邓仰东专栏|机器学习的那些事儿(二):机器学习简史
目录
1.绪论
1.1.概述
1.2 机器学习简史
1.3 机器学习改变世界:基于GPU的机器学习实例
1.3.1 基于深度神经网络的视觉识别
1.3.2 AlphaGO
1.3.3 IBM Waston
1.4 机器学习方法分类和本书组织
机器学习是同计算机科学一起诞生的,图灵、冯·诺依曼、赫伯特·西蒙等计算机科学先驱同时也是机器学习理论的教父。本节回顾机器学习理论和技术发展的历史,从中领略人类心智激动人心的前进脚步。
在回顾之前,我们首先梳理相关概念。作为正在高速发展的跨领域学科,数据科学的术语体系比较混乱,特别是『数据挖掘』和『机器学习』两个属于经常被混用。
作为数据科学的核心手段,数据挖掘以数据库技术为依托,以机器学习作为核心算法,以统计、分类、预测模型和数据可视化作为典型数据输出方式,借助现代计算机硬件特别是各种并行处理器的强大处理能力以及程序设计技术,从海量数据中精炼出信息、知识直至智慧。
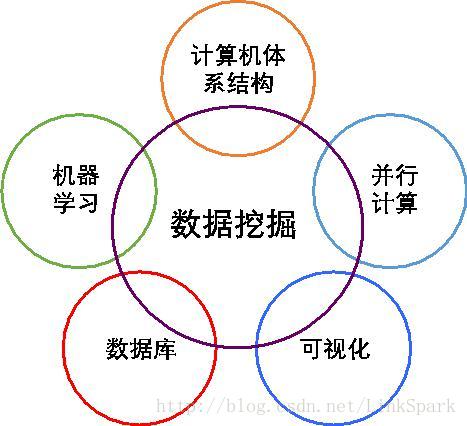
图1-3 数据挖掘技术要素图
图1-3是对数据挖掘和其它相关学科的关系。按照米切尔(Tom M. Mitchell)的定义,机器学习是能够针对某种任务从经验学习的计算机程序,在执行该任务时的性能随经验增加而提高[]。 作为数据挖掘的算法和手段,机器学习属于人工智能的一部分,整合了计算机科学、数学(特别是统计学)和神经科学等领域的最新成果,图1-4是数据挖掘与其相关领域的关系图。
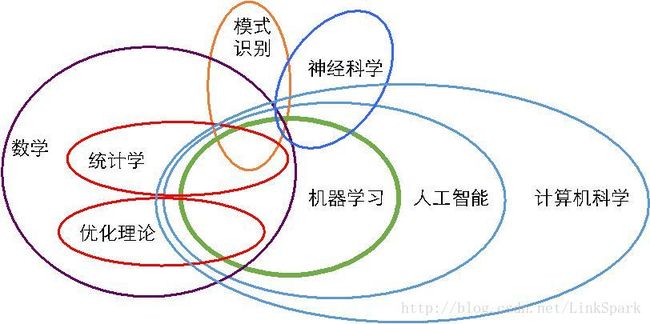
图1-4. 机器学习及其相关学科关系
机器学习技术的焦点是预测,即通过对未知概率分布的历史观测数据进行处理,推断由该分布产生的观测数据的未来趋势。
早期的机器学习更多遵循传统算法研究的方法,而过去的20年中,统计学理论已经在很大程度上改造了机器学习理论和方法,使得机器学习获得了更为严格的理论基础;同时,神经科学也为机器学习注入了新的灵感,通过借鉴人脑神经原理,深度神经网络在近年中取得了巨大的成功。
人工智能是人类长时间的梦想。为了形成人工智能,很自然地希望机器能够像人类一样,通过一个学习的过程(当然我们希望这个过程尽量缩短)掌握相关知识,并且形成自动推理工具。1950年,伟大的计算机科学家阿兰·图灵提出了『图灵测验』的概念,宣告人类第一次以严格而形式化的方式定义人工智能的测试准则。
图灵测验要求人类测试者和计算机进行交互,如果测试者不能分辨交互对象是人还是计算机,那么就可以认为计算机(至少在某一方面)具有和人类相似的智能。
1952年,当时正在IBM工作的阿瑟·塞缪尔(Arthur Samuel)设计了第一个计算机学习程序。这个程序针对西洋跳棋(checker)进行学习,已经具备了现代机器学习的很多特征,通过使用搜索树(search tree)存储对弈策略,能够通过不断对弈提高自身的能力。
由于当时计算机内存极少,因此塞缪尔还设计了a-b减枝(a-b pruning)策略,通过打分机制减少需要完全探索的分支,这个打分机制能够根据对弈盘面判断每一步骤对整体形式的影响。
1956年,由约翰·麦卡锡(John McCarth)发起,马文·明斯基(Marvin Minsky)、奥利佛·塞尔福里奇(Oliver Selfridge)、克劳德∙香农(Claude Shannon)、阿兰·纽厄尔(Allen Newell)、司马贺(Herbert Simon,音译为赫伯特·西蒙,他自己为自己取了中文名字)、雷·所罗门诺夫(Ray Solomonoff)、阿瑟·塞缪尔、内森尼尔·罗切斯特(Nathaniel Rochester)和特兰查德·摩尔(Trenchard More)等学术巨擘(其中香农是老一辈的任务,已经发表了他著名的信息论论文。司马贺是百科全书式的大师,未来将与纽厄尔一起创立了卡内基·梅隆大学计算机系,还讲一起获得图灵奖,还讲获得诺贝尔经济学奖。明斯基、麦卡锡、纽厄尔都将获得图灵奖。雷·所罗门诺夫未来是算法概率论的发明人,罗切斯特将设计IBM 701计算机和世界上第一个汇编程序,塞尔福里奇将被称为『机器感知之父』(他的祖父是伦敦著名的塞尔福里奇百货公司创始人),塞缪尔前文已经介绍,是人工智能游戏的奠基人之一。)共同参加了达特茅斯回忆(Dartmouth Conferences),为未来人工智能研究提出了纲领,认为人工智能(『人工智能』这个提法要到后来1965年才能提出)研究应该在 七个方向上开展:
1.可编程计算机,2.编程语言,3.神经网络
4.计算复杂性理论,5.机器学习,6.抽象,7.随机性和创见性。
这次堪与物理学史上著名的索末菲会议标志着人工智能科学的正式诞生。
1957年,佛兰克·罗森布拉特(Frank Rosenblatt)根据赫布学习法则(Hebb’s Rules)设计了第一个能够被计算机执行的人工神经网,当时叫做感知器(perceptron)。
从今天的观点看,感知器是单层神经网,把多个输入值通过经过训练的函数处理后形成输出。罗森布拉特同时构造了最小二乘法和梯度下降法等训练方法,直至今天仍然是深度神经网络训练的基本机制。
然而,马文·明斯基和西摩·派珀特(Seymour Papert)详细分析了感知器的局限性,证明感知器不能处理所谓『线性不可分问题』,其中最著名的是异或计算,我们无法用一个线性函数把两变量的异或计算结果区分开。明斯基和派珀特的工作主要是为了说明单层感知器的能力有限、而多层感知器具有更加强大的学习能力。
但是,也许异或计算给人的印象过于鲜明,这篇文章带来了人工设计网络的冬天,直至二十世纪末杰佛里·辛顿(Geoffrey Everest Hinton)以极度的坚韧开创性地证明了深度神经网络的强大威力,神经网络的春天才再次降临。
另一方面,基于搜索和逻辑等传统计算机科学技术的机器学习仍然在继续发展。1957年,贝尔实验室的斯图尔特·劳依德( Stuart Lloyd)提出K-means算法,这是最早的非监督学习算法。
1967年,最近邻(Nearest Neighbor)算法被构造出来,这实际上是一种基本的模式识别算法。1960年代也诞生了决策树算法(Decision Tree),能够通过学习历史数据形成支撑分类决策的树形结构,1970年代后期,决策树算法演变为ID3算法,后来又改进为ID4.5算法。这些算法直到今天仍然被广泛用于各种数据分类问题。
1980年代是专家系统的时代,学术研究的热点是对各种领域知识进行整理。因此,各种基于规则的专家系统或知识库如雨后春笋般诞生,佛雷德里克·海伊斯-罗斯(Frederick Hayes-Roth)在他的专著中把这些系统分为解释、预测、诊断、设计、规划、监控、调试、维修、教学和控制十大类[1]。
然而,这些基于知识的技术并未取得深刻的成功。一方面,此时对知识的处理很大程度上是把知识编码为规则,典型形式为“if…else…”的条件判断,而不是真正意义的学习,因此专家系统实际上很难做到“发人所未发”;另一方面,人类知识绝大多数不具备数据的严格性,在实际的工程和商业知识中,总是存在大量的不确定性和不完备性,专家系统只能从编码的知识出发进行处理,对于不能编码的知识则无能为力。
由于基于知识的机器学习理论和技术局限性,1990年代人类进入了数据驱动学习的时代。这段时期,分类、回归、搜索和关联关系挖掘等各种学习算法飞快走向成熟,核心思想是分析数据从而提取知识。
1997年,人工智能的突破终于到来,IBM“深蓝”计算机第一次在国际象棋比赛中击败了代表人类最高水平的国家象棋大师卡斯帕罗夫。当然应该指出,“深蓝”的突出能力在高速搜索最佳对弈策略,而国际象棋策略相对容易编码,因此“深蓝”的胜利还不能完全等同于机器学习的胜利。
2006年,机器学习大师杰佛里·辛顿定义了“深度学习”概念,用来包装他和合作者们多年开发的一组基于神经网的学习算法。此时的神经网不仅是多层神经网,而是借鉴人脑神经通路结构形成的“深度”神经网,能够让计算机“看到”并且分辨复杂的图形和文字。实际上,深度神经网最早的成功应用是对支票的识别,美国银行几乎一夜之间全都采用了基于卷积神经网络的自动识别系统。
2010年以后,以深度神经网络为代表的深度学习理论和技术取得了惊人的成功。2010年微软推出的Kinect系统能够实时(允许相关内容以每秒30帧速率刷新)跟踪20个人体特征,根据机器学习形成的模型识别人体行为,从而使得计算机游戏(或其它应用)和人通过运动和姿态进行实时交互。
2011年,IBM开发的深度问题-答案(DeepQA)系统集成于Waston计算机,在著名的问答类智力游戏“危险边缘”中打败了人类参赛者。谷歌2011年开发了谷歌大脑系统,能够对图片进行分析,从中识别物体并进行分类,基本达到猫的识别和分类水平,同期谷歌Xlab开发了能够自动浏览YouTube视频并从中发现含有猫的内容。
2010年开始的大规模视觉识别竞赛(Large Scale Visual Recognition Challenge)更是极大促进了以图像识别为目的的机器学习技术,到2014年,深度神经网识别人脸的精确的已经超越人类水平。如果使用人脸识别作为图灵测验的话,计算机已经需要假装认不出某些人脸了。
机器学习最新的成就,是谷歌的AlphaGo在2016年击败世界围棋冠军李世乭,攻克了普遍认为是可能性最多、局势最难判断因而最困难的对弈游戏。
不同于“深蓝”计算机,AlphaGo的的确确在进行学习,不仅使用深度神经网络学习某一盘面下最好的下法,也通过增强式学习某一下法对全局的影响。
机器学习技术是如此之成功,以至于有识之士们已经开始担心人工智能技术被用于智能化武器,从而对人类本身造成巨大威胁。2015年,包括斯蒂芬·霍金(Stephen Hawking)、埃隆·马斯克(Elon Musk)和斯蒂夫·沃兹尼亚克(Stephen Wozniak)等在内的3000多位科学家和工程师签名发表了公开信号召国际社会采取措施,防止智能武器在不受人干涉的情况下选择目标和发起攻击。
虽然机器学习取得了惊人的成就,我们还是要说这仅仅是一个伟大时代的开端。伟大的十八世纪物理学家和数学家拉普拉斯认为只要我们有足够的初始条件和物理知识,那么依靠牛顿力学就足以计算出宇宙的过去、现在和未来。著名科技杂志《连线》(Wired)在2008年发表当时主编克里斯·安德森(Chris Anderson)的一篇文章,则认为“数量庞大的数据会使人们不再需要理论,甚至不再需要科学的方法”。
安德森的意思是说,随着数据越来越多,机器学习手段越来越发达,我们可以通过研究历史数据直接揭示事物之间的因果关系,而不再需要专门的理论和方法。
这个结论可以说是拉普拉斯决定论的“机器学习版本”,虽然可能过于宏伟,但是机器学习的确可以作为一种科学发现的重要工具。近年来,因果性挖掘(Causal Analysis)、隐变量分析(Latent Variable Modeling)和贝叶斯学习(Bayesian Learning)理论吸引了大量研究者,这些理论必将成为自动知识发现的利器。
注:
[1]Hayes-Roth, Frederick; Waterman, Donald; Lenat, Douglas (1983). Building Expert Systems. Addison-Wesley. ISBN 0-201-10686-8.
关注LinkSpark日报,最新鲜的业界咨询、最有用的教程福利、最权威的教授专栏,全都一网打尽。