大数据之路 -- 常用辅助框架
数据转换工具sqoop:
Apache的顶级项目,官方网站http://sqoop.apache.org/
Apache Sqoop(TM)是一种设计工具,用于在Apache Hadoop和结构化数据存储(如关系数据库)之间高效地传输大量数据。
将MapReduce程序组成,打包成jar形成Sqoop,充分使用了MR并行计算的特点加快数据传输,是连接传统型数据库和hadoop的桥梁(关系型数据库数据导入hadoop与其相关的系统中 / 把hadoop系统中数据抽取到关系型数据)
用于MySQL,Oracle 等与HDFS、HIVE、HBASE之间的数据导入和导出
sqoop1与sqoop2比较:
Sqoop1就是一个客户端
Sqoop2引入了服务器相关概念,可以进行集中化管理connector,多种访问方式(CLI,WEB,REST api),安全机制等。
Sqoop1简单好用
sqoop2缺点:命令行的方式比较复杂,不能支持所有的数据类型,安全机制并不够完善,部署比较繁琐
sqoop2优点:引入了服务器相关概念,可以进行集中化管理connector,多种访问方式(CLI,WEB,REST api),安全机制等
文件收集框架flume:
官方网站:http://flume.apache.org/
用户手册:http://flume.apache.org/FlumeUserGuide.html
Flume是一种分布式的(获取数据的来源众多,可以同时进行操作)、可靠的和可用的服务,用于高效地收集、聚集和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构(编写一个配置文件就可以)。它具有健壮性和容错性,具有可调整的可靠性机制和许多故障转移和恢复机制。它使用了一个简单的可扩展的数据模型,允许在线分析应用程序。
实时收集数据,经常与storm/spark集成进行使用(还有kafka进行数据收集)
运行需求jvm,且只能在linux系统上运行(数据源不在linux该怎么办,可以通过将NFS将windows目录挂载到Linux上)

Events:
Event是Flume数据传输的基本单元
Flume以事件的形式将数据从源头传送到最终的目的
Event由可选的header和载有数据的字节数组byte array构成,载有的数据对flume是不透明的(flume只负责传输,并不清除传输的是什么),Header是容纳了key-value的无序集合,key在集合内是唯一的,Header可以在上下文路由中使用扩展
Agent:
Flume的核心,同时也是最小的运行单位
一个agent就是一个jvm
Source:
封装数据成event,并且存入到channel
类型:AVRO Source,LOG4J Source,SYSLOG Source,jms Source,自定义Source
Channel
扮演者中间人的角色,可以理解成数据的缓冲区,队列的形式进行操作的
将事件暂存在内存中,也可以持久化到本地磁盘,知道sinks将数据传递结束(sink必须达到下一个agent或者存入到外部目的地之后,才会将时间remove掉)
类型:memory Channel,file channel,JDBC Channel,kafka channel,自定义channel
Sink:
也可以发送到其他agent的source
数据丢失:
Flume提供了三种方式处理此种错误
End-to-end:收到数据agent首先会把数据写到磁盘,等待传输成功后再删除,如果传输失败,再次发送
Store on failure:若接收方crash,再把数据写到本地,等待对方恢复之后继续发送
Besteffort:等待数据发送到接收方之后,不会进行确认
任务调度框架oozie:
Oozie是一个用于管理Apache Hadoop作业的工作流调度系统。
同类型还有azkaban ,zeus ,crontab
Crontab:针对每个用户而言,简单调度,没有展示界面
Azkaban:批量工作流任务调度器,出现了展示界面
Zeus:阿里开源的框架,名字图标来自dota,增加了任务调度界面,统计页面
Oozie:功能强大,极适合数据仓库类的业务
oozie流程图
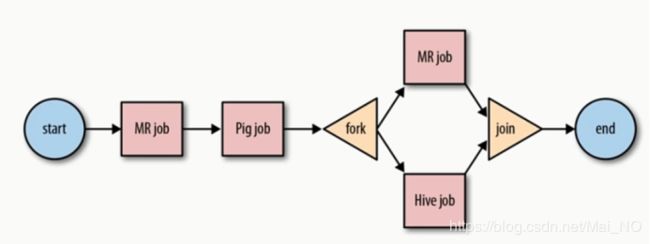
组件:
workflow job(工作流), coordinator job(定时任务),bundies job(基于多个workflow和多个Coordinator之间的调度)
针对不同的任务,改写不同的workflow模板
大数据web工具Hue:
用户手册:
http://gethue.com/
http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/manual.html#_install_hue
Hue是开源免费,使用浏览器进行查询,浏览和展示数据的,兼容性非常好。即可用于查看各个大数据框架的运行情况,而不必去看每一个不同的框架的不同WebUi