog;
import cn.shaines.spider.util.DbUtil;
import cn.shaines.spider.util.EasyUtil;
import cn.shaines.spider.util.HttpUtil;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
@SuppressWarnings("Duplicates")
public class CnblogSpider {
/**
* 简单工具类
*/
EasyUtil easyUtil = EasyUtil.get();
/**
* 网络请求工具类
*/
HttpUtil httpUtil = HttpUtil.get();
/**
* POST请求的链接
*/
private static final String BASE_URL = "https://www.cnblogs.com/mvc/AggSite/PostList.aspx";
/**
* 请求头参数
*/
private static final Map<String, Object> DEFAULT_HEADER = new HashMap<>(8);
/**
* 定义一个标识创建一次表
*/
private static volatile int iscreatetableflag = 0;
/**
* 定义表名
*/
private String tableName = "cnblog博客数据";
/**
* 解析HTML
*/
public Object process(int pageIndex) {
String html = getHtml(pageIndex);
Document document = Jsoup.parse(html);
Elements post_items = document.getElementsByClass("post_item");
post_items.forEach( v -> {
Element titlelnk = v.selectFirst(".titlelnk");
// 文章标题
String title = titlelnk.text();
// 详情连接
String href = titlelnk.attr("href");
// 文章摘要
String summary = v.selectFirst(".post_item_summary").text();
// 所属作者
String lightblue = v.selectFirst(".lightblue").text();
// 发布时间
String time = v.selectFirst(".post_item_foot").text();
time = easyUtil.subStringBetween(time, "发布于 ", " 评论");
// 评论人数
String comment = v.selectFirst(".article_comment > .gray").text();
comment = comment.replace("评论(", "").replace(")", "");
// 阅读人数
String view = v.selectFirst(".article_view > .gray").text();
view = view.replace("阅读(", "").replace(")", "");
Map<String, Object> dataMap = new LinkedHashMap<>(8);
dataMap.put("文章标题", title);
dataMap.put("详情连接", href);
dataMap.put("文章摘要", summary);
dataMap.put("所属作者", lightblue);
dataMap.put("发布时间", time);
dataMap.put("评论人数", comment);
dataMap.put("阅读人数", view);
//System.out.println(dataMap);
if (iscreatetableflag == 0){
synchronized (CnblogSpider.class){
// 确保只创建一次表
if (iscreatetableflag == 0){
DbUtil.createTable(tableName, dataMap.keySet().toArray(new String[]{}));
iscreatetableflag = 1;
}
}
}
DbUtil.insertData(tableName, dataMap);
});
System.out.println("\t解析完成页数:" + pageIndex);
return null;
}
/**
* 请求网页源码
*/
public String getHtml(int pageIndex){
System.err.println("正在请求页数:" + pageIndex);
Map<String, Object> body = new HashMap<>(8);
// 这里的JSONStr是根据抓包步骤中的请求实体得知, JSON格式为{"key1":value, "key2":value}
String JSONStr = "{\"CategoryId\": 808, \"CategoryType\": \"SiteHome\", \"ItemListActionName\": \"PostList\", \"PageIndex\": %d, \"ParentCategoryId\": 0, \"TotalPostCount\": 4000}";
JSONStr = String.format(JSONStr, pageIndex);
body.put("JSON", JSONStr);
// String url, Map header, int postType, Map body, String bodyCharset, Map proxy, String htmlCharset
String html = httpUtil.doPost(BASE_URL, DEFAULT_HEADER, HttpUtil.PostType.JSON, body, "UTF-8", null, "UTF-8");
//System.out.println("html = " + html);
return html;
}
public static void main(String[] args) {
DEFAULT_HEADER.put("referer", "https://www.cnblogs.com/");
DEFAULT_HEADER.put("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36");
DEFAULT_HEADER.put("origin", "https://www.cnblogs.com");
DEFAULT_HEADER.put("content-type", "application/json; charset=UTF-8");
// 阻塞队列固定大小
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<Runnable>(200);
// 线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4, 1, TimeUnit.HOURS, queue);
for (int i = 1; i < 201; i++) {
executor.execute(new MyRun(i));
}
executor.shutdown();
}
}
class MyRun implements Runnable{
private int pageIndex;
public MyRun(int pageIndex) {
this.pageIndex = pageIndex;
}
@Override
public void run() {
CnblogSpider cnblogSpider = new CnblogSpider();
cnblogSpider.process(pageIndex);
}
}
结束语
- 这里抓取了200页, 然后我尝试201页,发现返回的依旧是200页的数据, 所有有可能是后台限制了, 具体的就不探究了
- 这里我们就可以使用这些数据啦, 比如说塞选出阅读数量和评论数据比较高的, 然后在根据标题塞选出符合自己的文章,然后就可以每天发布几篇篇优质的技术文章了呀[奸笑]
- 这里还可以优化的就是写一个定时任务, 每隔几小时就去抓取一下, 然后入库, 甚至发布到自己的私服, 结合我之前的python wxpy, 每天定时微信发送自己几篇优质文章
- 好玩的还有很多, 就看大家怎么玩啦…
我的博客:
https://www.shaines.cn
讨论与交流:
[email protected]
[email protected]
