Recall || Precision || Average_precision(AP) || Intersection-over-Union(IoU)||NMS
||召回率(Recall)||
||精确率(Precision)||
||平均正确率Average_precision(AP) ||
||交除并(Intersection-over-Union(IoU))||
||非极大值抑制(NMS)||
定义:
True positives : 真阳|True negatives: 真阴 | False positives: 假阳| False negatives: 假阴 |
Precision 与 Recall
Precision其实就是在识别出来的图片中,True positives所占的比率: 
其中的n代表的是(True positives + False positives)
Recall 是True positives与测试集中所有的比值: 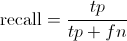
Recall的分母是(True positives + False negatives)
调整阈值
我们可以通过改变阈值,来选择让系统识别能出多少个图片,当然阈值的变化会导致Precision与Recall值发生变化。
下图为不同阈值条件下,Precision与Recall的变化情况: 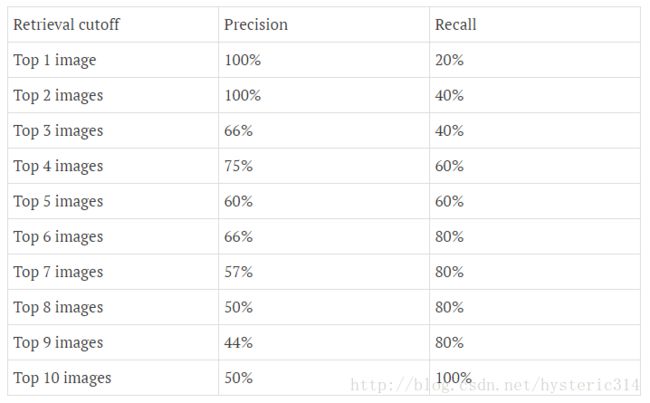
Precision-recall 曲线
如果你想评估一个分类器的性能,一个比较好的方法就是:观察当阈值变化时,Precision与Recall值的变化情况。如果一个分类器的性能比较好,那么它应该有如下的表现:让Recall值增长的同时保持Precision的值在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。 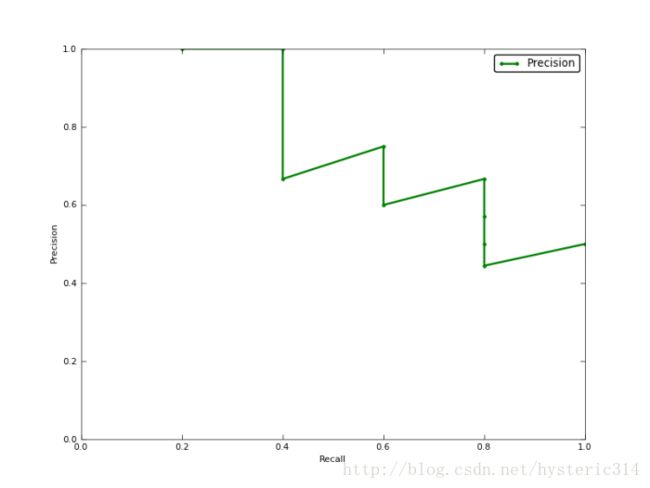
上图就是分类器的Precision-recall 曲线,在不损失精度的条件下它能达到40%Recall。而当Recall达到100%时,Precision 降低到50%。
Approximated Average precision
相比较与曲线图,在某些时候还是一个具体的数值能更直观地表现出分类器的性能。通常情况下都是用 Average Precision来作为这一度量标准,它的公式为: 
在这一积分中,其中p代表Precision ,r代表Recall,p是一个以r为参数的函数,That is equal to taking the area under the curve.
实际上这一积分极其接近于这一数值:对每一种阈值分别求(Precision值)乘以(Recall值的变化情况),再把所有阈值下求得的乘积值进行累加。公式如下: 
在这一公式中,N代表测试集中所有图片的个数,P(k)表示在能识别出k个图片的时候Precision的值,而 Delta r(k) 则表示识别图片个数从k-1变化到k时(通过调整阈值)Recall值的变化情况。
Interpolated average precision
不同于Approximated Average Precision,一些作者选择另一种度量性能的标准:Interpolated Average Precision。这一新的算法不再使用P(k),也就是说,不再使用当系统识别出k个图片的时候Precision的值与Recall变化值相乘。而是使用: 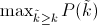
也就是每次使用在所有阈值的Precision中,最大值的那个Precision值与Recall的变化值相乘。公式如下: 
下图的图片是Approximated Average Precision 与 Interpolated Average Precision相比较。 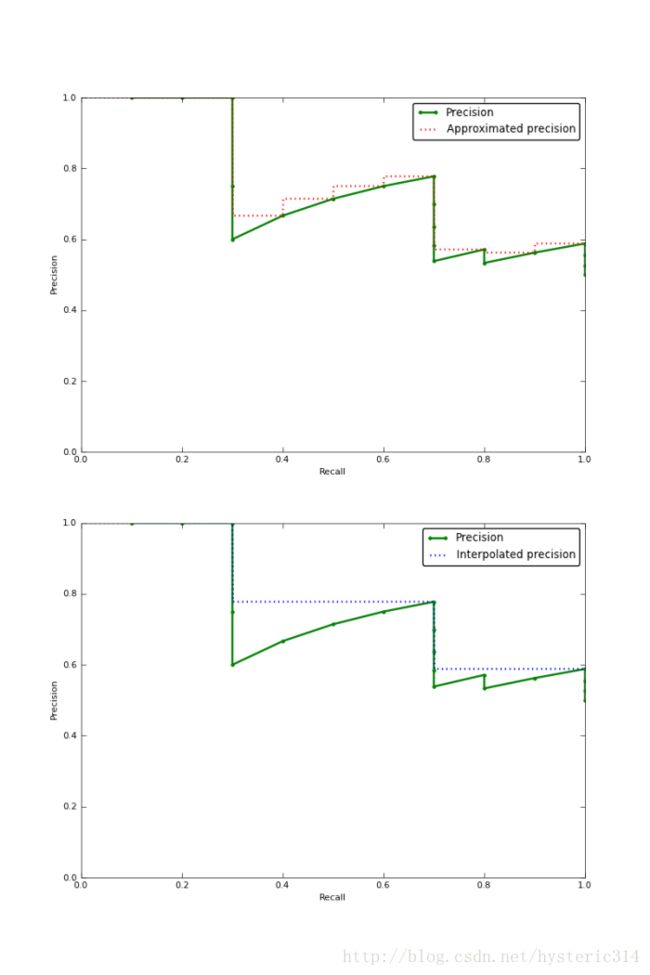
很明显 Approximated Average Precision与精度曲线挨的很近,而使用Interpolated Average Precision算出的Average Precision值明显要比Approximated Average Precision的方法算出的要高。
一些很重要的文章都是用Interpolated Average Precision 作为度量方法,并且直接称算出的值为Average Precision 。PASCAL Visual Objects Challenge从2007年开始就是用这一度量制度,他们认为这一方法能有效地减少Precision-recall 曲线中的抖动。所以在比较文章中Average Precision 值的时候,最好先弄清楚它们使用的是那种度量方式。
IoU
物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。
IoU这一值,可以理解为系统预测出来的框与原来图片中标记的框的重合程度。

IOU定义了两个bounding box的重叠度,如下图所示:
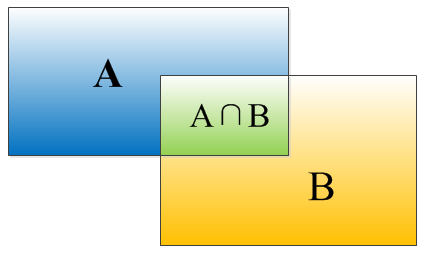
矩形框A、B的一个重合度IOU计算公式为:
IOU=(A∩B)/(A∪B)
即检测结果Detection Result与 Ground Truth 的交集比上它们的并集,即为检测的准确率:
如下图所示:
蓝色的框是:GroundTruth
黄色的框是:DetectionResult
绿色的框是:DetectionResult ⋂ GroundTruth
红色的框是:DetectionResult ⋃ GroundTruth

NMS
主要目的:
在物体检测非极大值抑制应用十分广泛,主要目的是为了消除多余的框,找到最佳的物体检测的位置。

如上图中:虽然几个框都检测到了人脸,但是我不需要这么多的框,我需要找到一个最能表达人脸的框。
原理:
非极大值抑制,顾名思义就是把非极大值过滤掉(抑制)。下面是R-CNN中的matlab源码
function picks = nms_multiclass(boxes, overlap)
%%boxes为一个m*n的矩阵,其中m为boundingbox的个数,n的前4列为每个boundingbox的坐标,格式为
%%(x1,y1,x2,y2);第5:n列为每一类的置信度。overlap为设定值,0.3,0.5 .....
x1 = boxes(:,1);%所有boundingbox的x1坐标
y1 = boxes(:,2);%所有boundingbox的y1坐标
x2 = boxes(:,3);%所有boundingbox的x2坐标
y2 = boxes(:,4);%所有boundingbox的y2坐标area = (x2-x1+1) .* (y2-y1+1); %每个%所有boundingbox的面积picks = cell(size(boxes, 2)-4, 1);%为每一类预定义一个将要保留的cell
for iS = 5:size(boxes, 2)%每一类单独进行
s = boxes(:,iS);
[~, I] = sort(s);%置信度从低到高排序
pick = s*0;
counter = 1;
while ~isempty(I)
last = length(I);
i = I(last);
pick(counter) = i;%无条件保留每类得分最高的boundingbox
counter = counter + 1;
xx1 = max(x1(i), x1(I(1:last-1)));
yy1 = max(y1(i), y1(I(1:last-1)));
xx2 = min(x2(i), x2(I(1:last-1)));
yy2 = min(y2(i), y2(I(1:last-1)));
w = max(0.0, xx2-xx1+1);
h = max(0.0, yy2-yy1+1);
inter = w.*h;
o = inter ./ (area(i) + area(I(1:last-1)) - inter);%计算得分最高的那个boundingbox和其余的boundingbox的交集面积
I = I(o<=overlap);%保留交集小于一定阈值的boundingbox
end
pick = pick(1:(counter-1));
picks{iS-4} = pick;%保留每一类的boundingbox
end 参考:
https://sanchom.wordpress.com/tag/average-precision/
http://blog.csdn.net/eddy_zheng/article/details/52126641