UI自动化CSS、Xpath选择器元素定位
CSS ID选择器:
ID在html规范里必须是唯一的,但id也会出现不唯一,或者id是动态变化的
如果id是唯一且基本固定,可以用ID来
语法 :tag[attribute='value'] 注释:标签名[属性名='属性值']
#--id属性
.--class属性
html标签名选择器、id选择气、class选择器
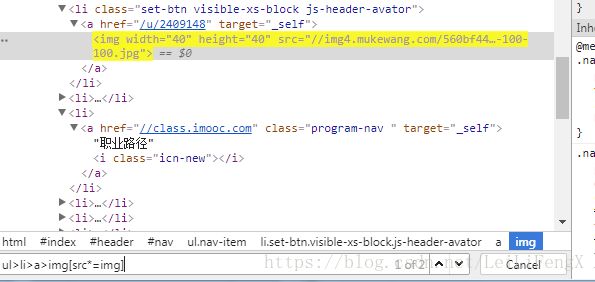
eg: a[id='login-btn']
a#login-btn
#login-btn
CSS 类选择器 或多个class时追加类选择器
语法: tag[attribut='value'] 标签名[属性='属性值']
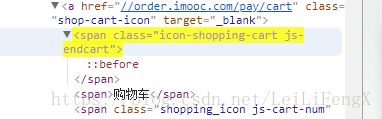
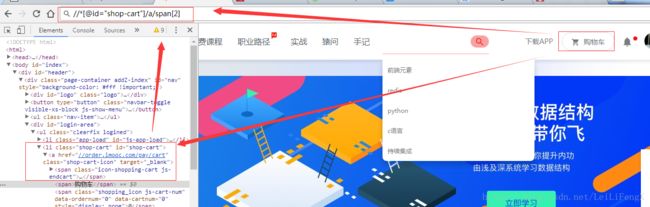
span.icon-shopping-cart.js-endcart 注:class有多个属性时,可以不断追加属性,不能带空格第一个classicon-shopping-cart,不够,同级可以在添加一个class,顺序无所谓,谁在前谁在后都一样
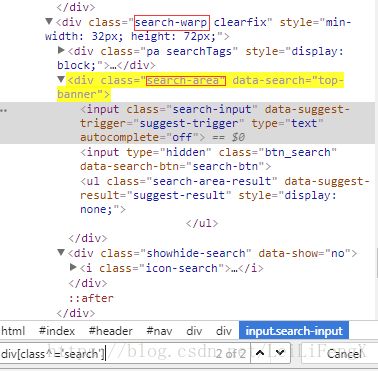
CSS选择器-通配符定位元素 好处可以匹配一批元素或者模糊查
1、^-->代表以什么文本开始
2、$-->代表已什么文本结尾
3、*-->代表包含什么文本 注:xpath contains()
语法:tag[attribute
eg:div[class^='search'] 注:查找div标签中以search开头的class属性的元素
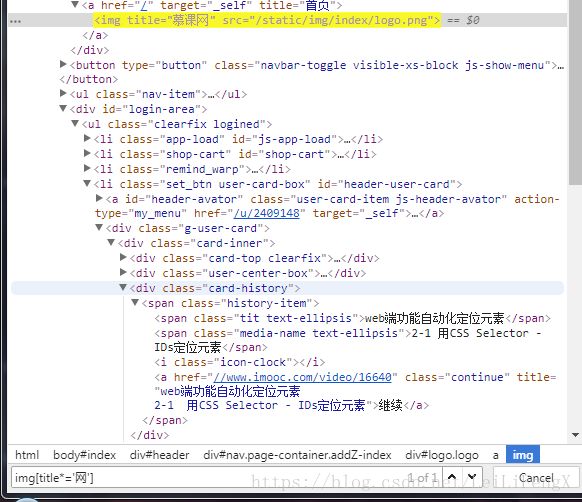
除了class和id还可以用其他属性
action-type="my_menu"
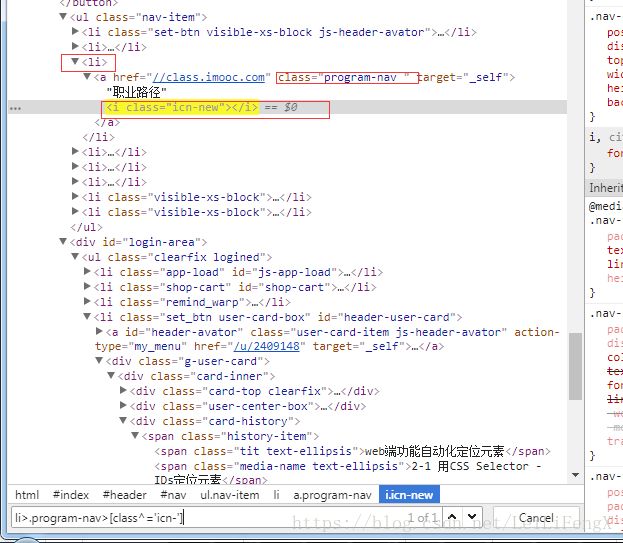
CSS选择器-查找子节点 只通过标签逐级往下找,左尖括号是CSS对象选择符
尖括号左右两边可以是标签,可以是属性
语法1:标签名>标签名……
语法2:标签名>类/id/其他属性
语法3:类/id/其他属性>标签名
div:nth-child(2)XPATH
Xpath元素定位原因如下:
- 元素的id不唯一,或者是动态的
- 或者其他属性eg:name、link、title等等属性值也不唯一
- 此时,我们就需要考虑Xpath来查找元素了,然后在对元素执行其他操作
常用语法://tag[@attribute='value']
"/"和"//"的区别:
- "/":元素是上一级节点的子节点中的一个,不能跳级,即:只能儿子、孙子,父与子
- "//":下级任何子节点或者任何嵌套子节点中的任意,可以跳级,即后代均可,父与后代(父与子是其中一类)
- 路径里面尽量不要用*(任意匹配),尽可能选上标签,速度快,
- "/"和"//"可以任意搭配混合使用,
绝对路径:Xpath绝对路径使用"/"单右斜杠来表示(一般不用相当路径,万一路径中层次路径结构变了(而且极易变),或者标签变了就不能用了)
相对路径:Xpath相对路径使用"//"双右斜杠来表示,结构路径简洁(短小精悍)
Xpath高级Xpath路径创建
xpath常用函数
- child 选取当前节点的所有子节点
- parent 选取当前节点的父节点
- descendant 选取当前节点的所有后代节点
- ancestor 选取当前节点的所有先辈节点
- descendant-or-self 选取当前节点的所有后代节点及当前节点本身
- ancestor-or-self 选取当前节点所有先辈节点及当前节点本身
- preceding-sibling 选取当前节点之前的所有同级节点
- following-sibling 选取当前节点之后的所有同级节点
- preceding 选取当前节点的开始标签之前的所有节点
- following 选去当前节点的开始标签之后的所有节点
- self 选取当前节点
- attribute 选取当前节点的所有属性
- namespace 选取当前节点的所有命名空间节点
1、使用//、/结合使用,能用在开头也能用在中间
2、使用text()函数文本定位://a[text()='值'](完全匹配,空格也要匹配上),模糊可以使用contains()
3、使用contains:语法 //tag[contains(@attribute,'value')]
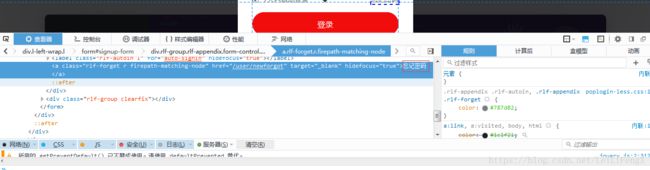
eg: //[contains(text(),'忘记密码')] 注(text()不加@)
//[contains(@title,'忘记密码')]
//input[contains(@class,'username') and contains(@id,'username1')]
4、使用start-with() //tag[start-with(@属性,'属性值')]
--------------------------------------------------------------------------------------
如何查找父节点和平级节点(上级或其他节点没有过多属性,没法直接定位到,就可通过父级或平级来)
找父级节点语法:Xpath-to-some-element//parent::tag 红色为不变
找前面平级级节点语法:Xpath-to-some-element//preceding-sibling::tag 红色为不变
找后面平级级节点语法:Xpath-to-some-element//following-sibling::tag 红色为不变
查找速度:id>name>css>xpath
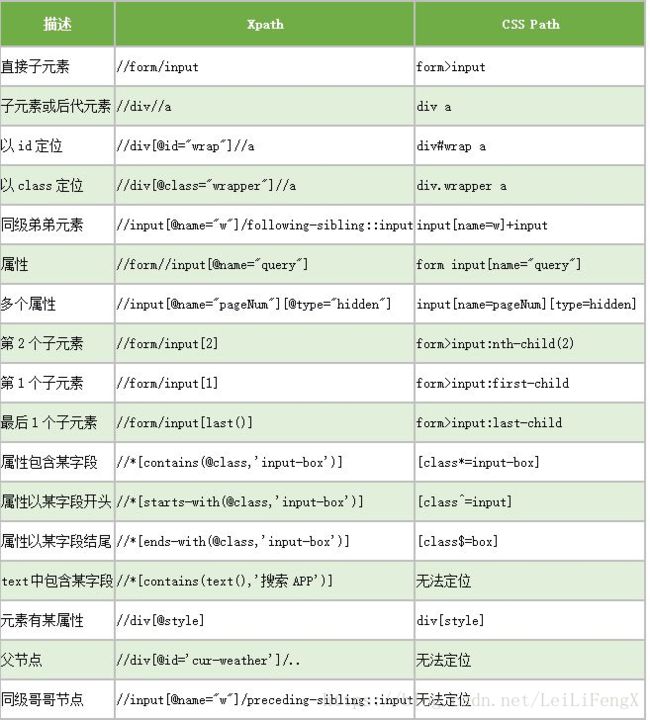
利用xpath的定位功能
寻找父元素:://DDD/parent::* DDD节点的所有父节点
寻找祖先节点:ancestor::BOOK[1] 离当前上下文节点最近的book祖先节点
寻找孩子节点:/child::AAA 等价于/AAA
寻找兄弟节点:following-sibling::div[@class='pct']
current.xpath("ancestor::div[@class='pi']").xpath("following-sibling::div[@class='pct']").xpath("descendant::td[@class='t_f']/text()").extract():寻找当前节点current的祖先节点div[@class='pi'的兄弟节点div[@class='pct的后代节点:td[@class='t_f']/的文本内容
其他常用的定位语句
1. //NODE[not(@class)] 所有节点名为node,且不包含class属性的节点
2. //NODE[@class and @id] 所有节点名为node,且同时包含class属性和id属性的节点
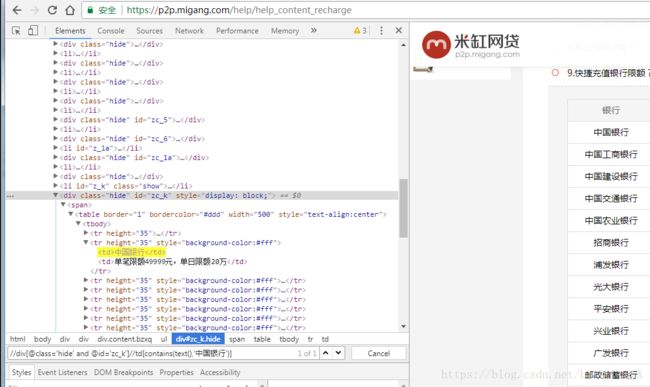
3. //NODE[contains(text(),substring] 所有节点名为node,且其文本中包含substring的节点//A[contains(text(),\"下一页\")] 所有包含“下一页”字符串的超链接节点
//A[contains(@title,"文章标题")] 所有其title属性中包含“文章标题”字符串的超链接节点4. //NODE[@id="myid"]/text() 节点名为node,且属性id为myid的节点的所有直接text子节点
5. BOOK[author/degree] 所有包含author节点同时该author节点至少含有一个的degree孩子节点的book节点6. AUTHOR[.="Matthew Bob"] 所有值为“Matthew Bob”的author节点
7. //*[count(BBB)=2] 所有包含两个BBB孩子节点的节点
8. //*[count(*)=2] 所有包含两个孩子节点的节点
9. //*[name()='BBB'] 所有名字为BBB的节点,等同于//BBB
10. //*[starts-with(name(),'B')] 所有名字开头为字母B的节点
11. //*[contains(name(),'C')] 所有名字中包含字母C的节点
12. //*[string-length(name()) = 3] 名字长度为3个字母的节点
13. //CCC | //BBB 所有CCC节点或BBB节点
14. /child::AAA 等价于/AAA
15. //CCC/descendant::* 所有以CCC为其祖先的节点
16. //DDD/parent::* DDD节点的所有父节点
17. //BBB[position() mod 2 = 0] 偶数位置的BBB节点
18. AUTHOR[not(last-name = "Bob")] 所有不包含元素last-name的值为Bob的节点
19. P/text()[2] 当前上下文节点中的P节点的第二个文本节点
20. ancestor::BOOK[1] 离当前上下文节点最近的book祖先节点
21. //A[text()="next"] 锚文本内容等于next的A节点