2024年1月6日~2024年1月12日周报
目录
一、前言
二、SeisInvNet-2020
三、RTM研究
四、遇到的问题及解决
4.1 KeyError: 'data'
4.2 将mat文件转换为npy文件
五、小结
5.1 存在的问题及疑惑
5.2 下周安排
一、前言
本周的主要安排是阅读论文查看一些好的点子。
但是想法总是美好的,之前答应的伴娘任务没想到这么重,以至于任务完成情况不太好。这个过程中或多或少也有一些收获,学到了一些新的知识点,对之前模糊的概念也有了更清晰的认识。
二、SeisInvNet-2020
标题:Deep learning Inversion of Seismic Data—地震数据的深度反演
数据集:自主创立的SeisInv数据集—10000用于训练,1000用于验证,1000用于测试。
主要思想:在SeisInvNet模型中,首先对地震数据进行预处理,包括噪声去除、信号增强等操作,以提高数据的质量和可读性;然后,利用深度学习技术对地震数据进行特征提取,提取出与地下地质结构相关的特征信息;接下来,将这些特征信息输入到分类器中进行分类,以实现对地下地质结构的自动识别和解释。
主要解决的问题:
- 解决地震勘探领域中从时间序列数据到空间图像(地震速度模型)的映射挑战,通过深度神经网络(DNN)直接从地震数据重建速度模型
现有方法存在的不足:
- 传统方法通过迭代算法—存在非线性映射差和非唯一性强(不充分的观测或观测数据的噪声污染)的缺点;其他尝试可能会引入人为干预错误或未充分利用地震数据
- DNN主要面临的挑战:弱空间对应性、地震数据与速度模型之间的不确定反射-接收关系、地震数据的时变性
- InversionNet直接构建从原始地震数据到相应速度模型的映射,尊存自动编码器架构,从编码整个地震数据的嵌入向量解码速度模型—由于数据在嵌入向量中被极度压缩,解码的速度模型可能丢失细节。
创新点:
- 可以充分利用所有地震数据:增强每条地震道的领域信息、观测设置和相应的地震剖面背景
- 可以从每条地震道中学习速度模型空间对应的特征图:通过全连接层来学习空间对齐的特征映射,该特征图具有与整个速度模型相对应的信息,进一步连接重建速度模型,可以处理地震数据的不确定性和时变特性(使用到了图像嵌入的想法)
地震数据的不确定性和时变特性是地震数据处理和分析中的两个重要问题。
- 不确定性:地震数据的不确定性主要来自于地震波传播的复杂性和观测条件的限制。由于地震波在地下的传播过程中会受到多种因素的影响,如岩性、地质构造、地下水位等,使得地震数据的解释变得非常复杂。此外,观测条件的限制,如地震仪器的精度、观测环境的噪音等,也会导致地震数据的不确定性。为了减小这种不确定性,可以采用更先进的数据处理和解释方法,如深度学习技术,对地震数据进行更准确的分析和解释。
- 时变特性:地震数据的时变特性主要表现在地震波的传播速度和强度会随着时间和空间的变化而变化。这种变化可能是由于地下岩性的变化、地质构造的运动、地下水位的变化等多种因素引起的。为了处理这种时变特性,需要对地震数据进行动态分析和反演,考虑时间和空间的变化因素,建立更符合实际情况的地震模型。
三、RTM研究
该部分参考张星移师兄的博客:2023 7.10~7.16 周报 (RTM研究与正演的Python复现) (8.3更新)-CSDN博客
叠前逆时偏移技术是一种地震成像技术,其原理基于双程波波动方程,利用各检波点接收到的波形信号,沿时间轴逆推求解波动方程,得到反向延拓波场。再从震源处求解波动方程,正向得到震源的传播波场。将得到的两个波场利用一定的成像条件进行成像,最后把所有炮点的成像剖面叠加起来,就得到了地层模型的偏移成像效果图。
大致步骤:
- 首先,需要一个模型来描述地下介质的速度结构。这通常是通过地质调查或先前的研究得到的。然后,将这个模型输入到逆时偏移算法中。
- 逆时偏移算法基于波动方程:波动方程是描述地震波在地下介质中传播的数学模型。逆时偏移算法通过逆向求解这个方程,从震源开始,模拟地震波在地下传播的过程。
- 在逆时偏移过程中,需要考虑多次波和干扰波的影响。一种常见的方法是使用匹配追踪(匹配追踪是一种信号处理技术,主要用于信号的稀疏表示和信号恢复。其主要思想是通过不断地匹配和更新,寻找最佳的匹配滤波器,使得经过匹配滤波后的信号能够尽可能地稀疏表示。在地震数据处理中,匹配追踪技术可以用于消除多次波和干扰波的影响,从而提高地震资料的品质和分辨率。)等信号处理技术,对地震数据进行处理,从而削弱或消除多次波和干扰波的影响。
- 最后,通过叠加所有炮点的成像剖面,可以得到地层模型的偏移成像效果图。
导入相关库:
from bruges.filters.wavelets import ricker # 滤波器
import matplotlib.pyplot as plt # 绘制图表和图形
from scipy.signal import convolve # 用于执行一维信号的卷积操作
import skimage.filters # Python图像处理库,包括滤波、变换、分割、特征提取等
import time # 用于导入Python的内置时间模块,用于获取当前时间、格式化时间、计算时间差等
from multiprocessing import Pool # 实现多进程编程
import numpy as np # 支持大量的维度数组与矩阵运算
import scipy.io # 提供了与MATLAB文件格式(.mat文件)的读写功能
import cv2 # 计算机视觉库,提供了丰富的图像处理和计算机视觉功能
import matplotlib
matplotlib.use('TkAgg') # 创建图形用户界面
- from bruges.filters.wavelets import ricker:
bruges:用于石油和地质领域的数据处理和分析,提供了很多用于地震数据处理的工具和功能;
filters.wavelets:Bruges库中的一个子模块,它提供了与小波相关的功能和工具;
ricker:Ricker小波在信号处理和地震学中经常被用作滤波器或分析工具;
- from scipy.signal import convolve
scipy:是一个开源的Python数学、科学和工程库,SciPy库提供了大量的数学函数、算法和工具,用于科学计算、数据分析、信号处理、线性代数等;
signal:是SciPy库中的一个子模块,专门用于信号处理,提供了各种信号处理相关的函数和工具,用于分析、处理和变换信号;
convolve:是scipy.signal模块中的一个函数,用于执行一维信号的卷积操作;
- import skimage.filters
skimage:scikit-image库的缩写,是一个开源的Python图像处理库,提供了丰富的图像处理功能,包括滤波、变换、分割、特征提取等。
filters:skimage库中的一个子模块,专门用于实现各种图像滤波算法,提供了多种滤波器函数,如高斯滤波、中值滤波、边缘检测等。
- from multiprocessing import Pool
multiprocessing:用于实现多进程编程;
Pool:multiprocessing模块中的一个类,用于管理进程池,可以将一个可迭代对象中的任务分配给多个进程来并行处理;
在下面的介绍中使用到的是SEG盐数据(OpenFWI的数据还有问题没有调试完成),以下是SEG盐数据的基本参数:
| 正演间隔(像素点之间的间隔) | 震源频率(Hz) |
采样间距 | 炮数 | 接收器范围 | 接收器数量 | 时间采样 | |
| 10m | 25Hz | 103.45m | 29 | 10m | 301 | 2000 |
加载数据,并对数据进行一些处理与转换:
# 共炮道集的地震数据
csg = np.load("seismic1668.npy")[0]
# 速度模型
vmod = scipy.io.loadmat('vmodel1668.mat')["data"].astype(np.float64)
# 恢复到原本的时间采样个数
csg = np.array([cv2.resize(image, dsize=(301, 2000), interpolation=cv2.INTER_CUBIC) for image in csg])
# 应用高斯滤波器(标准差设置为5)
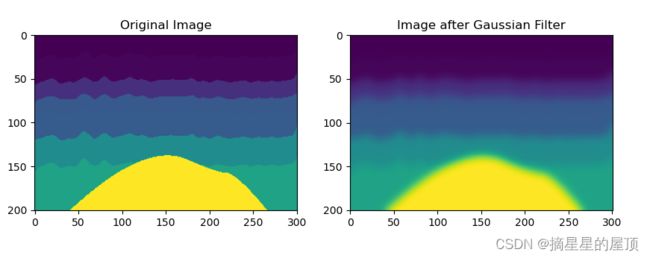
init_vmodel = skimage.filters.gaussian(vmod, 5)
# 显示原始和滤波后的图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(vmod)
plt.title('Original Image')
plt.subplot(1, 2, 2)
plt.imshow(init_vmodel)
plt.title('Image after Gaussian Filter')
plt.show()原始和滤波后的图像展示:
挑选参与RTM计算的炮集:
# 挑选参与RTM计算的炮集 (若炮集数量不是太大, 建议全部加入, SEG略大, 故做删减)
sx_list = [20, 60, 100, 140, 180, 220, 260]
mapping_indice = np.array([1, 5, 9, 13, 17, 21, 25])
# 全部导入
# sx_list = list(range(10, 291, 10))
# mapping_indice = np.arange(29)
csg = csg[mapping_indice]
RTM = construct_rtm(common_shot_gathers=csg,
init_vmodel=init_vmodel,
dx=10, dz=10,
sx_list = sx_list,
sz=0, dt=0.001, nt=2000, f0=25, source_time=0.08,
temp_process_batch_list=[4,3])
# temp_process_batch_list=[4,4,4,4,4,4,4,1]) # temp_process_batch_list总和等于炮位个数, 表示一次同时计算多少个程序块
- common_shot_gather: 单炮的地震观测记录
- init_vmodel: 初始速度模型
- dx: 网格的x轴间隔大小
- dz: 网格的z轴间隔大小
- sx: 炮源的x轴位置 (10, 20, ...)
- sz: 炮源的z轴位置 (一般设为0)
- dt: 时间采样最小间隔多少秒
- nt: 时间采样点的个数
- f0: 震源频率
- source_time: 震源持续时间
震源设置:在2000个时域采样点中,在前121个采样点设置雷克子波的震源,即2s中的前0.121内进行释放(调用库)
source_wav = ricker(duration=source_time, dt=dt, f=f0)[0] # 定义波形(雷克子波)消除走时信息: (在师兄博客写的是前向波,但是提及前向波不能完全取代走时信息,我觉得这里还是理解为走时信息好一些)
- 走时信息是地震勘探中用来了解地下地质构造的重要参数之一,它是指地震波从震源传播到各个接收点的传播时间(获取这个时间通过路程除以速度即可)。
- 前向波是地震波在地下传播过程中遇到反射界面时发生反射,再继续向前传播的地震波。
# 走时信息
muted_gather = common_shot_gather.copy() # 复制单炮的地震观测记录
x_array = np.arange(0, nx*dx, dx) # 基于采样进行标点, 得到地表处每个标点的数组 [0米, dx米, 2dx米, 3dx米, ... , (nx-1)dx米]
v0 = init_vmodel[0,:] # v0表示地表一层的默认地层速度值 (长度为nx的数组)
# np.cumsum(dx/v0)表示在地表第一层区域内, 波从左到右传播的用时数组 [dx/v0秒, 2dx/v0秒, 3dx/v0秒 ...]
# ...[isx]自然是指的传到中间点的用时
# 相减后就得到中间出发向左右两边传递的波在不同位置的时间 [... -2dx/v0秒, -dx/v0秒, 0秒, dx/v0秒, 2dx/v0秒 ...]
traveltimes = abs(np.cumsum(dx/v0) - np.cumsum(dx/v0)[sx])
for traceno in range(len(x_array)):
muted_gather[0:int(traveltimes[traceno]/dt + source_wave_duration), traceno] = 0 # 最后加上len(wav1)是雷克子波的时间, 因为雷克子波能量完全释放需要时间
上形波和下形波是根据震源到地表的传播路径的不同来划分的。在地面激发,井中各点接收时,可记录到各种波,如直达波、反射波、多次波等。这些波就其传播方向可分为两类:一为下行波,二为上行波。直达波和二次反射波为下行波,一次反射波为上行波。
construct_rtm函数获取RTM图像部分介绍:
# 创建一个填充零值的数组
RTM = np.zeros([len(sx_list), init_vmodel.shape[0], init_vmodel.shape[1]])
process_list = []
process_batch_list = temp_process_batch_list # 设置每次进程池大小 (总和与炮数一致)
init_index = 0
# 创建进程池
for max_process_num in process_batch_list:
pool = Pool(processes = max_process_num) # 设置进程池大小
index_range = range(init_index, init_index + max_process_num) # 设置当前进程池中的序号
# 将进程分配出去
for index in index_range:
source_x = sx_list[index]
# apply_async用于异步地运行一个函数,并返回一个AsyncResult对象;single_shot_rtm是异步运行的函数,后面的参数是传递给该函数的
# 并发地运行 single_shot_rtm 函数,并将结果添加到 process_list 列表中。每个进程的参数都通过传递给 .apply_async() 的参数来指定
process_list.append(pool.apply_async(single_shot_rtm,(common_shot_gathers[index], init_vmodel, dx, dz, source_x, sz, dt, nt, f0, source_time)))
# 确保所有任务都执行并且进程池被关闭
pool.close() # 确保不再添加更多任务,已经提交给进程池的任务将继续执行直到完成
pool.join() # 等待所有任务完成
# 接受各个进程的结果
for index in index_range:
RTM[index] = process_list[index].get()
init_index += (max_process_num * 1)
time_elapsed = time.time() - ti
print("均完成! 总用时{:.0f}m {:.0f}s".format(time_elapsed // 60, time_elapsed % 60))
# np.save(output_dir + "seismic{}.npy".format(vmodel_id), CSG)
return RTM下图是一个结果展示,但是距离师兄博客中展示的效果还差很远,这个问题还没有解决。

四、遇到的问题及解决
4.1 KeyError: 'data'
问题描述:正在尝试访问字典中不存在的键

问题解决:查看其中关键字,将data修改为svmodel

4.2 将mat文件转换为npy文件
在代码中涉及到npy的SEG盐数据,但是我没有npy格式,所以就想到可以将mat文件进行转换。

在Pycharm中,可以编写以下Python脚本来转换.mat文件到.npy文件:
import scipy.io
import numpy as np
# 通过scipy.io读取.mat文件:
data = scipy.io.loadmat('D:\\桌面\\地震反演\\FCNVMB_paper_with_code1\\data\\train_data\\SimulateData\\vmodel_train\\vmodel1.mat')
# 假设字典中'vmodel'是你要的数据:
data = data['vmodel']
# 转换为.npy文件:
numpy_data = np.array(data)
# 保存为numpy数组文件(.npy文件)
np.save('vmodel1601.npy', numpy_data)
可以使用numpy的load函数检查生成的文件是否正确:
data = np.load('vmodel1601.npy',allow_pickle=True)
print(data)五、小结
5.1 存在的问题及疑惑
(RTM)为什么效果差距这么大,还没找到原因,猜测可能是数据不对?
5.2 下周安排
下周把Deep learning Inversion of Seismic Data论文读完。