【机器学习算法笔记系列】线性回归算法详解和实战
线性回归算法
算法概述
在统计学中,线性回归(Linear Regression) 是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是由一个或多个称为回归系数的模型参数的线性组合而成。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
算法原理



算法优缺点
优点
- 模型简单,易于建模,应用广泛,它还有多种推广形式,常见的广义线性模型包括:岭回归、lasso回归、Elastic Net、逻辑回归、线性判别分析(LDA) 等。
- 结果具有很好的可解释性(
权重W直观表达了各属性在预测中的重要性)。
缺点
- 只对线性数据拟合较好,对非线性数据拟合不好,目前数据往往是非线性居多。
Python实践
scikit-learn中提供了一个LinearRegression类来实现线性回归模型。LinearRegression
其原型为:sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_x=True, n_jobs=1)
参数
fit_intercept:boolean型,指定是否需要计算b值(截距)。如果为False,则不计算b值。
normalize:boolean型,如果为True,那么训练样本在回归之前会被归一化。
copy_x:boolean型,如果为True,则会复制x。
n_jobs:任务并行时指定的CPU的数量。如果为-1,则使用所有可用的CPU。
属性
coef_:权重向量
intercept_:b值
方法
fit(X, y[, sample_weight]):训练模型。
predict(X):用模型进行预测,返回预测值。
score(X, y[, sample_weight]):返回模型预测性能得分。
- score不超过1,但可能为负值(预测效果太差)。score值越大,模型预测性能越好。
线性回归实战—预测波士顿房价
本文使用线性回归算法,对波士顿房价进行预测,scikit-learn中自带波士顿房价数据集,我们直接导入即可,如有需要csv文件,可自行百度搜索下载,这里不做过多阐述。
首先,我们加载数据,输出数据形状和特征。以查看数据:
__author__ = "fpZRobert"
"""
线性回归实战—波士顿房价预测
"""
from sklearn.datasets import load_boston
"""
加载数据
"""
boston = load_boston()
X = boston.data
y = boston.target
print("Shape of X: ", X.shape) # 查看数据的形状
print("Boston data feature name: ", boston.feature_names) # 查看数据的特征
数据一共包含13个特征,共有506个样本,这13个特征分别如下:

| 特征 | 含义 |
|---|---|
| CRIM | 城镇人均犯罪率 |
| ZN | 住宅用地所占比例 |
| INDUS | 城镇中非住宅用地所占比例 |
| CHAS | 是否靠近河边,1为靠近,0为远离 |
| NOX | 一氧化氮浓度 |
| RM | 每套房产的平均房间个数 |
| AGE | z在1940年之前就盖好,且业主自住的房子的比例 |
| DIS | 与波士顿市中心的距离 |
| RAD | 周边高速公路的便利性指数 |
| TAX | 每10000美元的财务税率 |
| PTRATIO | 小学老师的比例 |
| B | 城镇黑人的比例 |
| LSTAT | 地位较低的人口比例 |
把数据集划分为训练集和测试集(划分比例一般80%用于训练,20%用于测试):
"""
构造训练集和测试集
"""
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=3)
使用线性回归算法对数据集进行拟合,并计算评分:
"""
训练模型
"""
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train) # 查看训练集得分
cv_socre = model.score(X_test, y_test) # 查看测试集得分
print("train_score: {:.6f}, cv_score: {:.6f}".format(train_score, cv_socre))
Out:
train_score: 0.723941, cv_score: 0.795262
从训练集和测试集得分情况来看,模型拟合的效果一般,那么有什么办法来优化模型的拟合效果呢?
首先观察数据,特征数据的范围相差比较大,我们需要先把数据进行归一化处理,归一化处理最简单的方式就是在创建线性模型时将normalize参数设置为True。
model = LinearRegression(normalize=True) # 进行归一化处理
但数据归一化只会加快算法收敛速度,优化算法训练的效率,无法提升模型的性能。那么如何提高模型的准确性呢?其实,观察训练集的评分(train_socre=0.723941)就可以知道,模型出现欠拟合现象。对于优化欠拟合问题,有两种方案,一是挖掘更多的输入特征,二是增加多项式特征(增加模型的复杂度)。这里,我们通过使用增加多项式特征方案看看能否优化模型的性能。
"""
模型优化
"""
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
# 构建多项式模型
def polynomial_model(degree=1):
polynomial_features = PolynomialFeatures(degree=degree, include_bias=False)
linear_regression = LinearRegression(normalize=True)
pipeline = Pipeline([("polynomial_feature", polynomial_features), ("linear_regression", linear_regression)])
return pipeline
# 使用二阶多项式来拟合数据
model = polynomial_model(degree=2)
model.fit(X_train, y_train)
train_score_V2 = model.score(X_train, y_train) # 查看训练集得分
cv_score_V2 = model.score(X_test, y_test) # 查看测试集得分
print("train_score: {:.6f}, cv_score: {:.6f}".format(train_score_V2, cv_score_V2))
# 使用三阶多项式来拟合数据
model = polynomial_model(degree=3)
model.fit(X_train, y_train)
train_score_V3 = model.score(X_train, y_train) # 查看训练集得分
cv_socre_V3 = model.score(X_test, y_test) # 查看测试集得分
print("train_score: {:.6f}, cv_score: {:.6f}".format(train_score_V3, cv_socre_V3))
Out:
train_score: 0.930547, cv_score: 0.860049
train_score: 1.000000, cv_score: -104.264902
通过使用二阶多项式、三阶多项式来拟合数据,发现:训练集分数和测试集分数都有不少的提高,说明,利用多项式特征方案来优化模型是非常有效的,但我们观察三阶多项式发现,尽管训练集分数达到了最好,但测试集分数却是负数,说明模型过拟合了。下面,我们画出这三种方案的学习曲线来进一步说明情况:

由上图可知:一阶多项式欠拟合(左图),因为针对训练样本的分数比较低;而三阶多项式过拟合(右图),因为针对训练样本的分数已达到最优(最高=1),但看不到针对交叉验证集的分数;针对二阶多项式拟合的情况,虽然比一阶多项式效果好,但从图中明显看出,训练集的分数和交叉验证集的分数之间的间隙比较大,此现象说明训练样本数量不够,应该采集更多的数据来提高模型的准确性。
全部代码:
__author__ = "fpZRobert"
"""
线性回归实战—波士顿房价预测
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import learning_curve
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import train_test_split
"""
加载数据
"""
boston = load_boston()
X = boston.data
y = boston.target
print("Shape of X: ", X.shape) # 查看数据的形状
print("Boston data feature name: ", boston.feature_names) # 查看数据的特征
"""
构造训练集和测试集
"""
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=3)
"""
训练模型
"""
model = LinearRegression()
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train) # 查看训练集得分
cv_socre = model.score(X_test, y_test) # 查看测试集得分
print("train_score: {:.6f}, cv_score: {:.6f}".format(train_score, cv_socre))
"""
模型优化
"""
# 构建多项式模型
def polynomial_model(degree=1):
polynomial_features = PolynomialFeatures(degree=degree, include_bias=False)
linear_regression = LinearRegression(normalize=True)
pipeline = Pipeline([("polynomial_feature", polynomial_features), ("linear_regression", linear_regression)])
return pipeline
# 使用二阶多项式来拟合数据
model = polynomial_model(degree=2)
model.fit(X_train, y_train)
train_score_V2 = model.score(X_train, y_train) # 查看训练集得分
cv_socre_V2 = model.score(X_test, y_test) # 查看测试集得分
print("train_score: {:.6f}, cv_score: {:.6f}".format(train_score_V2, cv_socre_V2))
# 使用三阶多项式来拟合数据
model = polynomial_model(degree=3)
model.fit(X_train, y_train)
train_score_V3 = model.score(X_train, y_train) # 查看训练集得分
cv_socre_V3 = model.score(X_test, y_test) # 查看测试集得分
print("train_score: {:.6f}, cv_score: {:.6f}".format(train_score_V3, cv_socre_V3))
"""
绘制学习曲线
"""
# 绘制学习曲线
def plot_learning_curve(plt, estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o--', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
plt.figure(figsize=(18, 4), dpi=200)
title = "Learning Curves (degree={0})"
degrees = [1, 2, 3]
for i in range(len(degrees)):
plt.subplot(1, 3, i+1)
plot_learning_curve(plt, polynomial_model(degrees[i]), title.format(degrees[i]), X, y, (0.01, 1.01), cv)
plt.show()
实战进阶
上文所做的工作主要在于模型优化,但缺少数据分析和特征选择的部分。因波士顿房价数据集数量太少,不适合做有效的数据分析,但在这里可以提及一下,提供思路:
- 数据是否完全可靠?
- 所有特征是否都发挥巨大作用,或者说哪些数据对预测的结果影响较小?
首先,我们利用热力图来观察一下特征与Target的关系:
"""
波士顿房价预测进阶
"""
import seaborn as sns
boston = load_boston()
boston_df = pd.DataFrame(boston["data"], columns=boston.feature_names)
boston_df["Target"] = pd.DataFrame(boston["target"], columns=["Target"])
# print(boston_df.head(5))
# 特征与目标值的相关性分析-热力图
plt.figure(figsize=(20, 16)) # 指定绘图对象宽度和高度
corr = boston_df.corr().sort_values(by=["Target"], ascending=False)
f, ax = plt.subplots(figsize=(20, 9))
sns.heatmap(corr, vmax=.8, annot=True)
plt.show()
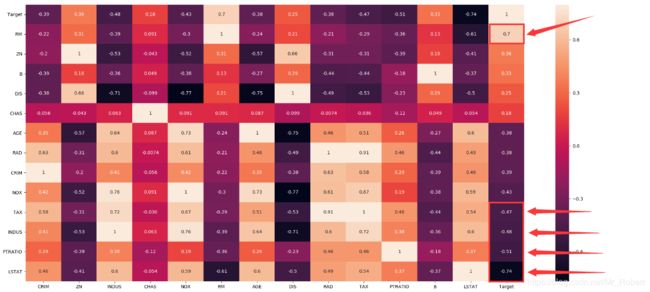
由上图可知,我们发现RM、LSTAT、PTRATIO、INDUS、TAX与Target的相关性最大,我们分析一下:
RM:每套房产的平均房间个数,房间数越多,意味着房屋面积越大,房屋价格越高,这很好理解。LSTAT:地位较低的人口比例,如果人口比例越小,说明该地段地位较高的人口越多,那么这个区域很大可能是非富即贵的群体,那么房价越高,这也很好理解。PTRATIO:小学老师的比例,小学老师比例越少,房价就越高,这也很好理解,美国重视教育,都想买房的地段有老师。INDUS:城镇中非住宅用地所占比例,那么城镇中非住宅用地所占比例越大,就意味着住宅比例越少,房价自然就高啦。TAX:每10000美元的财务税率,交税确实会很大程度上影响房价。
通过热力图,我们很明显的发现,不同的特征对房价结果的影响都不一样,那么我们是不是可以考虑去除某些不重要的特征呢?但去除特征要非常慎重,要记住两点:(1)数据集样本很大,能较好的表达业务需求,例如波士顿房价数据集能很好的表明波士顿房价的整体情况。(2)存在特征冗余的情况。否则随意去除特征,可能会起反面效果。
接下来,我们看一下特征最高的两个特征RM、LSTAT和房价的关系:


细心的同学可能发现上面两张图的问题了,最上面的50万美金的房价的数据点特别密集,构成了一条直线,估计是数据集采集的时候,大于50W都写成50W的了,所以说数据其实也没有那么可靠,还是存在一些脏数据的,这些脏数据往往对结果造成一些不好的影响。
我们先去掉一些脏数据,看看对模型的影响:
"""
清洗数据
"""
boston = load_boston()
X = boston.data
y = boston.target
X = X[y<50] # 去除那些房价为50的数据
y = y[y<50]
print("Shape of X: ", X.shape) # 查看数据的形状
Out:
Shape of X: (490, 13)
我们去除了大概16条数据,再利用之前的方法,再训练一次模型,计算一下模型得分:
"""
构造训练集和测试集
"""
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=3)
"""
训练模型
"""
model = LinearRegression()
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train) # 查看训练集得分
cv_socre = model.score(X_test, y_test) # 查看测试集得分
print("train_score: {:.6f}, cv_score: {:.6f}".format(train_score, cv_socre))
"""
模型优化
"""
# 构建多项式模型
def polynomial_model(degree=1):
polynomial_features = PolynomialFeatures(degree=degree, include_bias=False)
linear_regression = LinearRegression(normalize=True)
pipeline = Pipeline([("polynomial_feature", polynomial_features), ("linear_regression", linear_regression)])
return pipeline
# 使用二阶多项式来拟合数据
model = polynomial_model(degree=2)
model.fit(X_train, y_train)
train_score_V2 = model.score(X_train, y_train) # 查看训练集得分
cv_socre_V2 = model.score(X_test, y_test) # 查看测试集得分
print("train_score: {:.6f}, cv_score: {:.6f}".format(train_score_V2, cv_socre_V2))
Out:
train_score: 0.779519, cv_score: 0.760425
train_score: 0.938442, cv_score: 0.863285
我们看到,利用二阶多项式拟合数据,较于之前的结果,证明了去除一些脏数据的有效性,当然,这里只是简单介绍,如何正确进行严密的、符合逻辑的数据分析和特征选择,还需要掌握科学的方法。
参考资料
- 【机器学习】线性回归原理推导与算法描述