《MobileNetV1 + MobileNetV2 + MobileNetV3 》论文阅读笔记
目录
一、《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
第一点:标准卷积和深度可分离卷积的区别。包括参数对比
第二点:理解两个超参数:宽度乘子和分辨率乘子
第三点:分析模型代码以及模型参数变化
二、《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
第一点:对比MobileNet V1与V2的网络结构
第二点:对比MobileNet V1与ResNet的网络结构
第三点:网络结构
第三点:分析模型代码及结构
三、《Searching for MobileNetV3》
第一点:引入SE结构
第二点:修改尾部结构
第三点:修改通道数
第四点: 非线性变换的改变
第五点:分析模型代码和参数
四、模型图
第一点:MobileNetV1网络结构图
第二点:MobileNetV2网络结构图
第三点: MobileNetV3网络结构图
说明:代码及模型都是基于分类的。可以先看大致看一下模型图,再去看其他部分。
一、《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
摘要:我们为移动和嵌入式视觉应用提出了一种称为MobileNets的有效模型。 MobileNets基于简化的架构,该架构使用深度可分离卷积来构建轻型深度神经网络。 我们介绍了两个简单的全局超参数,它们可以有效地在延迟和准确性之间进行权衡。 这些超参数允许模型构建者根据问题的约束条件为其应用选择合适大小的模型。 我们对资源和精度进行了广泛的权衡取舍,与ImageNet分类中的其他流行模型相比,我们展示了强大的性能。 然后,我们演示了MobileNets在各种应用程序和用例中的有效性,包括对象检测,细粒度分类,人脸属性和大规模地理定位。
第一点:标准卷积和深度可分离卷积的区别。包括参数对比

1、标准卷积

(1)卷积核的参数量:![]() ,其中
,其中![]() 表示卷积核的大小,M表示输入通道的大小,N表示输出通道的大小。
表示卷积核的大小,M表示输入通道的大小,N表示输出通道的大小。
(2)计算量: ,
,![]() 表示特征图的大小
表示特征图的大小
2、深度可分离卷积:depthwise卷积和pointwise卷积
2.1 depthwise卷积

(1)卷积核的参数量:![]() ,
,![]() 表示卷积核的大小,M表示输入通道的大小。
表示卷积核的大小,M表示输入通道的大小。
(2)计算量:![]()
2.2 pointwise卷积
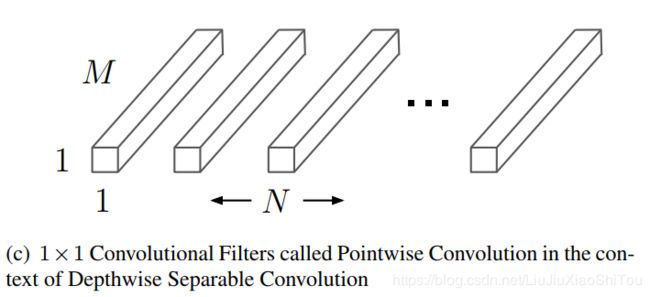
(1)卷积核的参数量:1x1xMxN
(2)计算量:![]()
3、参数对比


4、以上三种卷积的图示:图来源 可分离卷积
(1)常规卷积运算

(2)Depthwise Convolution

(3)Pointwise Convolution
第二点:理解两个超参数:宽度乘子和分辨率乘子
1.宽度乘子:用α示,该参数用于控制特征图的维数,即通道数。
2.分辨率乘子:用ρ表示,该参数用于控制特征图的宽/高,即分辨率

第三点:分析模型代码以及模型参数变化
1、model.py
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
#标准卷积
def conv_bn(inchannels, outchannels, stride):
return nn.Sequential(
nn.Conv2d(inchannels, outchannels, 3, stride, 1, bias=False),
nn.BatchNorm2d(outchannels),
nn.ReLU(inplace=True)
)
#深度可分离卷积
def conv_dw(inchannels, outchannels, stride):
return nn.Sequential(
nn.Conv2d(inchannels, inchannels, 3, stride, 1, groups=inchannels, bias=False),
nn.BatchNorm2d(inchannels),
nn.ReLU(inplace=True),
nn.Conv2d(inchannels, outchannels, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannels),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential(
conv_bn(3, 32, 2),
conv_dw(32, 64, 1),
conv_dw(64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
nn.AvgPool2d(7),
)
self.fc = nn.Linear(1024, 1000)
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
from torchsummary import summary
# #d打印网络结构及参数和输出形状
net = Net()
summary(net, input_size=(3, 224, 224)) #summary(net,(3,250,250))
二、《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
摘要:
在本文中,我们描述了一种新的移动体系结构MobileNetV2,该体系结构可提高移动模型在多个任务和基准以及跨不同模型大小的范围内的最新性能。 我们还描述了在称为SSDLite的新颖框架中将这些移动模型应用于对象检测的有效方法。 此外,我们演示了如何通过简化形式的DeepLabv3(我们称为Mobile DeepLabv3)构建移动语义细分模型。
基于反向残差结构,其中快捷方式连接位于薄瓶颈层之间。 中间扩展层使用轻量级的深度卷积来过滤作为非线性源的特征。 另外,我们发现删除窄层中的非线性以保持代表性很重要。 我们证明了这样做可以提高性能,并提供导致这种设计的直觉。
最后,我们的方法允许将输入/输出域与转换的表达方式分离,这为进一步分析提供了方便的框架。 我们在ImageNet [1]分类,COCO对象检测[2],VOC图像分割[3]上衡量我们的性能。 我们评估精度与乘加(MAdd)度量的操作数,实际延迟以及参数数之间的权衡。
第一点:对比MobileNet V1与V2的网络结构

1、深度可分离卷积前面加了1*1的卷积层(扩张通道),不改变特征图的大小,只为增加通道数,以至于获得更多的特征
2、最后不适用激活函数,而是Linear,目的是防止ReLU破坏特征。特征在之前已经被压缩,在使用ReLU,负数置零过多。
第二点:对比MobileNet V1与ResNet的网络结构

ResNet结构 ”压缩”→“卷积提特征”→“扩张“,MobileNet V2 是”扩张”→“卷积提特征”→“压缩“,所以文中称Inverted residual block
第三点:网络结构

1、Bottleneck residual block

2、模型对比

特别的,针对stride=1 和stride=2,在block上有稍微不同,主要是为了与shortcut的维度匹配,因此,stride=2时,不采用shortcut。 不使用池化层来进行下采样了,取而代之使用的是stride=2的卷积层来进行下采样,(1)可能是因为能够获得更多的语义信息和细粒度特征的原因。(2)在MobileNet V1中提到了,说是因为模型小不容易出现过拟合的问题,反而更容易出现欠拟合的问题,加入pooling层容易丢失有用信息,增加模型欠拟合的可能性。
第三点:分析模型代码及结构
1、model.py
import torch
import torch.nn as nn
class BottleNeck(nn.Module):
def __init__(self, in_channels, out_channels, stride, t):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, in_channels * t, 1, bias=False),
nn.BatchNorm2d(in_channels * t),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels * t, in_channels * t, 3, stride=stride, padding=1, groups=in_channels * t,
bias=False),
nn.BatchNorm2d(in_channels * t),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels * t, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.shortcut = nn.Sequential()
if stride == 1 and in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.stride = stride
def forward(self, x):
out = self.conv(x)
if self.stride == 1:
out += self.shortcut(x)
return out
class MobileNetV2(nn.Module):
def __init__(self, class_num=10):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 32, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True)
)
self.bottleneck1 = self.make_layer(1, 32, 16, 1, 1)
self.bottleneck2 = self.make_layer(2, 16, 24, 2, 6)
self.bottleneck3 = self.make_layer(3, 24, 32, 2, 6)
self.bottleneck4 = self.make_layer(4, 32, 64, 2, 6)
self.bottleneck5 = self.make_layer(3, 64, 96, 1, 6)
self.bottleneck6 = self.make_layer(3, 96, 160, 2, 6)
self.bottleneck7 = self.make_layer(1, 160, 320, 1, 6)
self.conv2 = nn.Sequential(
nn.Conv2d(320, 1280, 1, bias=False),
nn.BatchNorm2d(1280),
nn.ReLU6(inplace=True)
)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.conv3 = nn.Conv2d(1280, class_num, 1, bias=False)
def make_layer(self, repeat, in_channels, out_channels, stride, t):
layers = []
layers.append(BottleNeck(in_channels, out_channels, stride, t))
while repeat - 1:
layers.append(BottleNeck(out_channels, out_channels, 1, t))
repeat -= 1
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bottleneck1(x)
x = self.bottleneck2(x)
x = self.bottleneck3(x)
x = self.bottleneck4(x)
x = self.bottleneck5(x)
x = self.bottleneck6(x)
x = self.bottleneck7(x)
x = self.conv2(x)
x = self.avgpool(x)
x = self.conv3(x)
x = x.flatten(1)
return x
from torchsummary import summary
# #d打印网络结构及参数和输出形状
net = MobileNetV2()
summary(net, input_size=(3, 224, 224)) #summary(net,(3,250,250))2、模型参数设置

MobileNetV2:每行描述一个1层或更多相同(模数跨度)层的序列,重复n次。 相同顺序的所有层具有相同数量的输出通道c。 每个序列的第一层都有一个跨度s,所有其他层都使用跨度1。所有空间卷积都使用3×3内核。 如表1所示,始终将扩展因子t应用于输入大小。
三、《Searching for MobileNetV3》
摘要
第一点:引入SE结构

在depthwise之后引入了SE结构,虽然会消耗一定时间,但是通道数变为原来的1/4。
第二点:修改尾部结构

在mobilenetv2中,在avg pooling之前,存在一个1x1的卷积层,目的是提高特征图的维度,更有利于结构的预测,但是这其实带来了一定的计算量了,所以这里作者修改了,将其放在avg pooling的后面,首先利用avg pooling将特征图大小由7x7降到了1x1,降到1x1后,然后再利用1x1提高维度,这样就减少了7x7=49倍的计算量。并且为了进一步的降低计算量,作者直接去掉了前面纺锤型卷积的3x3以及1x1卷积,进一步减少了计算量,就变成了如下图第二行所示的结构,作者将其中的3x3以及1x1去掉后,精度并没有得到损失。(在代码和模型中中的体现:其实在mobilenetv2中最后一个块也算入到 Original Last Stage中(1x1,3x3,1x1,然后1x1,池化,1x1),在Efficient Last Stage(1x1`,池化,1x1,1x1),所以在图示模型中才有一种增加的感觉,而不是减少)
第三点:修改通道数


修改头部卷积核channel数量,mobilenet v2中使用的是32 x 3 x 3,作者发现,其实32可以再降低一点,所以这里作者改成了16,在保证了精度的前提下,降低了3ms的速度。
第四点: 非线性变换的改变

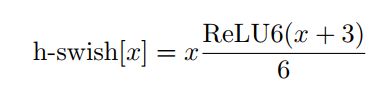
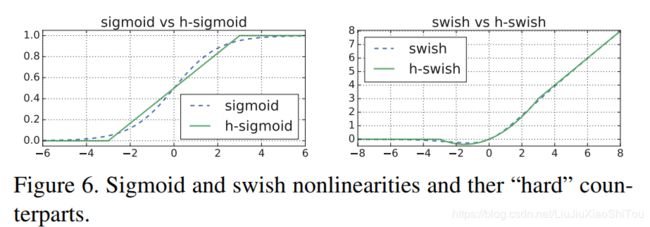
作者使用ReLU6(x+3)/6来近似替代sigmoid,观察下图可以发现,其实相差不大的。利用ReLU有几点好处,1.可以在任何软硬件平台进行计算,2.量化的时候,它消除了潜在的精度损失,使用h-swish替换swith,在量化模式下回提高大约15%的效率,另外,h-swish在深层网络中更加明显。
第五点:分析模型代码和参数
1、model.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
class hswish(nn.Module):
def forward(self, x):
out = x * F.relu6(x + 3, inplace=True) / 6
return out
class hsigmoid(nn.Module):
def forward(self, x):
out = F.relu6(x + 3, inplace=True) / 6
return out
class SeModule(nn.Module):
def __init__(self, in_size, reduction=4):
super(SeModule, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_size, in_size // reduction, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size // reduction),
nn.ReLU(inplace=True),
nn.Conv2d(in_size // reduction, in_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size),
hsigmoid()
)
def forward(self, x):
return x * self.se(x)
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, kernel_size, in_size, expand_size, out_size, nolinear, semodule, stride):
super(Block, self).__init__()
self.stride = stride
self.se = semodule
self.conv1 = nn.Conv2d(in_size, expand_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(expand_size)
self.nolinear1 = nolinear
self.conv2 = nn.Conv2d(expand_size, expand_size, kernel_size=kernel_size, stride=stride, padding=kernel_size//2, groups=expand_size, bias=False)
self.bn2 = nn.BatchNorm2d(expand_size)
self.nolinear2 = nolinear
self.conv3 = nn.Conv2d(expand_size, out_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_size)
self.shortcut = nn.Sequential()
if stride == 1 and in_size != out_size:
self.shortcut = nn.Sequential(
nn.Conv2d(in_size, out_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_size),
)
def forward(self, x):
out = self.nolinear1(self.bn1(self.conv1(x)))
out = self.nolinear2(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.se != None:
out = self.se(out)
out = out + self.shortcut(x) if self.stride==1 else out
return out
class MobileNetV3_Large(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3_Large, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(3, 16, 16, 16, nn.ReLU(inplace=True), None, 1),
Block(3, 16, 64, 24, nn.ReLU(inplace=True), None, 2),
Block(3, 24, 72, 24, nn.ReLU(inplace=True), None, 1),
Block(5, 24, 72, 40, nn.ReLU(inplace=True), SeModule(40), 2),
Block(5, 40, 120, 40, nn.ReLU(inplace=True), SeModule(40), 1),
Block(5, 40, 120, 40, nn.ReLU(inplace=True), SeModule(40), 1),
Block(3, 40, 240, 80, hswish(), None, 2),
Block(3, 80, 200, 80, hswish(), None, 1),
Block(3, 80, 184, 80, hswish(), None, 1),
Block(3, 80, 184, 80, hswish(), None, 1),
Block(3, 80, 480, 112, hswish(), SeModule(112), 1),
Block(3, 112, 672, 112, hswish(), SeModule(112), 1),
Block(5, 112, 672, 160, hswish(), SeModule(160), 1),
Block(5, 160, 672, 160, hswish(), SeModule(160), 2),
Block(5, 160, 960, 160, hswish(), SeModule(160), 1),
)
self.conv2 = nn.Conv2d(160, 960, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(960)
self.hs2 = hswish()
self.linear3 = nn.Linear(960, 1280)
self.bn3 = nn.BatchNorm1d(1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(1280, num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 7)
out = out.view(out.size(0), -1)
out = self.hs3(self.bn3(self.linear3(out)))
out = self.linear4(out)
return out
class MobileNetV3_Small(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3_Small, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(3, 16, 16, 16, nn.ReLU(inplace=True), SeModule(16), 2),
Block(3, 16, 72, 24, nn.ReLU(inplace=True), None, 2),
Block(3, 24, 88, 24, nn.ReLU(inplace=True), None, 1),
Block(5, 24, 96, 40, hswish(), SeModule(40), 2),
Block(5, 40, 240, 40, hswish(), SeModule(40), 1),
Block(5, 40, 240, 40, hswish(), SeModule(40), 1),
Block(5, 40, 120, 48, hswish(), SeModule(48), 1),
Block(5, 48, 144, 48, hswish(), SeModule(48), 1),
Block(5, 48, 288, 96, hswish(), SeModule(96), 2),
Block(5, 96, 576, 96, hswish(), SeModule(96), 1),
Block(5, 96, 576, 96, hswish(), SeModule(96), 1),
)
self.conv2 = nn.Conv2d(96, 576, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(576)
self.hs2 = hswish()
self.linear3 = nn.Linear(576, 1280)
self.bn3 = nn.BatchNorm1d(1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(1280, num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 7)
out = out.view(out.size(0), -1)
out = self.hs3(self.bn3(self.linear3(out)))
out = self.linear4(out)
return out
from torchsummary import summary
# #d打印网络结构及参数和输出形状
net = MobileNetV3_Small()
summary(net, input_size=(3, 224, 224)) #summary(net,(3,250,250))
四、模型图
第一点:MobileNetV1网络结构图

网络结构说明:其实最重要的改进就是把普通卷积改为可分离卷积。卷积步长的设置起到下采样的作用,1*1卷积不改变特征图的大小,起到扩充通道的作用。
第二点:MobileNetV2网络结构图

网络结构说明:其实引入bottleneck块,先扩张,在卷积,在压缩,逆残差结构,短连接当步长为1有,去掉残差块最后的ReLU。
第三点: MobileNetV3网络结构图

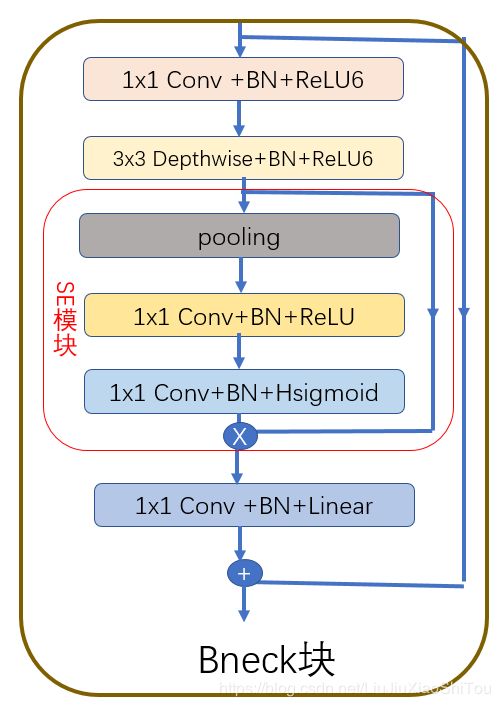
网络结构说明:Bneck块有是否存在SE模块,激活函数使用ReLU和HS,卷积核大小不同类型的块,不断优化。其实论文好像重要的是搜索优化的部分。
关于全连接层与1*1卷积层,这个在画图的时候和看论文的时候有点混乱。
当输入的feature map的尺寸是1×1时,两者从数学原理上来看,没有区别。假设输入为c×1×1,输出为n×1×1,那么全连接可以认为是一个c维的向量和n×c大小的矩阵相乘。卷积层可以理解为n个c×1×1的卷积核,分别与输入做内积,跟计算矩阵向量乘没有区别。
当输入为c×w×h时,卷积层和全连接层的输出尺寸就不一样了,1×1的卷积输出为n×w×h,全连接的输出是n×1×1。此时,全连接可以等价于n个c×w×h卷积核的卷积层。
全连接层和卷积层最大的区别就是输入尺寸是否可变,全连接层的输入尺寸是固定的,卷积层的输入尺寸是任意的。