《Pyramid Attention Networks for Image Restoration》阅读笔记
一、论文
《Pyramid Attention Networks for Image Restoration》
摘要:自相似性是指先前在图像恢复算法中广泛使用的图像,在不同的位置和比例上往往会出现小的但相似的图案。 但是,最近的基于深度卷积神经网络的高级图像恢复方法没有依靠仅处理相同规模信息的自注意神经模块来充分利用自相似性。 为了解决这个问题,我们提出了一种新颖的金字塔注意力模块,用于图像恢复,该模块从多尺度特征金字塔中捕获远程特征对应关系。 受诸如噪声或压缩伪影之类的损坏在较粗的图像比例下急剧下降这一事实的启发,我们的注意力模块设计为能够从较粗的级别的“干净”对应中借用干净的信号。 一个通用的构建块,可以灵活地集成到各种神经体系结构中。通过对多种图像恢复任务的广泛实验来验证其有效性:图像去噪,去马赛克,压缩伪像减少和超分辨率。我们的PANet(金字塔形) 具有简单网络主干的注意力关注模块)可以产生具有卓越准确性和视觉质量的最新结果。
二、网络结构
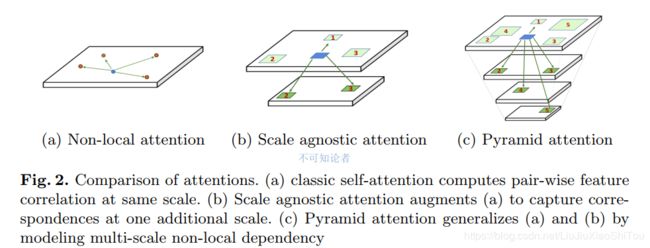
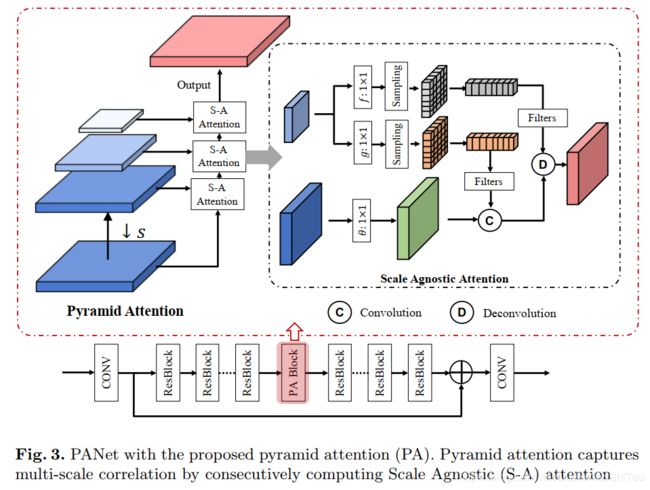
PANet网络结构也比较简单,就是在残差块中间加入了PA Block。多尺度特征提取和注意力机制的完美结合,
三、代码
虽然结构比较简单,但是其中的Samping模块和一些代码感觉还是不太好懂。
https://github.com/SHI-Labs/Pyramid-Attention-Networks
class PyramidAttention(nn.Module):
def __init__(self, level=5, res_scale=1, channel=64, reduction=2, ksize=3, stride=1, softmax_scale=10, average=True, conv=common.default_conv):
super(PyramidAttention, self).__init__()
self.ksize = ksize
self.stride = stride
self.res_scale = res_scale
self.softmax_scale = softmax_scale
self.scale = [1-i/10 for i in range(level)]
self.average = average
escape_NaN = torch.FloatTensor([1e-4])
self.register_buffer('escape_NaN', escape_NaN)
self.conv_match_L_base = common.BasicBlock(conv,channel,channel//reduction, 1, bn=False, act=nn.PReLU())
self.conv_match = common.BasicBlock(conv,channel, channel//reduction, 1, bn=False, act=nn.PReLU())
self.conv_assembly = common.BasicBlock(conv,channel, channel,1,bn=False, act=nn.PReLU())
def forward(self, input):
res = input
#theta
match_base = self.conv_match_L_base(input) #输入首先进行1*1卷积,通道数减半
shape_base = list(res.size())
input_groups = torch.split(match_base,1,dim=0) # torch.split()作用将tensor分成块结构
# patch size for matching
kernel = self.ksize # kernel = 3
# raw_w is for reconstruction
raw_w = []
# w is for matching
w = []
#build feature pyramid
for i in range(len(self.scale)):
ref = input
if self.scale[i]!=1:
ref = F.interpolate(input, scale_factor=self.scale[i], mode='bicubic')
#feature transformation function f
base = self.conv_assembly(ref) #通道数不变的1*1卷积
shape_input = base.shape
#sampling
raw_w_i = extract_image_patches(base, ksizes=[kernel, kernel],
strides=[self.stride,self.stride],
rates=[1, 1],
padding='same') # [N, C*k*k, L]
raw_w_i = raw_w_i.view(shape_input[0], shape_input[1], kernel, kernel, -1)
raw_w_i = raw_w_i.permute(0, 4, 1, 2, 3) # raw_shape: [N, L, C, k, k] #将tensor的维度换位
raw_w_i_groups = torch.split(raw_w_i, 1, dim=0)
raw_w.append(raw_w_i_groups) #raw_w形成的是经过F函数之后下采样
#feature transformation function g
ref_i = self.conv_match(ref)
shape_ref = ref_i.shape
#sampling
w_i = extract_image_patches(ref_i, ksizes=[self.ksize, self.ksize],
strides=[self.stride, self.stride],
rates=[1, 1],
padding='same')
w_i = w_i.view(shape_ref[0], shape_ref[1], self.ksize, self.ksize, -1)
w_i = w_i.permute(0, 4, 1, 2, 3) # w shape: [N, L, C, k, k]
w_i_groups = torch.split(w_i, 1, dim=0)
w.append(w_i_groups) # w形成的是经过F函数之后下采样
y = []
for idx, xi in enumerate(input_groups):
#group in a filter
wi = torch.cat([w[i][idx][0] for i in range(len(self.scale))],dim=0) # [L, C, k, k]
#normalize
max_wi = torch.max(torch.sqrt(reduce_sum(torch.pow(wi, 2),
axis=[1, 2, 3],
keepdim=True)),
self.escape_NaN)
wi_normed = wi/ max_wi
#matching
xi = same_padding(xi, [self.ksize, self.ksize], [1, 1], [1, 1]) # xi: 1*c*H*W #使用0填充以一圈
yi = F.conv2d(xi, wi_normed, stride=1) # [1, L, H, W] L = shape_ref[2]*shape_ref[3] #进行卷积操作
yi = yi.view(1,wi.shape[0], shape_base[2], shape_base[3]) # (B=1, C=32*32, H=32, W=32)
# softmax matching score
yi = F.softmax(yi*self.softmax_scale, dim=1)
if self.average == False:
yi = (yi == yi.max(dim=1,keepdim=True)[0]).float()
# deconv for patch pasting
raw_wi = torch.cat([raw_w[i][idx][0] for i in range(len(self.scale))],dim=0)
yi = F.conv_transpose2d(yi, raw_wi, stride=self.stride,padding=1)/4.
y.append(yi)
y = torch.cat(y, dim=0)+res*self.res_scale # back to the mini-batch
return y