Python文件(File)及读写操作及生成器yield
Python文件读写机制
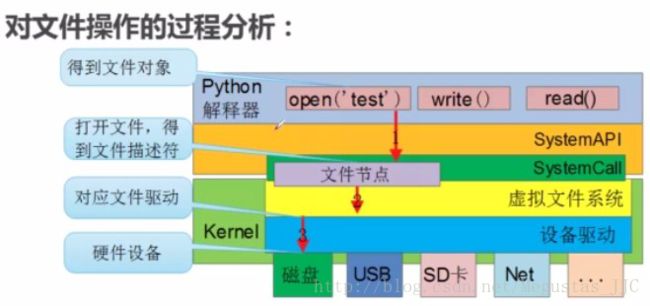
open函数在内存中创建缓存区,将磁盘上的内容复制到此处。文件内容读入到文件对象缓冲区后,文件对象将缓冲区视为非常大的列表,其中每个元素都有一个索引。文件对象按字节(大约每个字符)来对文件对象缓冲区索引计数。许多文件方法隐式使用当前文件位置。例如,调用readline方法后,当前文件位置移动到下一个回车处。write方法在当前文件位置写入。
Python方法用于当前位置文件:
tell()方法:此方法用于当前文件位置和文件开始位置之间的相对位置,用字节进行计算
seek()方法:此方法将当前文件位置设为文件对象缓冲区中的新位置,seek方法有两个参数,第一个参数是字节数目,第二个参数是引用点。当前文件指针从引用点开始,移动给出的字节数目
典型用法:fd.seek(0),将当前文件位置重置为文件对象fd的开始位置。
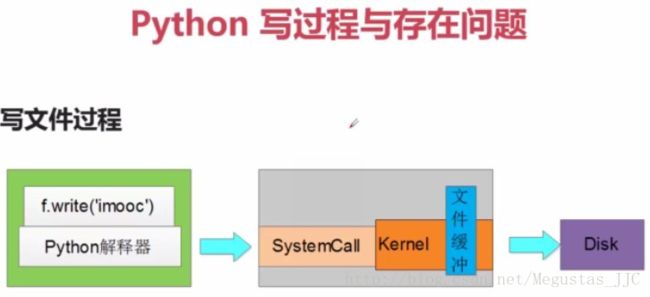
当调用write(str)时,python解释器调用系统调用想把把内容写到磁盘,但是linux内核有文件缓存机制,所以缓存到内核的缓存区,当调用close()或flush()时才会真正的把内容写到文件
或者写入数据量大于或者等于写缓存,写缓存也会同步到磁盘上
关闭文件的目的
1:写缓存同步到磁盘
2:linux系统中每个进程打开文件的个数是有限的
3:如果打开文件数到了系统限制,在打开文件就会失败
with open("temp.txt","r") as f:
pass如上的代码不需要人为的进行close()语句的关闭,当脱离with这段代码时(即缩进与with相同),将会自动的进行close操作,如上代码可以等价看作:
f = open("temp.txt","r")
pass
f.close()CSV文件
CSV是一种文件格式(特别是存储表格数据,例如excel),实际上是文本文件,可以使用文本文件函数和方法。
Python提供了csv模块
要处理CSV格式的文件,需要一些新的对象。csv.reader对象读取文件(使用reader构造函数创建reader对象,参数是文件对象),csv.writer对象写CSV文件,csv.writer对象通过使用方法writerow来将数据行写入。
import csv
fObjt = open("Work.csv","rU")
csvReader = csv.reader(fObjt)
sheet = []
for row in csvReader:
print row
#遍历每行,sheet是一个二维列表(一维列表是行)
sheet.append(row)
fObjt.close()
writeFileObj = open("WorkBook.csv","w")
writer = csv.writer(writeFileObj)
for row in sheet:
writer.writerow(row)
writeFileObj.close()小技巧:由于raw_input返回值是字符串,因此可以直接用该字符串作为open命令的参数
fileName = raw_input("Open what file:")
inFile = open(fileName,"r")目录/文件夹的结构
目前流行的操作系统将文件放于目录结构中。这个假定的特殊容器,在Linux和OS-X中称为目录,在Windows中称为文件夹,每个目录完成三件事情:
- 目录中有文件列表
- 目录中包含其他目录的列表
- 目录中包含其父目录的链接
操作系统从根目录(“/”)开始查找文件,沿着树结构的边向下移动。不同操作系统中路径的表示方式略有不同,Linux和MAC OS是“/”表示风格,Windows使用反斜杠(\)表示。
OS模块
os.getcwd函数,getcwd函数是指获取当前目录
os.chdir函数,更改目录,将当前工作目录改变为参数所给出的路径
os.listdir函数,列出路径参数所指定节点中所有文件和目录。函数返回的值可以命名
os.walk函数,遍历路径,其中os.walk(“.”)表示从当前目录开始遍历
还有split函数,split ext函数和join函数将在如下例子中举例。
需求如下:
在每个目录中,检查该目录下的每个文件是否为文本文件(扩展为“.txt”)。如果是文本文件,则打开它,读取内容,然后查看特定字符串是否在文件中。如果找到特定字符串,则将文件添加到文件列表,将目录添加到目录列表。完成文件搜索后输出找到的内容。
# search for a string:
# starting from the current directory,walk a directory tree
# look in all text files for the string
import os
def check(searchStr,count,fileList,dirList):
for dirName,dirs,files in os.walk("."): #walk the subtree
for f in files:
if os.path.splitext(f)[1] == ".txt":
count += 1
aFile = open(os.path.join(dirName,f),"r")
fileStr = aFile.read()
if searchStr in fileStr:
fileName = os.path.join(dirName,f)
fileList.append(fileName)
if dirName not in dirList:
dirList.append(dirName)
aFile.close()
return count
theStr = raw_input("what string to look for:")
fileList = []
dirList = []
count = 0
count = check(theStr,count,fileList,dirList)
print "Looked at %d text files" % (count)
print "Found %d directories containing files with .txt suffix and target string : %s" % (len(dirList),theStr)
print "Found %d files containing files with .txt suffix and target string : %s" % (len(dirList),theStr)
print "\n----Directory List----"
for d in dirList:
print d
print "\n----File List----"
for f in fileList:
print f生成器yield
(注:在多线程的时候可以用yield创建线程池)
生成器不会把结果保存在一个系列中,而是保存生成器的状态,在每次进行迭代时返回一个值,直到遇到StopIteration异常结束。
生成器表达式: 通列表解析语法,只不过把列表解析的[]换成()
生成器表达式能做的事情列表解析基本都能处理,只不过在需要处理的序列比较大时,列表解析比较费内存。
>>> gen = (x**2 for x in range(5))
>>> gen
at 0x0000000002FB7B40>
>>> for g in gen:
... print(g, end='-')
...
0-1-4-9-16-
>>> for x in [0,1,2,3,4,5]:
... print(x, end='-')
...
0-1-2-3-4-5- 生成器函数: 在函数中如果出现了yield关键字,那么该函数就不再是普通函数,而是生成器函数。yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator。
#生成器,仅当使用的时候才真正创建值
print xrange(10)
for item in xrange(10):
print itemdef foo():
yield 1
yield 2
yield 3
re = foo() #返回的是一个生成器,当进行遍历的时候才产生值,并且每次只执行一条
print re
for item in re:
print item
yield 与 return:
在一个生成器中,如果没有return,则默认执行到函数完毕时返回StopIteration(可以使用next方法来避免阻塞的产生);
>>> def g1():
... yield 1
...
>>> g=g1()
>>> next(g) #第一次调用next(g)时,会在执行完yield语句后挂起,所以此时程序并没有执行结束。
1
>>> next(g) #程序试图从yield语句的下一条语句开始执行,发现已经到了结尾,所以抛出StopIteration异常。
Traceback (most recent call last):
File "" , line 1, in
StopIteration
>>> 如果遇到return,如果在执行过程中 return,则直接抛出 StopIteration 终止迭代。
>>> def g2():
... yield 'a'
... return
... yield 'b'
...
>>> g=g2()
>>> next(g) #程序停留在执行完yield 'a'语句后的位置。
'a'
>>> next(g) #程序发现下一条语句是return,所以抛出StopIteration异常,这样yield 'b'语句永远也不会执行。
Traceback (most recent call last):
File "" , line 1, in
StopIteration close()
手动关闭生成器函数,后面的调用会直接返回StopIteration异常。
>>> def g4():
... yield 1
... yield 2
... yield 3
...
>>> g=g4()
>>> next(g)
1
>>> g.close()
>>> next(g) #关闭后,yield 2和yield 3语句将不再起作用
Traceback (most recent call last):
File "" , line 1, in
StopIteration