Java面经
Java
- 对Java的理解
- 平台无关性如何实现
- Java内存模型
- Java基础
- 1. java基本数据类型
- 2. Int 和 Integer 区别,double和float区别
- 3. JDK、JRE、JVM
- 4. 抽象类 、接口
- 5. 浅拷贝、深拷贝、引用拷贝
- 6 ==、equals、Hashcode
- 7 String、StringBuilder、StringBuffer
- 8 Arrays
- 9 public、protected、缺省、private
- 10 参数传递(值传递,引用传递,String)
- 11 封装 继承 多态
- 12 重写&重载
- 13 Static
- 14 final
- 15 try..catch..finally
- 反射
- 异常
- Java创建对象的方式
- 集合
- Collection
- List
- Set
- Collection 和 Collections
- 集合类型的默认容量以及扩容机制:
- Map
- HashMap
- HashTable
- ConcurrentHashMap
- Hash怎么重定向的?
- 并发
- 同步和异步
- 多线程的实现方式
- start() 和 run()的区别
- 如何给run()传参
- 如何处理线程返回值
- sleep和wait的区别
- notify, notifyAll, yeild
- 如何中断线程
- 互斥同步
- Synchronized
- ReentrantLock
- CAS
- Volatile
- 线程池
- JVM
- 类加载:
- 类的生命周期
- 类加载器
- 类加载机制⭐️
- JVM内存结构
- 内存溢出&内存泄漏
- 程序计数器
- 栈
- 堆
- 方法区
- Follow Q:堆和栈的区别是什么?
- 垃圾回收机制
- 哪些内存需要回收?
- 常用垃圾回收算法
- GC何时触发
- IO
- BIO
- NIO
- AIO
- 常用设计模式
- 单例模式
- 观察者模式
- 装饰者模式
- 适配器模式
- 工厂模式
- 代理模式(proxy)
- MVC模式
- 拦截过滤器模式
- Object类
- 读取一个大量的log日志,如何提取所有指定时间戳的日志内容
- Tomcat
- Servlet
对Java的理解
平台无关性如何实现
什么是平台无关性
平台无关性就是一种语言在计算机上的运行不受平台的约束,一次编译,到处执行(Write Once ,Run Anywhere)。
也就是说,用Java创建的可执行二进制程序,能够不加改变的运行于多个平台。
平台无关性好处
作为一门平台无关性语言,无论是在自身发展,还是对开发者的友好度上都是很突出的。
因为其平台无关性,所以Java程序可以运行在各种各样的设备上,尤其是一些嵌入式设备,如打印机、扫描仪、传真机等。随着5G时代的来临,也会有更多的终端接入网络,相信平台无关性的Java也能做出一些贡献。
对于Java开发者来说,Java减少了开发和部署到多个平台的成本和时间。真正的做到一次编译,到处运行。
平台无关性的实现
对于Java的平台无关性的支持,就像对安全性和网络移动性的支持一样,是分布在整个Java体系结构中的。其中扮演者重要的角色的有Java语言规范、Class文件、Java虚拟机(JVM)等。
- Java语言规范
通过规定Java语言中基本数据类型的取值范围和行为。比如,Java中基本数据类型的值域和行为都是由其自己定义的。而C/C++中,基本数据类型是由它的占位宽度决定的,占位宽度则是由所在平台决定的。所以,在不同的平台中,对于同一个C++程序的编译结果会出现不同的行为。
举一个简单的例子,对于int类型,在Java中,int占4个字节,这是固定的。
但是在C++中却不是固定的了。在16位计算机上,int类型的长度可能为两字节;在32位计算机上,可能为4字节;当64位计算机流行起来后,int类型的长度可能会达到8字节。 - Class文件
所有Java文件要编译成统一的Class文件.各种不同的平台的虚拟机都使用统一的程序存储格式——字节码(ByteCode)是构成平台无关性的另一个基石。Java虚拟机只与由自己码组成的Class文件进行交互。
Java语言可以Write Once ,Run Anywhere。这里的Write其实指的就是生成Class文件的过程。
因为Java Class文件可以在任何平台创建,也可以被任何平台的Java虚拟机装载并执行,所以才有了Java的平台无关性。 - Java虚拟机
通过Java虚拟机将Class文件转成对应平台的二进制文件等. Java的平台无关性是建立在Java虚拟机的平台有关性基础之上的,是因为Java虚拟机屏蔽了底层操作系统和硬件的差异。JVM其实并不是和Java文件进行交互的,而是和Class文件,也就是说,其实JVM运行的时候,并不依赖于Java语言。
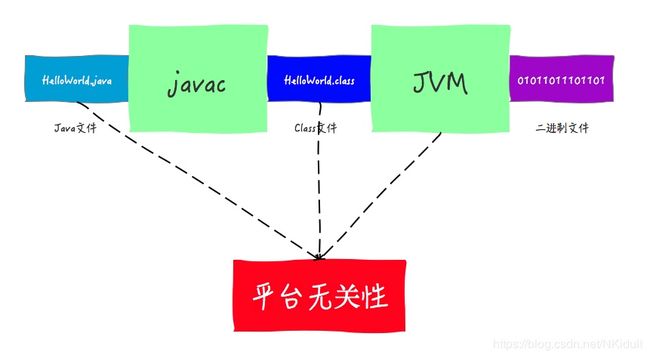
前端编译:javac,我们使用的很多IDE,如eclipse,idea等,都内置了前端编译器。主要功能就是把.java代码转换成.class代码。.class代码,其实就是Class文件。
后端编译主要是将中间代码再翻译成机器语言。Java中,这一步骤就是Java虚拟机来执行的。
平台无关性
Java内存模型
java内存模型(Java Memory Model,JMM)是java虚拟机规范定义的,用来屏蔽掉java程序在各种不同的硬件和操作系统对内存的访问的差异,这样就可以实现java程序在各种不同的平台上都能达到内存访问的一致性。可以避免像c++等直接使用物理硬件和操作系统的内存模型在不同操作系统和硬件平台下表现不同,比如有些c/c++程序可能在windows平台运行正常,而在linux平台却运行有问题。
涉及到挺多东西的,大厂必会哦
Java基础
1. java基本数据类型
整数型:byte、short、int、long (1,2,4,8 一字节8位)
浮点型:float、double、
字符型:char、
布尔型:boolean
(除此之外都是引用)
浮点数默认 double,若想用float,需加后缀F
byte、short、char 都可以进行数值运算
小 -> 大 自动类型转换
大 -> 小 强制转换(损失精度)
具体范围可看
2. Int 和 Integer 区别,double和float区别
Int和Integer的区别:
int 是基本类型,直接存数值, 初始值为0,Integer是int包装类,对象初始值为null。可以有方法和属性,利用这些方法和属性来处理数据,但是用final修饰,属性不可变、方法不可覆盖、类不可继承。
int 是值,存在常量池中。 而 Integer 对象,根据创建方式的不同,在内存中有两种存在形式:
Integer a1 = 1;
Integer a2 = new Integer(1);
对于第一种方式:是做了拆箱,和 int a =1 是相同的。首先会查找常量池中有没有该数据,如果有则直接返回引用,如果没有则在常量池中创建该数据再返回引用。
对于第二种方式:首先查找常量池有没有该数据,如果没有则首先在栈内存创建该引用,在堆内存创建具体对象(new Integer(1)),并且在常量池中创建该对象,返回栈内存的引用;如果有则直接返回栈内存地址的引用。
Integer的引用(值的地址)存储在栈中,而实际的Integer对象(值)是存在堆中,Integer封装类的目的主要是更好的处理数据之间的转换。
== 比较
对于int(基本类型)变量,== 操作符比较的是两个变量的值是否相等;
对于Integer(引用类型)变量,== 操作符比较的是两个引用是否指向同一个对象。
Integer 包装类常用方法
// An highlighted block
Integer a = new Integer(1); // 参数可以是 整数 也可以是 数字型字符串
a = new Integer("1000");
a = Integer.MAX_VALUE; //Java中可以用 Min,Max_VALUE 即 2^31-1
int t = Integer.parseInt("100"); //转整数
t = Integer.parseInt("10",16 );//进制转换
注意:
(1):用new 创建的Integer对象即使数值相等,也是两个拥有不同的内存地址的对象。
Integer i = new Integer(100);
Integer j = new Integer(100);
System.out.println(i==j); //false
System.out.println(i.equals(j)); //true
(2):jvm在运行时创建了一个缓存区域,并创建了一个integer的数组(常量池)。这个数组存储了-128至127的值。因此如果integer的值在-128至127之间,则是去缓存里面获取。超过了这个范围,JVM会new新的对象(即使值相等,也是两个对象)。
Integer a = 500; //此时a进行了装箱操作
Integer b = 500; //此时b也进行了装箱操作,两个数值上是相等的,但是并不是同一个对象。
System.out.println(a == b); //false
System.out.println(a.equals(b)); //true
Float和Double:
float : 单精度浮点数
double : 双精度浮点数
两者的主要区别如下:
-
01.在内存中占有的字节数不同
单精度浮点数在机内存占4个字节
双精度浮点数在机内存占8个字节 -
02.有效数字位数不同
单精度浮点数有效数字8位
双精度浮点数有效数字16位 -
03.数值取值范围
单精度浮点数的表示范围:-3.40E+38~3.40E+38
双精度浮点数的表示范围:-1.79E+308~-1.79E+308 -
04.在程序中处理速度不同
一般来说,CPU处理单精度浮点数的速度比处理双精度浮点数快
如果不声明,默认小数为double类型,所以如果要用float的话,必须进行强转
例如:float a=1.3; 会编译报错,正确的写法 float a = (float)1.3;或者float a = 1.3f;(f或F都可以不区分大小写)
注意:float是8位有效数字,第7位数字将会四舍五入
1.java中3*0.1==0.3将会返回什么?true还是false?
fale,因为浮点数不能完全精确的表示出来,一般会损失精度。
2.java中float f = 3.4;是否正确?
不正确,3.4是双精度数,将双精度型(double)赋值给浮点型(float)属于向下转型会造成精度损失,因此需要强制类型转换float f = (float)3.4; 或者写成 float f = 3.4f;才可以。
3. JDK、JRE、JVM
JDK包含JRE,JRE包含JVM,有JRE即可运行程序。
总结的很好,一定要点开看!:
JDK(Java SE Development Kit),Java标准开发包,它提供了编译、运行Java程序所需的各种工具和资源,包括Java编译器、Java运行时环境,以及常用的Java类库等。
JRE( Java Runtime Environment) 、Java运行环境,用于解释执行Java的字节码文件。普通用户而只需要安装 JRE(Java Runtime Environment)来运行 Java 程序。而程序开发者必须安装JDK来编译、调试程序。
JVM(Java Virtual Mechinal),Java虚拟机,是JRE的一部分。它是整个java实现跨平台的最核心的部分,负责解释执行字节码文件,是可运行java字节码文件的虚拟计算机。所有平台的上的JVM向编译器提供相同的接口,而编译器只需要面向虚拟机,生成虚拟机能识别的代码,然后由虚拟机来解释执行。
4. 抽象类 、接口
抽象类:构造出一个固定的一组行为的抽象描述,但是这组行为却能够有任意个可能的具体实现方式。这个抽象描述就是抽象类。
接口:是为了把程序模块进行固化的契约,是为了降低耦合。、
抽象类和接口的区别:
- 抽象类可以有构造方法,接口没有构造方法
- 抽象类可以有普通成员变量,接口没有普通成员变量
- 抽象类可以有非抽象的普通方法,接口中的方法必须是抽象的
- 抽象类中的抽象方法访问类型可以是public,protected,接口中抽象方法必须是public类型的
- 抽象类可以包含静态方法,接口中不能包含静态方法
- 一个类可以实现多个接口,但是只能继承一个抽象类
- 接口中基本数据类型的数据成员,都默认为static final,抽象类则不是
链接: 细节及比较看这里.
5. 浅拷贝、深拷贝、引用拷贝
浅拷贝(Shallow Copy)
①对于数据类型是基本数据类型的成员变量,浅拷贝会直接进行值传递,也就是将该属性值复制一份给新的对象。因为是两份不同的数据,所以对其中一个对象的该成员变量值进行修改,不会影响另一个对象拷贝得到的数据。
②对于数据类型是引用数据类型的成员变量,比如说成员变量是某个数组、某个类的对象等,那么浅拷贝会进行引用传递,也就是只是将该成员变量的引用值(内存地址)复制一份给新的对象。因为实际上两个对象的该成员变量都指向同一个实例。在这种情况下,在一个对象中修改该成员变量会影响到另一个对象的该成员变量值。
浅拷贝实现方式
- 构造函数方法
- 用类实现对象拷贝,需要实现 Cloneable 接口,并覆写 clone() 方法。
Student类以Subject对象为成员
public class Subject {
private String name;
public Subject(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "[Subject: " + this.hashCode() + ",name:" + name + "]";
}
}
public class Student implements Cloneable {
//引用类型
private Subject subject;
//基础数据类型
private String name;
private int age;
public Subject getSubject() {
return subject;
}
public void setSubject(Subject subject) {
this.subject = subject;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
/**
* 重写clone()方法
* @return
*/
@Override
public Object clone() {
//浅拷贝
try {
// 直接调用父类的clone()方法
return super.clone();
} catch (CloneNotSupportedException e) {
return null;
}
}
@Override
public String toString() {
return "[Student: " + this.hashCode() + ",subject:" + subject + ",name:" + name + ",age:" + age + "]";
}
}
public class ShallowCopy {
public static void main(String[] args) {
Subject subject = new Subject("yuwen");
Student studentA = new Student();
studentA.setSubject(subject);
studentA.setName("Lynn");
studentA.setAge(20);
Student studentB = (Student) studentA.clone();
studentB.setName("Lily");
studentB.setAge(18);
Subject subjectB = studentB.getSubject();
subjectB.setName("lishi");
System.out.println("studentA:" + studentA.toString());
System.out.println("studentB:" + studentB.toString());
}
}
studentA:[Student: 460141958,subject:[Subject: 1163157884,name:lishi],name:Lynn,age:20]
studentB:[Student: 1956725890,subject:[Subject: 1163157884,name:lishi],name:Lily,age:18]
由输出的结果可见,通过 studentA.clone() 拷贝对象后得到的 studentB,和 studentA 是两个不同的对象。studentA 和 studentB 的基础数据类型的修改互不影响,而引用类型 subject 修改后是会有影响的。
- 引用拷贝
Student studentB = studentA;
studentA:[Student: 460141958,subject:[Subject: 1163157884,name:lishi],name:Lily,age:18]
studentB:[Student: 460141958,subject:[Subject: 1163157884,name:lishi],name:Lily,age:18]
A和B实际上都是内存空间中同一个对象的引用,并没有进行对象的拷贝
深拷贝
深拷贝,在拷贝引用类型成员变量时,为引用类型的数据成员另辟了一个独立的内存空间,实现真正内容上的拷贝。深拷贝把要复制的对象所引用的对象都复制了一遍。
对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个(和浅拷贝一样)
对于引用类型,比如数组或者类对象,深拷贝会新建一个对象空间,然后拷贝里面的内容,所以它们指向了不同的内存空间。改变其中一个,不会对另外一个也产生影响。
对于有多层对象的,每个对象都需要实现 Cloneable 并重写 clone() 方法,进而实现了对象的串行层层拷贝。
深拷贝相比于浅拷贝速度较慢并且花销较大。
Subject类要重写clone()方法
public class Subject implements Cloneable {
private String name;
public Subject(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
protected Object clone() throws CloneNotSupportedException {
//Subject 如果也有引用类型的成员属性,也应该和 Student 类一样实现
return super.clone();
}
@Override
public String toString() {
return "[Subject: " + this.hashCode() + ",name:" + name + "]";
}
}
public class Student implements Cloneable {
//引用类型
private Subject subject;
//基础数据类型
private String name;
private int age;
public Subject getSubject() {
return subject;
}
public void setSubject(Subject subject) {
this.subject = subject;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
/**
* 重写clone()方法
* @return
*/
@Override
public Object clone() {
//深拷贝
try {
// 直接调用父类的clone()方法
Student student = (Student) super.clone();
student.subject = (Subject) subject.clone();
return student;
} catch (CloneNotSupportedException e) {
return null;
}
}
@Override
public String toString() {
return "[Student: " + this.hashCode() + ",subject:" + subject + ",name:" + name + ",age:" + age + "]";
}
}
此时的输出与上面浅拷贝的输出就不一样了,此时引用变量的值的修改也不再受影响。
studentA:[Student: 460141958,subject:[Subject: 1163157884,name:yuwen],name:Lynn,age:20]
studentB:[Student: 1956725890,subject:[Subject: 356573597,name:lishi],name:Lily,age:18]
6 ==、equals、Hashcode
- ==
基本数据类型,byte, short, char, int, long, float, double, boolean ,应用双等号(==),比较的是值
引用类型(类、接口、数组)
当他们用(==)进行比较的时候,比较的是他们在内存中的存放地址,所以,除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。对象是放在堆中的,栈中存放的是对象的引用(地址)。
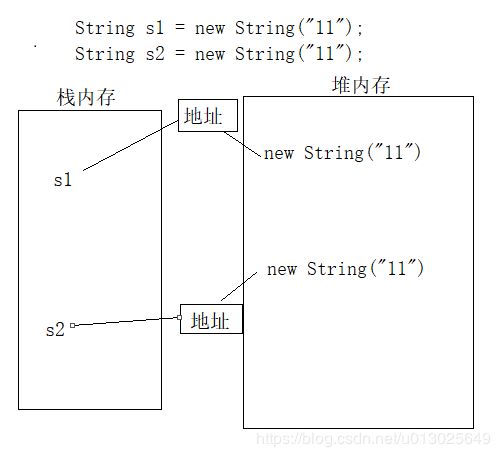
public class testDay {
public static void main(String[] args) {
String s1 = new String("11");
String s2 = new String("11");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}
结果是:false
true
- equals
equals()方法Object类的方法,是用来判断其他的对象是否和该对象相等。所以任何一个对象都有equals()方法。区别在于是否重写了该方法。
public boolean equals(Object obj) {
return (this == obj);
}
如上所示:equals比较的是对象的地址值。但是在String 、Math、Integer、Double等这些封装类在使用equals()方法时,已经覆盖了object类的equals()方法,让其比较的是值。看下String里面重写的equals():
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
重写了之后就是这是进行的内容比较,而已经不再是之前地址的比较。依次类推Math、Integer、Double等这些类都是重写了equals()方法的,从而进行的是内容的比较。需要注意的是当equals()方法被override时,hashCode()也要被override。按照一般hashCode()方法的实现来说,相等的对象,它们的hashcode一定相等。
- HashCode
哈希算法核心思想就是将集合分成若干个存储区域(可以看成一个个桶),每个对象可以计算出一个哈希码,可以根据哈希码分组,每组分别对应某个存储区域,这样一个对象根据它的哈希码就可以分到不同的存储区域(不同的区域。
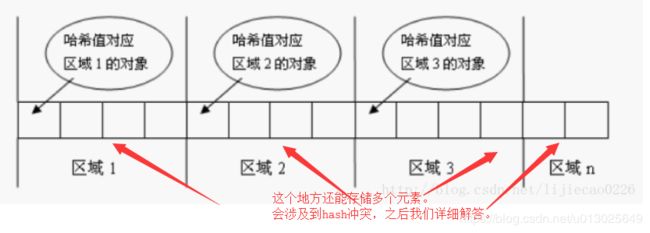
所以再比较元素的时候,实际上是先比较hashcode,如果相等了之后才去比较equal方法。
,先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等。再重写了equals最好把hashCode也重写。其实这是一条规范,如果不这样做程序也可以执行,只不过会隐藏bug。一般一个类的对象如果会存储在HashTable,HashSet,HashMap等散列存储结构中,那么重写equals后最好也重写hashCode。
原文链接:https://blog.csdn.net/u013025649/article/details/87918490
7 String、StringBuilder、StringBuffer
String 字符串常量(长度不可变)
StringBuilder 字符串变量(长度可变、非线程安全)
StringBuffer 字符串变量(长度可变、线程安全)

从上图中可以看到,初始 String str = “hello”;,然后在这个字符串后面加上新的字符串“world”,执行 str = str + “World”; 这个过程是需要重新在栈堆内存中开辟内存空间的,最终得到了“hello world”字符串也相应的需要开辟内存空间,这样短短的两个字符串,却需要开辟三次内存空间,不得不说这是对内存空间的极大浪费。为了应对经常性的字符串相关的操作,谷歌引入了两个新的类——StringBuilder类和StringBuffer类来对此种变化字符串进行处理。
和 String 类不同的是,StringBuilder 和 StringBuffer类的对象能够被多次的修改,并且不产生新的未使用对象。
StringBuilder sa = new StringBuilder("This is only a"); //创建StringBuilder对象
sa.append(" simple").append(" test"); //使用append()方法添加字符串
StringBuffer sb = new StringBuffer("123"); //创建StringBuffer对象
sb.append("456"); //使用append()方法添加字符串
三者在执行速度方面的比较:StringBuilder > StringBuffer > String
由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。
对于三者使用的总结:
如果要操作少量的数据用String
单线程操作字符串缓冲区下操作大量数据用StringBuilder(非线程安全)
多线程操作字符串缓冲区下操作大量数据用StringBuffer(线程安全)
这里缺少对于源码的解释,后面记得补上
8 Arrays
9 public、protected、缺省、private
- public修饰的成员变量和函数可以被类、子类、同一个包中的类以及任意其他类访问。
- protected修饰的成员变量和函数能被类本身、子类及同一个包中的类访问。
- 缺省情况(不写)下,属于一种包访问,即能被类本身以及同一个包中的类访问。
- private修饰的成员变量和函数只能在类本身和内部类中被访问。

10 参数传递(值传递,引用传递,String)
对于基本数据类型:传递的是值本身,方法里面修改了值,原值不变
//第一个例子:基本类型
void foo(int value) {
value = 100;
}
foo(num); // num 没有被改变
对于引用类型的数据而言:传的是所指向对象在内存中的地址值,所以方法中修改了参数,原来对象也会改变。
但要注意: 要这个对象本身是可以修改的才可以, 若是不可以修改的,此时原对象也不会变。
//提供了改变自身方法的引用类型
StringBuilder sb = new StringBuilder("iphone");
void foo(StringBuilder builder) {
builder.append("4");
}
foo(sb); // sb 被改变了,变成了"iphone4"。
//没有提供改变自身方法的引用类型
void foo(String text) {
text = "windows";
}
foo(str); // str 也没有被改变
此时若要修改 str,会
提供了改变自身方法的引用类型,但是不使用,而是使用赋值运算符。
StringBuilder sb = new StringBuilder("iphone");
void foo(StringBuilder builder) {
builder = new StringBuilder("ipad");
}
foo(sb); // sb 没有被改变,还是 "iphone"。
11 封装 继承 多态
继承:
继承是指:保持已有类的特性而构造新类的过程。继承后,子类能够利用父类中定义的变量和方法,就像它们属于子类本身一样。
单继承:java类是单继承的,一个类只允许有一个父类。
多继承:java接口多继承的,一个类允许继承多个接口。
多态
是指:在父类中定义的属性和方法被子类继承之后,可以具有不同的数据类型或表现出不同的行为,这使得同一个属性或方法在父类及其各个子类中具有不同的含义。
- 封装 隐藏内部代码继承
- 继承 复用现有代码
- 多态 改写对象行为
多态的底层实现原理???(等待解决的问题)
12 重写&重载
重写:
在方法前加上@Override注解。其实就是在子类中把父类本身有的方法重新写一遍。子类继承了父类原有的方法,但有时子类并不想原封不动的继承父类中的某个方法,所以在方法名,参数列表,返回类型(除过子类中方法的返回值是父类中方法返回值的子类时)都相同的情况下, 对方法体进行修改或重写,这就是重写。但要注意子类函数的访问修饰权限不能少于父类的。
重载:
在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同甚至是参数顺序不同)则视为重载。同时,重载对返回类型没有要求,可以相同也可以不同,但不能通过返回类型是否相同来判断重载。
方法的重载和重写都是实现多态的方式,但区别在于:
重载实现的是编译时的多态性;而重写实现的是运行时的多态性。
重载发生在一个类中;重写发生在子类与父类之间。
https://blog.csdn.net/yy2017220302028/article/details/104631329
13 Static
被static关键字修饰的不需要创建对象去调用,直接根据类名就可以去访问。
static关键字修饰类:
java里面static一般用来修饰成员变量或函数。但有一种特殊用法是用static修饰内部类,普通类是不允许声明为静态的,只有内部类才可以。(比如leetcode中定义复杂变量时)
static关键字修饰方法:
修饰方法的时候,可以直接通过类名来进行调用
static关键字修饰变量:
被static修饰的成员变量叫做静态变量,也叫做类变量,说明这个变量是属于这个类的,而不是属于是对象,没有被static修饰的成员变量叫做实例变量,说明这个变量是属于某个具体的对象的。
static关键字修饰代码块
静态代码块在类第一次被载入时执行。类初始化的顺序。
父类静态变量 父类静态代码块
子类静态变量 子类静态代码块
父类普通变量 父类普通代码块
父类构造函数
子类普通变量 子类普通代码块
子类构造函数
static关键字进行一个小结:
(1). 静态的特点:
- 随着类的加载而加载。
也就是说,静态会随着类的消失而消失,说明静态的生命周期最长 - 优先于对象的存在。
明确一点:静态是先存在的,对象是后存在的 - 被所有对象共享。
可以直接被类名多调用。
(2)类变量和实例变量的区别:
- 存放位置
类变量随着类的加载存在于方法区中;实例变量随着对象的对象的建立存在于堆内存里 - 生命周期
类变量生命周期最长,随着“类”的加载而加载,随着类的消失而消失;实例变量随着“对象”的消失而消失
(3)注意事项:
-
静态方法只能访问静态成员。(非静态既可以访问静态,又可以访问非静态)
-
静态方法中不可以使用this或者super关键字。
原因:在一个类的方法中使用this,可以调用方法所在对象自身的变量或方法。而static修饰的方法,在程序编译时就已被加载到内存中,而不是创建实例的时候才产生。它是属于类,而不属于某个对象。那么你在static方法中使用this,无法判断出这个this指的是谁。总的来说,this、super 要依赖于实例,而static在方法区中,无法判断是哪个实例。
但是访问一个类的静态成员,还是可以使用this的,只是在静态方法中,不可以使用this。因为堆中存放的实例对象中,保存了静态成员的地址(引用)。3、主函数(main)是静态的。
(4) 静态的利与弊:
利:对对象的共享数据进行单独空间的存储,节省空间,没有必要没一个对象中都存储一份,可以直接被类名所调用。
弊:生命周期过长,访问出现局限性(只能访问静态)。
参考链接:https://baijiahao.baidu.com/sid=1636927461989417537&wfr=spider&for=pc
使用实例:
https://blog.csdn.net/kuangay/article/details/81485324
14 final
- final修饰类:
被final修饰的类,是不可以被继承的,这样做的目的可以保证该类不被修改,Java的一些核心的API都是final类,例如String、Integer、Math等。 - final修饰方法:
子类不可以重写父类中被final修饰的方法 - final修饰实例变量:(类的属性,定义在类内,但是在类内的方法之外)
final修饰实例变量时必须初始化,且不可再修改。 - final修饰局部变量:(方法体内的变量)
final修饰局部变量时只能初始化(赋值)一次,但也可以不初始化。 - final修饰方法参数:
final修饰方法参数时,是在调用方法传递参数时候初始化的。
15 try…catch…finally
ipad异常笔记部分,执行顺序相关
反射
ipad
异常
ipad
Java创建对象的方式
- 使用new关键字
- 使用反射机制
1)使用Class类的newInstance()方法:
2)java.lang.reflect.Constructor类里也有一个newInstance()方法(需要import这个包)
//方式一:
ObjectName obj = ObjectName.class.newInstance();
//方式二:
Class classA = Class.forName("ClassName");
ObjectName obj = (ObjectName) classA.newInstance();
bjectName obj = ObjectName.class.getConstructor.newInstance();
- 使用clone方法
类必须先实现Cloneable接口并重写其clone()方法,才可使用该方法。
ObjectName obj = obj.clone();
- 使用反序列化
使用反序列化ObjectInputStream的readObject()方法:类必须实现Serializable接口
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(FILE_NAME))) {
ObjectName obj = ois.readObject();
}
集合
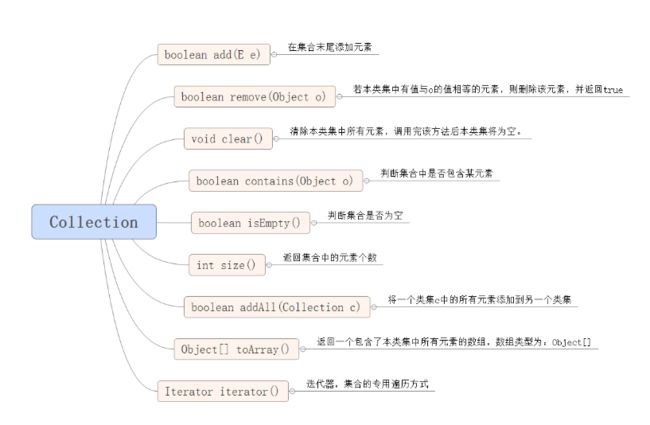
Collection
这一部分结构(原理)是重点,不要看一遍就过了,要记住~
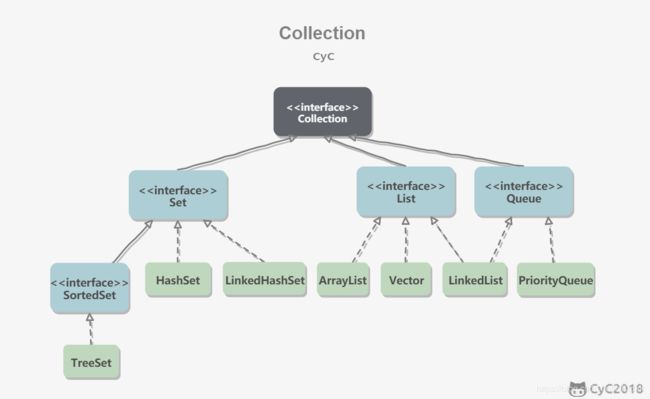

Collection API
Arrays.asList();数组转list
List
List是一个继承于Collection的接口,即List是集合中的一种。List是有序的队列,List中的每一个元素都有一个索引;第一个元素的索引值是0,往后的元素的索引值依次+1。和Set不同,List中允许有重复的元素。
List接口的实现类
(1)ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
(2)LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
(3)Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
List接口的方法:既然List是继承于Collection接口,它自然就包含了Collection中的全部函数接口;由于List是有序队列,它也额外的有自己的API接口。

ArrayList
因为 ArrayList 是基于数组实现的,所以支持快速随机访问。RandomAccess 接口标识着该类支持快速随机访问。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
数组的默认大小为 10。
private static final int DEFAULT_CAPACITY = 10;
扩容操作
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。
扩容操作需要调用 Arrays.copyOf() 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 这里有一个调用了ensureCapacityInternal()方法,翻译一下:确保容量内部
private void ensureCapacityInternal(int minCapacity) {
//elementData是一个全局变量,用来表示ArrayList当前正在使用的数组.
//当前正在使用的数组是否是空数组,如果是空数组的话,最小容量就是DEFAULT_CAPACITY(10)和size+1的更大者。
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
// modCount是什么? ArrayList 发生结构变化的次数
//ArrayList的结构变化增加了一次
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//一定会执行
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//新的容量是旧的容量的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
// 新容量小于最小容量的话,就把最小容量赋值给新容量
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
//新容量大于数组最大容量,就把整数的最大值赋值给新容量
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
//数组实际扩张的办法,通过Arrays的静态方法copyOf
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
删除操作
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
Vector
它的实现与 ArrayList 类似,但是方法使用了 synchronized 进行同步。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
Vector 的构造函数可以传入 capacityIncrement 参数,它的作用是在扩容时使容量 capacity 增长 capacityIncrement。如果这个参数的值小于等于 0,扩容时每次都令 capacity 为原来的两倍。
与 ArrayList 的比较
- Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
- Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
替代方案
可以使用 Collections.synchronizedList(); 得到一个线程安全的 ArrayList。
List list = new ArrayList<>();
List synList = Collections.synchronizedList(list);
也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
List list = new CopyOnWriteArrayList<>();
- CopyOnWriteArrayList
- 读写分离
写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。
写操作需要加锁,防止并发写入时导致写入数据丢失。
写操作结束之后需要把原始数组指向新的复制数组。
LinkedList
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable{}
LinkList比ArrayList多实现了一个接口Deque
public interface Deque<E> extends Queue<E> {}
通过注释我们可以发现这个接口是一个线性双端队列,它支持容量限制的双端队列。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
add() 方法
public boolean add(E e) {
//直接插入默认插入到尾部
linkLast(e);
return true;
}
public void add(int index, E element) {
//检查这个索引是否超出链表的边界
checkPositionIndex(index);
if (index == size)
//链表为空的时候或者想要插入到尾部的时候直接插入到尾部
linkLast(element);
else
linkBefore(element, node(index));
}
LinkList的add()有两个重载方法。
直接插入话,默认是插入到尾部的。
如果过通过索引插入的话,执行linkBefore()方法,插入之前的查找工作,传入了需要插入的元素和node()这个方法的返回值
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
如果请求插入的索引小于size的一半则从头开始遍历,反之则从尾部开始遍历。返回的也是一个节点.
/**
* Inserts element e before non-null Node succ.//把我们要插入的元素插入到suuc这个节点之前
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
与ArrayList的比较
ArrayList 基于动态数组实现,LinkedList 基于双向链表实现。ArrayList 和 LinkedList 的区别可以归结为数组和链表的区别:
- 数组支持随机访问,但插入删除的代价很高,需要移动大量元素;
- 链表不支持随机访问,但插入删除只需要改变指针。
Set
Set是没有重复元素的集合。
public interface Set extends Collection {}
Set的API和Collection完全一样。
HashSet
HashSet : 底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写**hashCode()和equals()**方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
-
a、实现唯一性:
存储元素首先会使用hash()算法函数生成一个int类型hashCode散列值,然后已经的所存储的元素的hashCode值比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象;如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值处类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,这样就保证了元素的唯一性。 -
b、实现不重复
HashSet也一样他是使用了一种标识来确定元素的不重复,HashSet用一种算法来保证HashSet中的元素是不重复的, HashSet采用哈希算法,底层用数组存储数据。默认初始化容量16,加载因子0.75。
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置。如果有两个元素通过equals方法比较true,但它们的hashCode方法返回的值不相等,HashSet将会把它们存储在不同位置,依然可以添加成功。
也就是说。HashSet集合判断两个元素的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode方法返回值也相等。
靠元素重写hashCode方法和equals方法来判断两个元素是否相等,如果相等则覆盖原来的元素,依此来确保元素的唯一性
HashSet 的实现比较简单,相关HashSet的操作,基本上都是直接调用底层HashMap的相关方法来完成,我们应该为保存到HashSet中的对象覆盖hashCode()和equals()
LinkedHashSet
HashSet还有一个子类LinkedList、LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的,也就是说当遍历集合LinkedHashSet集合里的元素时,集合将会按元素的添加顺序来访问集合里的元素。
输出集合里的元素时,元素顺序总是与添加顺序一致。但是LinkedHashSet依然是HashSet,因此它不允许集合重复。
底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
TreeSet
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;
TreeSet详解,源码啥的;
与HashSet集合相比,TreeSet还提供了几个额外方法:
- Comparator comparator():如果TreeSet采用了定制顺序,则该方法返回定制排序所使用的Comparator,如果TreeSet采用自然排序,则返回null;
- Object first():返回集合中的第一个元素;
- Object last():返回集合中的最后一个元素;
- Object lower(Object e):返回指定元素之前的元素。
- Object higher(Object e):返回指定元素之后的元素。
- SortedSet subSet(Object fromElement,Object toElement):返回此Set的子集合,含头不含尾;
- SortedSet headSet(Object toElement):返回此Set的子集,由小于toElement的元素组成;
- SortedSet tailSet(Object fromElement):返回此Set的子集,由大于fromElement的元素组成;
比较:
1、TreeSet 是二叉树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值;
2、HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束 ;
3、HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例;
适用场景分析:HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
Collection 和 Collections
Collection:
是集合类的上层接口。本身是一个Interface,里面包含了一些集合的基本操作。
Collection接口是Set接口和List接口的父接口
Collections
Collections是一个集合框架的帮助类,里面包含一些对集合的排序,搜索以及序列化的操作。
最根本的是Collections是一个类
Collections类的常用API
集合类型的默认容量以及扩容机制:
ArrayList
默认容量是10
最大容量Integer.MAX_VALUE - 8(Integer.MAX_VALUE = 231-1 )
ArrayList扩容机制,按原数组长度的1.5倍扩容。如果扩容后的大小小于实际需要的大小,将数组扩大到实际需要的大小。
Vector
是线程安全版的ArrayList,内部实现都是用数组实现的。Vector通过在方法前用synchronized修饰实现了线程同步功能。
默认容量是10
最大容量Integer.MAX_VALUE - 8
Vector扩容机制,如果用户没有指定扩容步长,按原数组长度的2倍扩容,否则按用户指定的扩容步长扩容。如果扩容后的大小小于实际需要的大小,将数组扩大到实际需要的大小。
Stack
继承自Vector。添加了同步的push(E e)、pop()、peek()方法,默认容量和扩容机制同Vector。
DelayQueue、PriorityQueue
非线程安全的无界队列。
HashMap
是基于数组和链表实现的。HashMap的容量必须是2的幂次方
默认容量是16
最大容量2的30次方
HashMap扩容机制,扩容到原数组的2倍
Hashtable
默认容量是11
最大容量Integer.MAX_VALUE - 8
Hashtable扩容机制,扩容到原数组的2倍+1
https://blog.csdn.net/yy2017220302028/article/details/104394877
Map
这一部分记得整合iPad上面的东西
1.7以及1.8的对比
HashMap
HashMap是基于拉链法实现的一个散列表,内部由数组和链表实现。
-
数组的初始容量为16,而容量是以2的次方扩充的,一是为了提高性能使用足够大的数组,二是为了能使用位运算代替取模预算。
-
数组是否需要扩充是通过负载因子判断的,如果当前元素个数为数组容量的0.75时,就会扩充数组。这个0.75就是默认的负载因子,可由构造传入。我们也可以设置大于1的负载因子,这样数组就不会扩充,牺牲性能,节省内存。
-
为了解决碰撞,数组中的元素是单向链表类型。当链表长度到达一个阈值时(7或8),会将链表转换成红黑树提高性能。而当链表长度缩小到另一个阈值时(6),又会将红黑树转换回单向链表提高性能,这里是一个平衡点。
-
对于第三点补充说明,检查链表长度转换成红黑树之前,还会先检测当前数组数组是否到达一个阈值(64),如果没有到达这个容量,会放弃转换,先去扩充数组。所以上面也说了链表长度的阈值是7或8,因为会有一次放弃转换的操作。
直接看这个就行了,里面hashcode计算的详解
HashTable
ipad
ConcurrentHashMap
ipad
Hash怎么重定向的?
并发
同步和异步
同步
发送一个请求,等待返回,然后再发送下一个请求。实现:1. synchronized修饰;2. wait()和notify()。同步可以避免出现死锁,读脏数据的发生,一般共享某一资源的时候用,如果每个人都有修改权限,同时修改一个文件,有可能使一个人读取另一个人已经删除的内容,就会出错,同步就会按顺序来修改。
public void countAdd() { //比如一个计算数字和的方法,可能就需要是同步的,否则会读到脏数据或者死锁等问题。
synchronized(this) { //使用synchronized修饰,表明它是一个同步的方法。
... //方法体
}
}
或者写成:
public synchronized void countAdd() {
... //方法体
}
异步:
发送一个请求,不等待返回,随时可以再发送下一个请求。
同步和异步最大的区别就在于:一个需要等待,一个不需要等待。比如广播,就是一个异步例子。发起者不关心接收者的状态,不需要等待接收者的返回信息。电话,就是一个同步例子。发起者需要等待接收者,接通电话后,通信才开始,需要等待接收者的返回信息。
多线程的实现方式
Java 中创建线程有四种方式:① 继承 Thread;② 实现 Runnable 接口;③ 线程池;④ 实现 Callable 接口。
- 继承Thread类。
Thread类本质上是实现了Runnable接口的一个实例,代表一个线程的实例。让自己的类直接extends Thread,并在此类中复写run()方法。启动线程的方法就是通过Thread类的start()实例方法,start()方法将启动一个新线程,并执行其中的run()方法。
public class MyThread extends Thread {
public void run() {
// ...
}
}
public static void main(String[] args) {
MyThread mt = new MyThread();
mt.start();
}
- 实现Runnable接口。
如果自己的类已经extends另一个类了,就无法再直接extends Thread,此时,可以通过让它来实现Runnable接口来创建多线程。
public class MyThread extends OtherClass implements Runnable { //实现Runnable接口
public void run() { //复写run()方法
System.out.println("MyThread.run()");
}
}
MyThread myThread = new MyThread(); //创建一个myThread实例
Thread thread = new Thread(myThread); //将自己的myThread传入Thread实例中
thread.start(); //启动线程
- 实现Callable接口,重写call函数。
继承Thread类实现多线程,但重写run()方法时没有返回值也不能抛出异常,使用Callable接口就可以解决这个问题。
public class MyCallable implements Callable<Integer> {
public Integer call() {
return 123;
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
MyCallable mc = new MyCallable();
FutureTask<Integer> ft = new FutureTask<>(mc);
Thread thread = new Thread(ft);
thread.start();
System.out.println(ft.get());
}
- 线程池
Thread和Runable的区别:
- Runnable的实现方式是实现其接口, Thread的实现方式是继承其类
- Runnable接口支持多继承,但基本上用不到
- Thread实现了Runnable接口并进行了扩展,而Thread和Runnable的实质是实现的关系,不是同类东西,所以Runnable或Thread本身没有可比性。
详解
Callable接口和Runnable接口的不同之处:
- Callable规定的方法是call(),而Runnable是run();
- call()方法可以抛出异常,但是run()方法不行;
- Callable对象执行后可以有返回值,运行Callable任务可以得到一个Future对象,通过Future对象可以了解任务执行情况,可以取消任务的执行,而Runnable不可有返回值。
Callable、Future和FutureTask
start() 和 run()的区别
- 调用start() 方法会创建一个新的子线程并启动;
通过调用Thread类的 start()方法来启动一个线程,这时此线程处于就绪(可运行)状态,并没有运行,一旦得到cpu时间片,就开始执行run()方法,这里的run()方法 称为线程体,它包含了要执行的这个线程的内容,Run方法运行结束,此线程随即终止。 - run() 方法只是Thread的一个普通方法调用,还是在主线程里执行;
run()方法只是类的一个普通方法而已,如果直接调用Run方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码,这样就没有达到写线程的目的。
start() 方法的细节 : iPad上更详细;
start()方法会调用JVM_Thread方法,本质上是调用了native修饰的start0方法。
如何给run()传参
ipad
如何处理线程返回值
ipad
sleep和wait的区别
ipad
notify, notifyAll, yeild
ipad
如何中断线程
ipad
互斥同步
Synchronized
JVM 实现的 synchronized;
对象锁
- 同步代码块(synchronized(this), synchronized(类实例对象)),锁是小括号()中的实例对象;
只作用于同一个对象,如果调用两个对象上的同步代码块,就不会进行同步。
对于以下代码,使用 ExecutorService 执行了两个线程,由于调用的是同一个对象的同步代码块,因此这两个线程会进行同步,当一个线程进入同步语句块时,另一个线程就必须等待。
public class SynchronizedExample {
public void func1() {
synchronized (this) {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
}
}
}
public static void main(String[] args) {
SynchronizedExample e1 = new SynchronizedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> e1.func1());
executorService.execute(() -> e1.func1());
}
//输出:0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
对于以下代码,两个线程调用了不同对象的同步代码块,因此这两个线程就不需要同步。从输出结果可以看出,两个线程交叉执行。
public static void main(String[] args) {
SynchronizedExample e1 = new SynchronizedExample();
SynchronizedExample e2 = new SynchronizedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> e1.func1());
executorService.execute(() -> e2.func1());
}
//交叉执行:0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9
- 同步非静态方法(synchronized method),锁是当前对象的实例对象;
它和同步代码块一样,作用于同一个对象。
public synchronized void func () {
// ...
}
获取类锁
- 同步一个类;作用于整个类,也就是说两个线程调用同一个类的不同对象上的这种同步语句,也会进行同步。
public void func() {
synchronized (SynchronizedExample.class) {
// ...
}
}
public class SynchronizedExample {
public void func2() {
synchronized (SynchronizedExample.class) {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
}
}
}
public static void main(String[] args) {
SynchronizedExample e1 = new SynchronizedExample();
SynchronizedExample e2 = new SynchronizedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> e1.func2());
executorService.execute(() -> e2.func2());
}
//虽然是两个对象,但因为锁住的是类,所以还是同步的
//0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
- 同步静态方法;
作用于整个类。
public synchronized static void fun() {
// ...
}
synchronized底层实现原理: ipad
ReentrantLock
JDK 实现的 ReentrantLock;
ReentrantLock 是 java.util.concurrent(J.U.C)包中的锁,基于AQS实现。
public class LockExample {
private Lock lock = new ReentrantLock();
public void func() {
lock.lock();
try {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
} finally {
lock.unlock(); // 确保释放锁,从而避免发生死锁。
}
}
}
public static void main(String[] args) {
LockExample lockExample = new LockExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> lockExample.func());
executorService.execute(() -> lockExample.func());
}
//0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
区别:


详细比较:Here
CAS
ipad 悲观锁和乐观锁部分
Volatile
volatile是Java提供的一种轻量级的同步机制。Java 语言包含两种内在的同步机制:同步块(或方法)和 volatile 变量,相比于synchronized(synchronized通常称为重量级锁),volatile更轻量级,因为它不会引起线程上下文的切换和调度。但是volatile 变量的同步性较差(有时它更简单并且开销更低),而且其使用也更容易出错。
Volatile
线程池
线程池的作用:
- 复用线程、控制最大并发数。
- 实现定时、周期等与时间相关的功能。
- 实现任务队列缓存策略和拒绝机制。
- 隔离线程环境。如:文件上传服务和数据查询服务在同一台服务器上,由于文件上传服务耗时严重,如果文件上传和数据查询服务使用同一个线程池,那么文件上传服务会影响到数据查询服务。可以通过配置独立线程池来实现文件上传和数据查询服务隔离,避免两者相互影响。
线程池接口

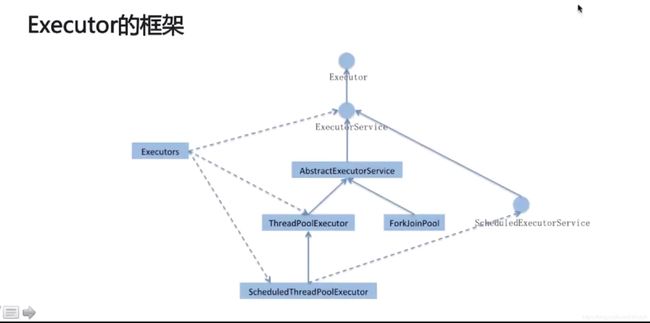
ExecutorService接口继承了Executor接口,定义了管理线程任务的方法。ExecutorService的抽象类AbstractExecutorService提供了submit、invokeAll()等部分方法实现,但是核心方法Executor.execute()并没有实现。因为所有任务都在这个方法里执行,不同的线程池实现策略会有不同,所以交由具体的线程池来实现。
JDK中提供了创建线程池的类,大家首先想到的一定是Executors类,没错,可以通过Executors类来创建线程池,但是不推荐(原因后面会分析)。Executors类只是个静态工厂,提供创建线程池的几个静态方法(内部屏蔽了线程池参数配置细节),而真正的线程池类是ThreadPoolExecutor。ThreadPoolExecutor构造方法如下:

参数意义:
- corePoolSize:核心线程数。如果等于0,则任务执行完后,没有任务请求进入时销毁线程池中的线程。如果大于0,即使本地任务执行完毕,核心线程也不会被销毁。设置过大会浪费系统资源,设置过小导致线程频繁创建。
- maximumPoolSize:最大线程数。必须大于等于1,且大于等于corePoolSize。如果与corePoolSize相等,则线程池大小固定。如果大于corePoolSize,则最多创建maximumPoolSize个线程执行任务,其他任务加入到workQueue缓存队列中,当workQueue为空且执行任务数小于maximumPoolSize时,线程空闲时间超过keepAliveTime会被回收。
- keepAliveTime:线程空闲时间。线程池中线程空闲时间达到keepAliveTime值时,线程会被销毁,只到剩下corePoolSize个线程为止。默认情况下,线程池的最大线程数大于corePoolSize时,keepAliveTime才会起作用。如果allowCoreThreadTimeOut被设置为true,即使线程池的最大线程数等于corePoolSize,keepAliveTime也会起作用(回收超时的核心线程)。
- unit:TimeUnit表示时间单位。
- workQueue:缓存队列。当请求线程数大于maximumPoolSize时,线程进入BlockingQueue阻塞队列。
- threadFactory:线程工厂。用来生产一组相同任务的线程。主要用于设置生成的线程名词前缀、是否为守护线程以及优先级等。设置有意义的名称前缀有利于在进行虚拟机分析时,知道线程是由哪个线程工厂创建的。
- handler:执行拒绝策略对象。当达到任务缓存上限时(即超过workQueue参数能存储的任务数),执行拒接策略,可以看作简单的限流保护。
Executors核心方法
- Executors.newFixedThreadPool:创建固定线程数的线程池。核心线程数等于最大线程数,不存在空闲线程,keepAliveTime为0。

- Executors.newSingleThreadExecutor:创建单线程的线程池,核心线程数和最大线程数都为1,相当于串行执行。

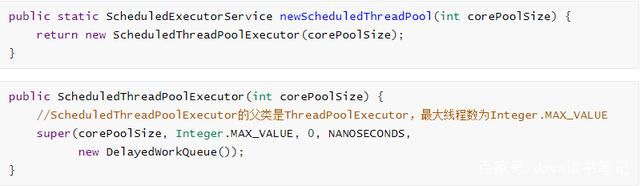
- Executors.newScheduledThreadPool:创建支持定时以及周期性任务执行的线程池。最大线程数是Integer.MAX_VALUE。存在OOM风险。keepAliveTime为0,所以不回收工作线程。
- Executors.newCachedThreadPool:核心线程数为0,最大线程数为Integer.MAX_VALUE,是一个高度可伸缩的线程池。存在OOM风险。keepAliveTime为60,工作线程处于空闲状态超过keepAliveTime会回收线程。

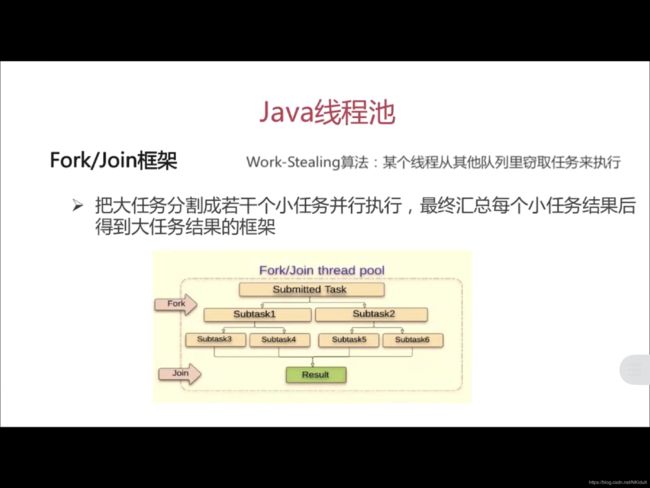
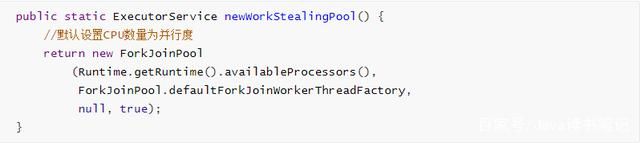
- Executors.newWorkStealingPool:JDK8引入,创建持有足够线程的线程池支持给定的并行度,并通过使用多个队列减少竞争。
禁止直接使用Executors创建线程池原因:
Executors.newCachedThreadPool和Executors.newScheduledThreadPool两个方法最大线程数为Integer.MAX_VALUE,如果达到上限,没有任务服务器可以继续工作,肯定会抛出OOM异常。
Executors.newSingleThreadExecutor和Executors.newFixedThreadPool两个方法的workQueue参数为new LinkedBlockingQueue(),容量为Integer.MAX_VALUE,如果瞬间请求非常大,会有OOM风险。

总结:以上5个核心方法除Executors.newWorkStealingPool方法之外,其他方法都有OOM风险。
线程池执行过程: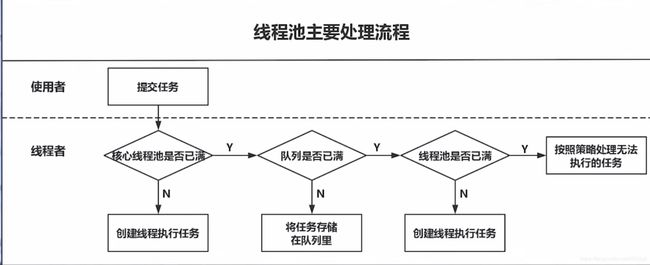
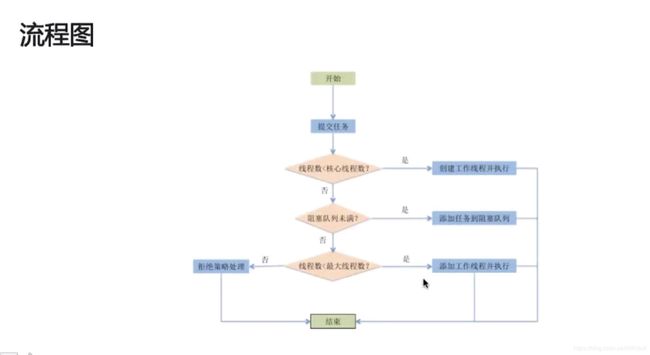

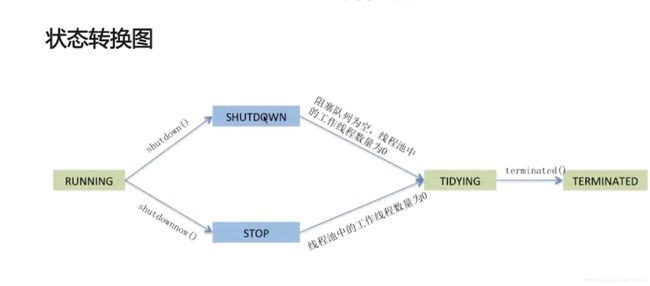
线程池状态:

线程池详解
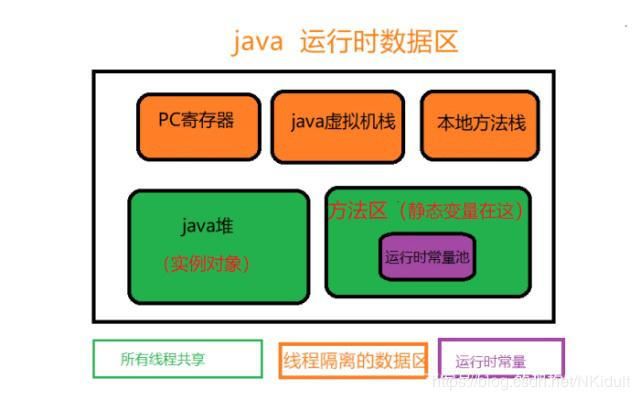
JVM
-
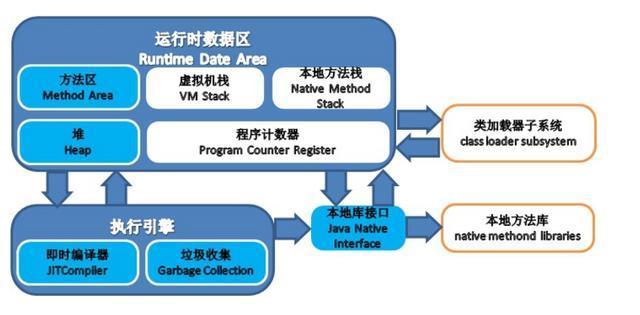
JVM体系结构:
类装载器ClassLoader:用来装载.class文件执行引擎:执行字节码,或者执行本地方法
运行时数据区:方法区、堆、Java栈、程序计数器、本地方法栈
JVM结构图:
JVM把描述类数据的字节码.Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的java类型,这就是虚拟机的类加载机制。 -
JVM原理
JVM是java的核心和基础,在java编译器和os平台之间的虚拟处理器。它是一种利用软件方法实现的抽象的计算机基于下层的操作系统和硬件平台,可以在上面执行java的字节码程序。java编译器只要面向JVM,生成JVM能理解的代码或字节码文件。Java源文件经编译成字节码程序,通过JVM将每一条指令翻译成不同平台机器码,通过特定平台运行。 -
jvm内部执行运行流程图
加载.class文件
管理并分配内存
执行垃圾收集
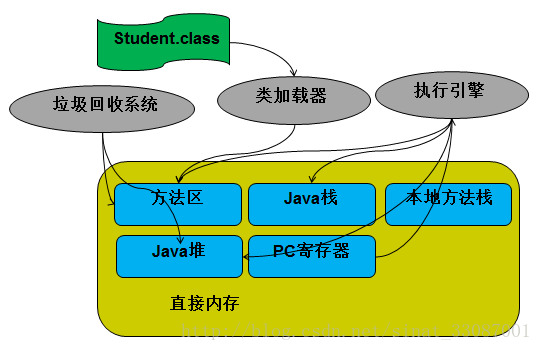
操作系统装入JVM是通过jdk中Java.exe来完成,
通过下面4步来完成JVM环境:
- 创建JVM装载环境和配置
- 装载JVM.dll
- 初始化JVM.dll并挂界到JNIENV(JNI调用接口)实例
- 调用JNIEnv实例装载并处理class类。
- JVM的生命周期
- JVM实例对应了一个独立运行的java程序它是进程级别
a) 启动。启动一个Java程序时,一个JVM实例就产生了,任何一个拥有public static void
main(String[] args)函数的class都可以作为JVM实例运行的起点
b) 运行。main()作为该程序初始线程的起点,任何其他线程均由该线程启动。JVM内部有两种线程:守护线程和非守护线程,main()属于非守护线程,守护线程通常由JVM自己使用,java程序也可以表明自己创建的线程是守护线程 。
c) 消亡。当程序中的所有非守护线程都终止时,JVM才退出;若安全管理器允许,程序也可以使用Runtime类或者System.exit()来退出 。 - JVM执行引擎实例则对应了属于用户运行程序的线程它是线程级别的。
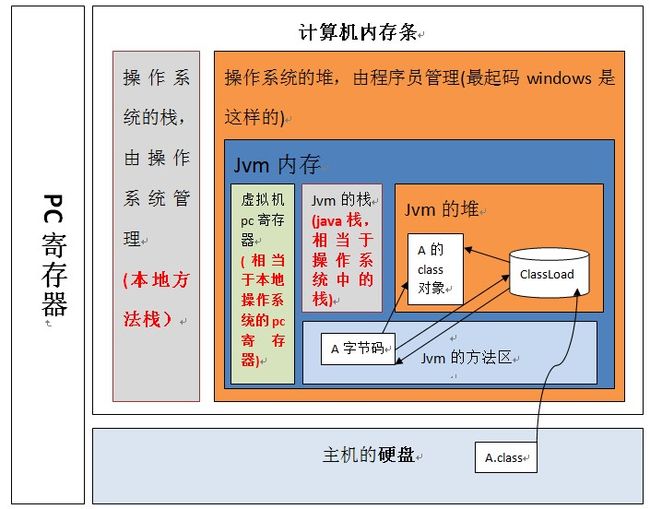
上图表明:jvm虚拟机位于操作系统的堆中,并且,程序员写好的类加载到虚拟机执行的过程是:当一个classLoder启动的时候,classLoader的生存地点在jvm中的堆,然后它会去主机硬盘上将A.class装载到jvm的方法区,方法区中的这个字节文件会被虚拟机拿来new A字节码(),然后A字节码这个内存文件有两个引用一个指向A的class对象,一个指向加载自己的classLoader.
JVM把描述类数据的字节码.Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的java类型,这就是虚拟机的类加载机制。
类加载:
类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个 java.lang.Class对象,用来封装类在方法区内的数据结构。类的加载的最终产品是位于堆区中的 Class对象, Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口。
类的生命周期
或者说是类的加载过程
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的生命周期包括了:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)、卸载(Unloading)七个阶段,其中验证、准备、解析三个部分统称链接。
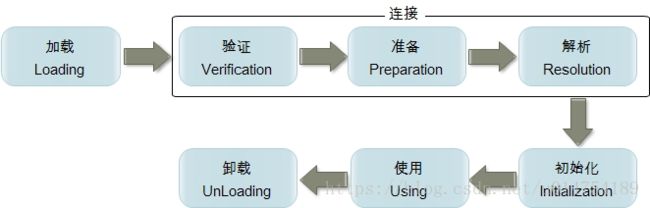
1. 加载
加载阶段是“类加载机制”中的一个阶段,这个阶段通常也被称作“装载”。加载阶段主要完成三件事情:
(1) 通过一个类的全限定名来获取其定义的二进制字节流。
(2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
(3)在Java堆中生成一个代表这个类的 java.lang.Class对象,作为对方法区中这些数据的访问入口。
相对于类加载的其他阶段而言,加载阶段(准确地说,是加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,因为开发人员既可以使用系统提供的类加载器来完成加载,也可以自定义自己的类加载器来完成加载。
加载阶段完成后,虚拟机外部的二进制字节流就按照虚拟机所需的格式存储在方法区之中,而且在Java堆中也创建一个 java.lang.Class类的对象,这样便可以通过该对象访问方法区中的这些数据。
2. 连接–验证
验证是链接阶段的第一步,这一步主要的目的是确保class文件的字节流中包含的信息符合当前虚拟机的要求,确保被加载的类的正确性,并且不会危害虚拟机自身安全。
验证阶段主要包括四个检验过程:文件格式验证、元数据验证、字节码验证和符号引用验证。
3. 连接–准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中进行分配。这个阶段中有两个容易产生混淆的知识点:
首先是这时候进行内存分配的仅包括类变量(static 修饰的变量),而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在java堆中。其次是这里所说的初始值“通常情况”下是数据类型的零值。
假设一个类变量定义为:
public static int value = 12;
那么变量value在准备阶段过后的初始值为0而不是12,因为这时候尚未开始执行任何java方法,而把value赋值为123的putstatic指令是程序被编译后,存放于类构造器()方法之中,所以把value赋值为12的动作将在初始化阶段才会被执行。
上面所说的“通常情况”下初始值是零值,那相对于一些特殊的情况,如果类字段的字段属性表中存在ConstantValue属性,那在准备阶段变量value就会被初始化为ConstantValue属性所指定的值,
假设上面类变量value定义为:
public static final int value = 123;
编译时javac将会为value生成ConstantValue属性,在准备阶段虚拟机就会根据ConstantValue的设置将value设置为123。
4. 连接–解析
把类中的符号引用转换为直接引用
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程,解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行。符号引用就是一组符号来描述目标,可以是任何字面量。
直接引用就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。
5. 初始化
类加载最后阶段,若该类具有超类,则对其进行初始化,执行静态初始化器和静态初始化成员变量(如前面只初始化了默认值的static变量将会在这个阶段赋值,成员变量也将被初始化)。
在Java中对类变量进行初始值设定有两种方式:
①声明类变量是指定初始值
②使用静态代码块为类变量指定初始值
JVM初始化步骤
1、假如这个类还没有被加载和连接,则程序先加载并连接该类
2、假如该类的直接父类还没有被初始化,则先初始化其直接父类
3、假如类中有初始化语句,则系统依次执行这些初始化语句
类初始化时机:
何时初始化
只有当对类的主动使用的时候才会导致类的初始化,类的主动使用包括以下六种:
- 为一个类型创建一个新的对象实例时(比如new、反射、序列化)
- 调用一个类型的静态方法时(即在字节码中执行invokestatic指令)
- 调用一个类型或接口的静态字段,或者对这些静态字段执行赋值操作时(即在字节码中,执行getstatic或者putstatic指令),不过用final修饰的静态字段除外,它被初始化为一个编译时常量表达式
- 调用JavaAPI中的反射方法时(比如调用java.lang.Class中的方法,或者java.lang.reflect包中其他类的方法)
- 初始化一个类的派生类时(Java虚拟机规范明确要求初始化一个类时,它的超类必须提前完成初始化操作,接口例外)
- JVM启动包含main方法的启动类时。
Java虚拟机启动时被标明为启动类的类( JavaTest),直接使用 java.exe命令来运行某个主类
6.结束生命周期
在如下几种情况下,Java虚拟机将结束生命周期
执行了 System.exit()方法
程序正常执行结束
程序在执行过程中遇到了异常或错误而异常终止
由于操作系统出现错误而导致Java虚拟机进程终止
类加载器
类加载器的任务是根据一个类的全限定名来读取此类的二进制字节流到JVM中,然后转换为一个与目标类对应的java.lang.Class对象实例,在虚拟机提供了4种类加载器,启动(Bootstrap ClassLoader)类加载器、扩展(Extension ClassLoader)类加载器、应用程序(Application ClassLoader)类加载器、自定义(User ClassLoader)类加载器。

- 启动类加载器:
它使用C++实现(这里仅限于Hotspot,也就是JDK1.5之后默认的虚拟机,有很多其他的虚拟机是用Java语言实现的),是虚拟机自身的一部分;这个类加载器负责放在\lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的类库。用户无法直接使用。 - 扩展类加载器:
这个类加载器由sun.misc.Launcher$AppClassLoader实现。它负责\lib\ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库。用户可以直接使用。 - 应用程序类加载器:
这个类由sun.misc.Launcher$AppClassLoader实现。是ClassLoader中getSystemClassLoader()方法的返回值。它负责用户路径(ClassPath)所指定的类库。用户可以直接使用。如果用户没有自己定义类加载器,默认使用这个。 - 自定义加载器:用户自己定义的类加载器。
原文链接:https://blog.csdn.net/know9163/article/details/80574488
完整讲解请看这里:
类加载机制⭐️
JVM的类加载机制主要有如下3种。
- 全盘负责:所谓全盘负责,就是当一个类加载器负责加载某个Class时,该Class所依赖和引用其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。
- 双亲委派:所谓的双亲委派,则是先让父类加载器试图加载该Class,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类。通俗的讲,就是某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父加载器,依次递归,如果父加载器可以完成类加载任务,就成功返回;只有父加载器无法完成此加载任务时,才自己去加载。
- 缓存机制。缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区中搜寻该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓冲区中。这就是为很么修改了Class后,必须重新启动JVM,程序所做的修改才会生效的原因。
双亲委派机制

- 工作原理:
如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器。
如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载。
即每个儿子都很懒,每次有活就丢给父亲去干,直到父亲说这件事我也干不了时,儿子自己才想办法去完成。 - 优点:
– Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载。当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。
– 安全因素,java核心api中定义类型不会被随意替换。假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。
JVM内存结构
详解看链接处:添加链接描述

内存溢出&内存泄漏
内存溢出:是指程序所需要的内存超出了系统所能分配的内存(包括动态扩展)的上限。
内存泄漏:是指分配出去的内存没有被回收回来,由于失去了对该内存区域的控制,因而造成了资源的浪费。
Java中一般不会产生内存泄露,因为有垃圾回收器自动回收垃圾,但这也不绝对,当我们new了一个对象,并保存了其引用,但是后面一直没用它,而垃圾回收器又不会去回收它,这便会造成内存泄露
一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
程序计数器
程序计数器(Program Counter Register)是一块较小的内存空间,可以看作是当前线程所执行字节码的行号指示器,指向下一个将要执行的指令代码,由执行引擎来读取下一条指令。更确切的说,一个线程的执行,是通过字节码解释器改变当前线程的计数器的值,来获取下一条需要执行的字节码指令,从而确保线程的正确执行。
程序计数器不会发生内存溢出(OutOfMemoryError即OOM)问题。
栈
JVM 中的栈包括 Java 虚拟机栈和本地方法栈,两者的区别就是,Java 虚拟机栈为 JVM 执行 Java 方法服务,本地方法栈则为 JVM 使用到的 Native 方法服务。
Native方法:JDK 中有很多方法是使用 Native 修饰的。Native 方法不是以 Java 语言实现的,而是以本地语言实现的(比如 C 或 C++)。Native 方法是与操作系统直接交互的。
比如通知垃圾收集器进行垃圾回收的代码 System.gc(),就是使用 native 修饰的。
public final class System {
public static void gc() {
Runtime.getRuntime().gc();
}
}
public class Runtime {
//使用native修饰
public native void gc();
}
- 虚拟机栈
定义:限定仅在表头进行插入和删除操作的线性表。即压栈(入栈)和弹栈(出栈)都是对栈顶元素进行操作的。所以栈是后进先出的。
栈是线程私有的,他的生命周期与线程相同。每个线程都会分配一个栈的空间,即每个线程拥有独立的栈空间。
系统自动分配与回收内存,效率较高,快速,存取速度比堆要快;是一块连续的内存的区域,有大小限制,如果超过了就会栈溢出,并抛出栈溢出的异常StackOverflowError;Java会自动释放掉为该变量所分配的内存空间。
每个方法被执行的时候都会同时创建一个栈帧,对于执行引擎来讲,活动线程中,只有栈顶的栈帧是有效的,称为当前栈帧,这个栈帧所关联的方法称为当前方法,执行引擎所运行的所有字节码指令都只针对当前栈帧进行操作。
栈帧用于存储局部变量表、操作数栈、动态链接、方法返回地址和一些额外的附加信息。在编译程序代码时,栈帧中需要多大的局部变量表、多深的操作数栈都已经完全确定了,并且写入了方法表的Code属性之中(class文件中是属性表里,加载后是方法区里)。
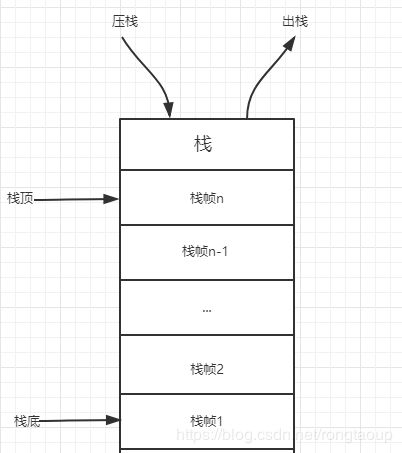
栈中存储的是什么?
栈帧是栈的元素。每个方法在执行时都会创建一个栈帧。栈帧中存储了局部变量表、操作数栈、动态连接和方法出口 等信息。每个方法从调用到运行结束的过程,就对应着一个栈帧在栈中压栈到出栈的过程。
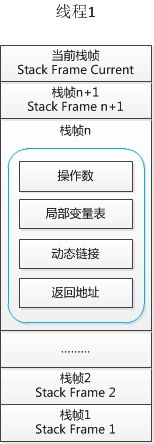
-
局部变量列表
栈帧中,由一个局部变量表存储数据。局部变量表中存储了基本数据类型(boolean、byte、char、short、int、float、long、double)的局部变量(包括参数)、和对象的引用(String、数组、对象等),但是不存储对象的内容。局部变量表所需的内存空间在编译期间完成分配,在方法运行期间不会改变局部变量表的大小。 -
操作数栈
操作数栈是一个后进先出栈。操作数栈的元素可以是任意的Java数据类型。方法刚开始执行时,操作数栈是空的,在方法执行过程中,通过字节码指令对操作数栈进行压栈和出栈的操作。通常进行算数运算的时候是通过操作数栈来进行的,又或者是在调用其他方法的时候通过操作数栈进行参数传递。操作数栈可以理解为栈帧中用于计算的临时数据存储区。
原文链接:https://blog.csdn.net/rongtaoup/article/details/89142396
堆
堆是Java虚拟机所管理的内存中最大的一块存储区域。堆内存被所有线程共享。主要存放使用new关键字创建的对象。所有对象实例以及数组都要在堆上分配。垃圾收集器就是根据GC算法,收集堆上对象所占用的内存空间(收集的是对象占用的空间而不是对象本身)。
根据Java虚拟机规范的规定,Java堆可以处在物理上不连续的内存空间中,只要逻辑上是连续的即可。如果在堆中没有内存可分配时,并且堆也无法扩展时,将会抛出OutOfMemoryError异常。
方法区
方法区同 Java 堆一样是被所有线程共享的区间,用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码。更具体的说,静态变量+常量+类信息(版本、方法、字段等)+运行时常量池存在方法区中。

注意:JDK1.8 使用元空间 MetaSpace 替代方法区,元空间并不在 JVM中,而是使用本地内存。元空间两个参数:
MetaSpaceSize:初始化元空间大小,控制发生GC阈值
MaxMetaspaceSize : 限制元空间大小上限,防止异常占用过多物理内存
常量池
常量池中存储编译器生成的各种字面量和符号引用。字面量就是Java中常量的意思。比如文本字符串,final修饰的常量等。方法引用则包括类和接口的全限定名,方法名和描述符,字段名和描述符等。
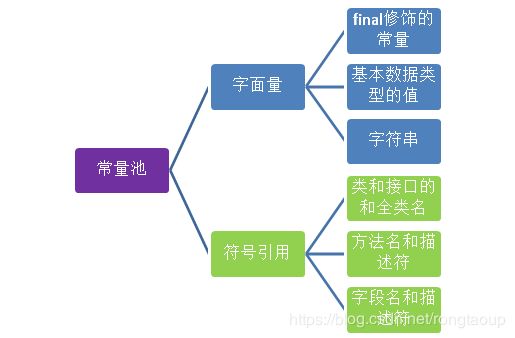
Integer常量池
Integer 的 valueOf 方法:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
Integer 的 valueOf 方法很简单,它判断变量是否在 IntegerCache 的最小值(-128)和最大值(127)之间,如果在,则返回常量池中的内容,否则 new 一个 Integer 对象。
而 IntegerCache 是 Integer的静态内部类,作用就是将 [-128,127] 之间的数“缓存”在 IntegerCache 类的 cache 数组中,valueOf 方法就是调用常量池的 cache 数组。
String常量池
String 是由 final 修饰的类,是不可以被继承的。
对于字符串常量的 + 号连接,在程序编译期,JVM就会将其优化为 + 号连接后的值。所以在编译期其字符串常量的值就确定了。
String a = "a1";
String b = "a" + 1;
System.out.println((a == b)); //result = true
对于字符串引用的 + 号连接问题,由于字符串引用在编译期是无法确定下来的,在程序的运行期动态分配并创建新的地址存储对象。
String str1 = "a";
String str2 = "ab";
String str3 = str1 + "b";
System.out.print(str2 == str3);//false
Follow Q:堆和栈的区别是什么?
栈内存:栈内存首先是一片连续内存区域,存储的都是局部变量,凡是定义在方法中的都是局部变量(方法外的是全局变量),for循环内部定义的也是局部变量,是先加载方法才能进行局部变量的定义,所以方法先进栈,然后再定义变量,变量有自己的作用域,一旦离开作用域,变量就会被释放。栈内存的更新速度很快,因为局部变量的生命周期都很短。
堆内存:存储的是数组和对象(其实数组就是对象),凡是new建立的都是在堆中,堆中存放的都是实体(对象),实体用于封装数据,而且是封装多个(实体的多个属性),如果一个数据消失,这个实体也没有消失,还可以用,所以堆是不会随时释放的,但是栈不一样,栈里存放的都是单个变量,变量被释放了,那就没有了。堆里的实体虽然不会被释放,但是会被当成垃圾,Java有垃圾回收机制不定时的收取。
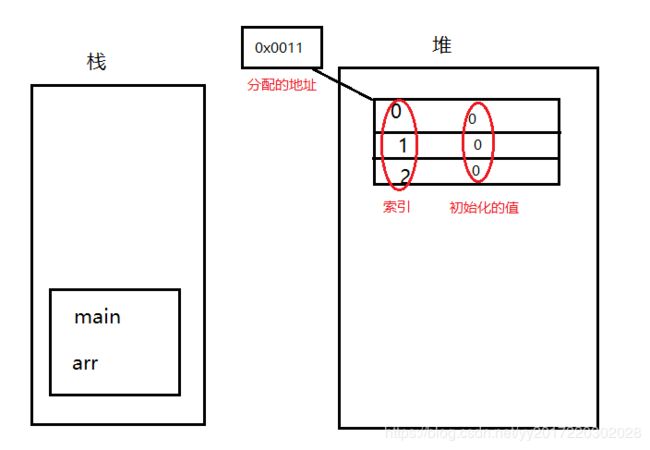
- 主函数里的语句 int [] arr=new int [3];在内存中是怎么被定义的?
首先,主函数先进栈,在栈中定义一个变量arr,接下来为arr赋值。但是右边的堆中并不是一个具体值,而是一个实体。
实体创建在堆里,在堆里首先通过new关键字开辟一个空间,内存在存储数据的时候都是通过地址来体现的,地址是一块连续的二进制,然后给这个实体分配一个内存地址。
数组都是有一个索引,数组这个实体在堆内存中产生之后每一个空间都会进行默认的初始化(这是堆内存的特点,未初始化的数据是不能用的,但在堆里是可以用的,因为默认初始化过了,但是在栈里没有),不同的类型初始化的值不一样。
所以堆和栈里就创建了变量和实体:
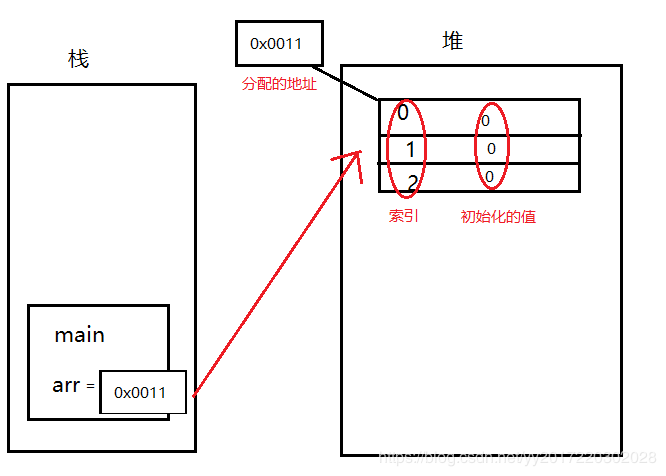
- 堆和栈是怎么联系起来的呢?
由于已经给堆分配了一个地址,那么把堆的地址赋给arr,arr就通过地址指向了数组。所以arr想操纵数组时,就通过地址,而不是直接把实体都赋给它。这种我们不再叫它基本数据类型,而叫引用数据类型。称为:arr引用了堆内存当中的实体。
- 如果当int [] arr=null;又是如何的呢?
则arr不做任何指向,null的作用就是取消引用数据类型的指向。
注意: 当一个实体,没有引用数据类型指向的时候,它在堆内存中不会被释放,而被当做一个垃圾,在不定时的时间内自动回收,因为Java有一个自动回收机制,(而c++没有,需要程序员手动回收,如果不回收就越堆越多,直到撑满内存溢出,所以Java在内存管理上优于c++)。自动回收机制自动监测堆里是否有垃圾,如果有,就会自动的做垃圾回收的动作,但是什么时候收不一定。
堆与栈的区别就很明显:
- 栈内存存储的是局部变量;而堆内存存储的是实体;
- 栈内存的更新速度要快于堆内存,因为局部变量的生命周期很短;
- 栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。
垃圾回收机制
先看这里哦:垃圾回收
垃圾回收机制(GC)是用来释放内存中的资源的,可以有效地防止内存泄露,有效地使用空闲的内存。
哪些内存需要回收?
程序计数器、虚拟机栈、本地方法栈3个区域随线程而生、随线程而灭,因此这几个区域的内存分配和回收都具备确定性,就不需要过多考虑回收的问题,因为方法结束或者线程结束时,内存自然就跟随着回收了。而Java堆区和方法区,这部分内存的分配和回收是动态的,正是垃圾收集器所需关注的部分。
垃圾收集器在对堆区和方法区进行回收前,首先要确定这些区域的对象哪些可以被回收,哪些暂时还不能回收,这就要用到判断对象是否存活的算法!
- 引用计数算法
引用计数是垃圾收集器中的早期策略。在这种方法中,堆中每个对象实例都有一个引用计数。当一个对象被创建时,就将该对象实例分配给一个变量,该变量计数设置为1。当任何其它变量被赋值为这个对象的引用时,计数加1(a = b,则b引用的对象实例的计数器+1),但当一个对象实例的某个引用超过了生命周期或者被设置为一个新值时,对象实例的引用计数器减1。任何引用计数器为0的对象实例可以被当作垃圾收集。当一个对象实例被垃圾收集时,它引用的任何对象实例的引用计数器减1。
即对于堆中那些没有引用的实例 可以回收。
优缺点
-
优点:引用计数收集器可以很快的执行,交织在程序运行中。对程序需要不被长时间打断的实时环境比较有利。
-
缺点:无法检测出循环引用。如父对象有一个对子对象的引用,子对象反过来引用父对象。这样,他们的引用计数永远不可能为0。
- 可达性分析算法
可达性分析算法是从离散数学中的图论引入的,程序把所有的引用关系看作一张图,从一个节点GC ROOT开始,寻找对应的引用节点,找到这个节点以后,继续寻找这个节点的引用节点,当所有的引用节点寻找完毕之后,剩余的节点则被认为是没有被引用到的节点,即无用的节点,无用的节点将会被判定为是可回收的对象。
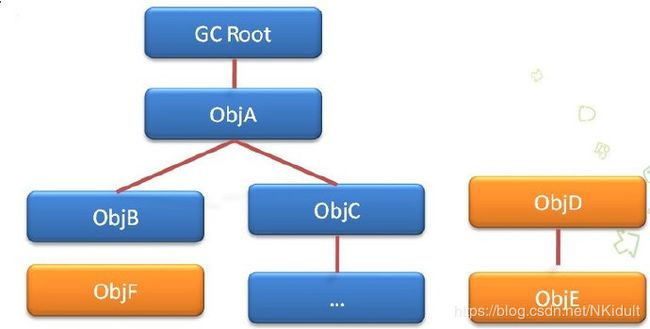
在Java语言中,可作为GC Roots的对象包括下面几种
a) 虚拟机栈中引用的对象(栈帧中的本地变量表);
b) 方法区中类静态属性引用的对象;
c) 方法区中常量引用的对象;
d) 本地方法栈中JNI(Native方法)引用的对象。
在可达性分析算法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑”阶段。如果对象在进行可达性分析后发现没有与GC Roots相连接的引用链,那它将会被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行finapze()方法。当对象没有覆盖finapze()方法,或者finapze()方法已经被虚拟机调用过,虚拟机将这两种情况都视为“没有必要执行”。也就是覆盖过finapze()方法的不会被回收。
还有对方法区中内容的回收:
后面会补
常用垃圾回收算法
- 引用计数法
引用计数法实现简单,效率较高,在大部分情况下是一个不错的算法。其原理是:给对象添加一个引用计数器,每当有一个地方引用该对象时,计数器加1,当引用失效时,计数器减1,当计数器值为0时表示该对象不再被使用。需要注意的是:引用计数法很难解决对象之间相互循环引用的问题,主流Java虚拟机没有选用引用计数法来管理内存。 - 标记-清除算法(Mark-Sweep)
标记-清除算法分为两个阶段:标记阶段和清除阶段。标记阶段的任务是标记出所有需要被回收的对象,清除阶段就是回收被标记的对象所占用的空间。
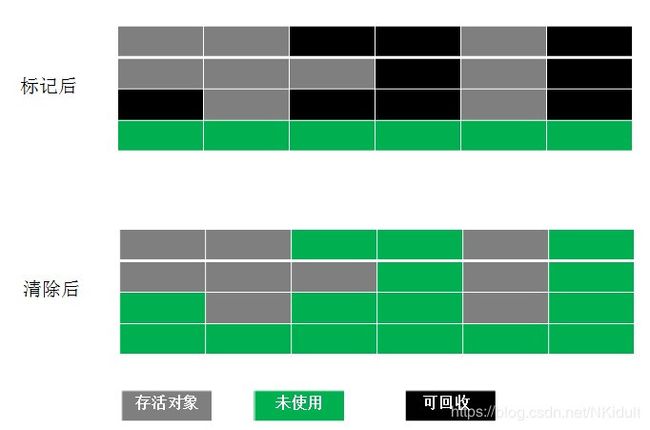
标记-清除算法采用从根集合(GC Roots)进行扫描,对存活的对象进行标记,标记完毕后,再扫描整个空间中未被标记的对象,进行回收。
优点:标记-清除算法不需要进行对象的移动,只需对不存活的对象进行处理,在存活对象比较多的情况下极为高效。
缺点:比较严重的问题就是容易产生内存碎片,碎片太多可能会导致后续过程中需要为大对象分配空间时无法找到足够的空间而提前触发新的一次垃圾收集动作。 - 复制算法(Copying)
为了解决Mark-Sweep算法的缺陷,Copying算法就被提了出来。它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用的内存空间一次清理掉,这样一来就不容易出现内存碎片的问题。
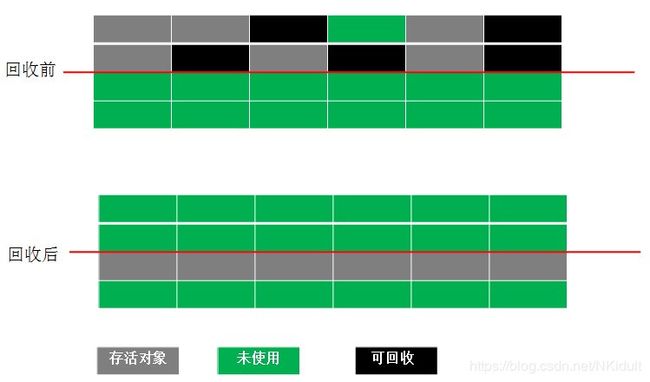
这种算法虽然实现简单,运行高效且不容易产生内存碎片,但是却对内存空间的使用做出了高昂的代价,因为能够使用的内存缩减到原来的一半。 - 标记-整理算法(Mark-compact)
为了解决Copying算法的缺陷,充分利用内存空间,提出了Mark-Compact算法。该算法标记阶段和Mark-Sweep一样,但是在完成标记之后,它不是直接清理可回收对象,而是将存活对象都向一端移动向一端移动(美团面试题目,记住是完成标记之后,先不清理,先移动再清理回收对象),然后清理掉端边界以外的内存。
优缺点:标记-整理算法是在标记-清除算法的基础上,又进行了对象的移动,因此成本更高,但是却解决了内存碎片的问题。 - 分代收集算法
分代收集算法是目前大部分JVM的垃圾收集器采用的算法。它的核心思想是根据对象存活的生命周期将内存划分为若干个不同的区域。一般情况下将堆区划分为老年代(Tenured Generation)和新生代(Young Generation),在堆区之外还有一个代就是永久代(Permanet Generation)。老年代的特点是每次垃圾收集时只有少量对象需要被回收,而新生代的特点是每次垃圾回收时都有大量的对象需要被回收,那么就可以根据不同代的特点采取最适合的收集算法。
新生代: 采取Copying算法,因为新生代中每次垃圾回收都要回收大部分对象,也就是说需要复制的操作次数较少。
老年代:一般使用的是Mark-Compact算法,因为每次回收都只回收少量对象。
持久代:(也就是方法区的回收)用于存放静态文件,如Java类、方法等。还未整理
- 新生代和老年代的区别:
GC何时触发
由于对象进行了分代处理,因此垃圾回收区域、时间也不一样。GC有两种类型:Scavenge GC和Full GC。
- Scavenge GC
一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发Scavenge GC,对Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区。然后整理Survivor的两个区。
这种方式的GC是对年轻代的Eden区进行,不会影响到年老代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。因而,一般在这里需要使用速度快、效率高的算法,使Eden去能尽快空闲出来。
- Full GC
对整个堆进行整理,包括Young、Tenured和Perm。Full GC因为需要对整个堆进行回收,所以比Scavenge GC要慢,因此应该尽可能减少Full GC的次数。在对JVM调优的过程中,很大一部分工作就是对于Full GC的调节。有如下原因可能导致Full GC:
a) 年老代(Tenured)被写满;
b) 持久代(Perm)被写满;
c) System.gc()被显示调用;
d) 上一次GC之后Heap的各域分配策略动态变化;
IO
ipad
BIO
NIO
AIO
常用设计模式
单例模式
这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
特点
- 单例类只能有一个实例。
- 单例类必须自己创建自己的唯一实例。
- 单例类必须给所有其他对象提供这一实例。
使用场景:
1、要求生产唯一序列号。
2、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
3、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
例如:打印机管理器,文件处理
注意事项:getInstance() 方法中需要使用同步锁 synchronized (Singleton.class) 防止多线程同时进入造成 instance 被多次实例化。
实现:
一个 SingleObject 类。SingleObject 类有它的本身的一个private静态实例,private构造函数和以及一个共有的静态方法供外界获取他的静态实例,以及一个showMessage()。
- 创建一个 Singleton 类。
public class SingleObject {
//创建 SingleObject 的一个对象(必须自己创建自己的唯一实例)
private static SingleObject instance = new SingleObject();
//让构造函数为 private,这样该类就不会被实例化(只能有一个实例。)
private SingleObject(){}
//获取唯一可用的对象的静态方法(给其他的提供)
public static SingleObject getInstance(){
return instance;
}
public void showMessage(){
System.out.println("Hello World!");
}
}
- 从 singleton 类获取唯一的对象。
public class SingletonPatternDemo {
public static void main(String[] args) {
//不合法的构造函数
//编译时错误:构造函数 SingleObject() 是不可见的
//SingleObject object = new SingleObject();
//获取唯一可用的对象
SingleObject object = SingleObject.getInstance();
//显示消息
object.showMessage();
}
}
单例模式的几种实现方式:
- 懒汉式
顾名思义就是实例在用到的时候才去创建,“比较懒”,用的时候才去检查有没有实例,如果有则返回,没有则新建。有线程安全和线程不安全两种写法,区别就是synchronized关键字。
- 无锁 synchronized,延迟初始化,在多线程不能正常工作。
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
- 线程安全,延迟初始化,效率低
public class Singleton {
private static Singleton instance;
private Singleton (){}
//区别就是加了synchronized锁
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
- 饿汉式
线程安全,比较常用,但容易产生垃圾,因为一开始就初始化。
JDK1.5 起
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}
- 双检锁/DCL
这种方式采用双锁机制,安全且在多线程情况下能保持高性能。
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
双重检查模式,进行了两次的判断,第一次是为了避免不要的实例,第二次是为了进行同步,避免多线程问题。由于singleton=new Singleton()对象的创建在JVM中可能会进行重排序,在多线程访问下存在风险,使用volatile修饰signleton实例变量有效,解决该问题。
- 静态内部类
这种方式能达到双检锁方式一样的功效,但实现更简单。对静态域使用延迟初始化,应使用这种方式而不是双检锁方式。这种方式只适用于静态域的情况,双检锁方式可在实例域需要延迟初始化时使用。
这种方式同样利用了 classloader 机制来保证初始化 instance 时只有一个线程,它跟第 3 种方式不同的是:第 3 种方式只要 Singleton 类被装载了,那么 instance 就会被实例化(没有达到 lazy loading 效果),而这种方式是 Singleton 类被装载了,instance 不一定被初始化。因为 SingletonHolder 类没有被主动使用,只有通过显式调用 getInstance 方法时,才会显式装载 SingletonHolder 类,从而实例化 instance。想象一下,如果实例化 instance 很消耗资源,所以想让它延迟加载,另外一方面,又不希望在 Singleton 类加载时就实例化,因为不能确保 Singleton 类还可能在其他的地方被主动使用从而被加载,那么这个时候实例化 instance 显然是不合适的。这个时候,这种方式相比第 3 种方式就显得很合理。
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
- 枚举
默认枚举实例的创建是线程安全的,并且在任何情况下都是单例。实际上
枚举类隐藏了私有的构造器。
枚举类的域 是相应类型的一个实例对象
那么枚举类型日常用例是这样子的:
public enum Singleton {
INSTANCE;
}
public enum Singleton {
INSTANCE
//doSomething 该实例支持的行为
//可以省略此方法,通过Singleton.INSTANCE进行操作
public static Singleton get Instance() {
return Singleton.INSTANCE;
}
}
单例模式是创建型模式,都会新建一个实例。那么一个重要的问题就是反序列化。当实例被写入到文件到反序列化成实例时,我们需要重写readResolve方法,以让实例唯一。
private Object readResolve() throws ObjectStreamException{
return singleton;
}
面试时写静态内部类的就可以
观察者模式
观察者模式(Observer),又叫发布-订阅模式(Publish/Subscribe),定义对象间一种一对多的依赖关系,使得每当一个对象改变状态,则所有依赖于它的对象都会得到通知并自动更新。(subject & observer)
观察者模式的主要优点在于可以实现表示层和数据逻辑层的分离,并在观察目标和观察者之间建立一个抽象的耦合,支持广播通信;其主要缺点在于如果一个观察目标对象有很多直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间,而且如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。
具体链接:实现方式看这里
装饰者模式
装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构。这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装。
这种模式创建了一个装饰类,用来包装原有的类,为已有功能动态的添加更多功能的一种方式。
优点:
有效的把类的核心职责和装饰功能区分开,职责更细化。
使用场景:当系统需要增加新功能时,向旧的类中添加新的代码,装饰原有类的核心职责或主要行为
适配器模式
适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁。这种类型的设计模式属于结构型模式,它结合了两个独立接口的功能。
这种模式涉及到一个单一的类,该类负责加入独立的或不兼容的接口功能。
java适配器模式有两种,类适配器和对象适配器:
详细的看这里:具体使用
工厂模式
代理模式(proxy)
代理模式给某一个对象提供一个代理对象,并由代理对象控制对原对象的引用。通俗的来讲代理模式就是我们生活中常见的中介。
静态代理,动态代理、CGLIB代理
动态代理:jdk自带的和cglib动态代理
MVC模式
拦截过滤器模式
Object类
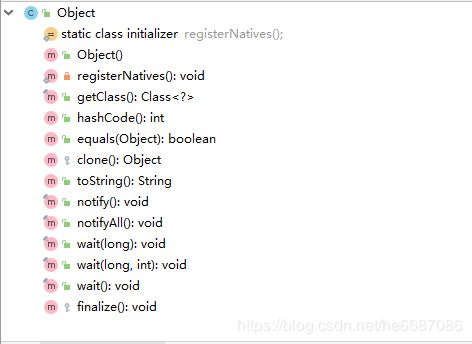
Object类中的大部分方法都是native方法,用此关键字修饰的方法是Java中的本地方法,一般是用C/C++语言来实现。
- 构造方法
Object类中没有显示的提供构造方法,这是编译器默认提供的。 - registerNatives()方法

- getClass()方法
获取运行时类型,返回值为Class对象

方法用final,说明此方法不能被重写。此方法返回类运行时的类型,并且返回的类是被此类的静态同步方法锁定了 - hashCode()方法
返回该对象的哈希码值,是为了提高哈希表的性能(HashTable)
返回对象的哈希码,是一个整数。这个方法遵守以下三个规则:
- 在java程序运行期间,若用于equals方法的信息或者数据没有修改,name同一个对象多次调用此方法,返回的哈希码是相同的。而在两次独立的运行java程序时,对于同一对象,不需要返回的哈希码相同
- 如果根据equals方法,两个对象相同,则这两个对象的哈希码一定相同
- 假如两个对象通过equals方法比较不相同,那么这两个对象调用hashCode也不是要一定不同,相同也是可以的。但是使用者应该知道对不同的对象产生不同的hashCode是可以提高hash tables的性能的。
在实际使用中,要尽量保证对于不同的对象产生不同的哈希码。hashCode的典型实现是将对象的内部地址转为一个整数,但是这种实现技术不是Java语言必须要采用的。
Object类中只有一个hashcode接口,不同的数据结构有不同的hashcode实现方法,也就是有不同的hash函数。
- equals(Object obj)

判断两个对象是否相等,在Object源码中equals就是使用 == 去判断,所以在Object中equals是等价于==的,但是在String及某些类对equals进行了重写,实现不同的比较。 - clone() 方法
如果在clone方法中调用super.clone()方法需要实现Cloneable接口,否则会抛出CloneNotSupportedException。

此方法只实现了一个浅层拷贝,对于基本类型字段成功拷贝,但是如果是嵌套对象,只做了赋值,也就是只把地址拷贝了,所以没有成功拷贝,需要自己重写clone方法进行深度拷贝。
浅拷贝如何该深拷贝? 类中所有的引用类型成员都要实现Clonable接口,重写clone方法。
例子可见:这个比上面的那个更清楚一些 - toString() 方法
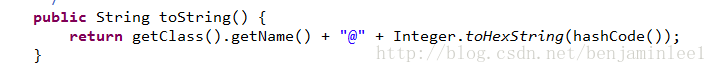
默认返回的是当前对象的类名+hashCode的16进制数字。,用于描述当前对象的信息,可以重写返回对自己有用的信息。 - wait()方法
在Object中存在三种wait方法,如下:
public final native void wait(long timeout) throws InterruptedException;
public final void wait(long timeout, int nanos) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos > 0) {
timeout++;
}
wait(timeout);
}
public final void wait() throws InterruptedException {
wait(0);
}
可见wait()和wait(long timeout, int nanos)都在在内部调用了wait(long timeout)方法。
wait方法会引起当前线程阻塞,直到另外一个线程在对应的对象上调用notify或者notifyAll()方法,或者达到了方法参数中指定的时间。
调用wait方法的当前线程一定要拥有对象的监视器锁。
wait方法会把当前线程T放置在对应的object上的等待队列中,在这个对象上的所有同步请求都不会得到响应。线程调度将不会调用线程T,在以下四件事发生之前,线程T一直处于休眠状态(线程T是在其代码中调用wait方法的那个线程)
- 当其他的线程在对应的对象上调用notify方法,而在此对象的对应的等待 队列中将会任意选择一个线程进行唤醒。
- 其他的线程在此对象上调用了notifyAll方法
- 其他的线程调用了interrupt方法来中断线程T
- 等待的时间已经超过了wait中指定的时间。如果参数timeout的值为0,不是指真实的等待时间是0,而是线程等待直到被另外一个线程唤醒。
为什么wait方法一般要写在while循环里
一般在我们编程的时候wait方法都是写在while循环中,while循环中是测试条件,主要有以下几个原因
- 在某个线程调用notify到等待线程被唤醒的过程中,有可能出现另一个线程得到了锁并修改了条件使得条件不在满足
- 条件不满足,但另一个线程意外地调用了notify
- 只有某些等待线程的条件满足了,但通知线程调用了notifyAll
- 有可能出现“伪唤醒”
“伪唤醒”:
线程在没有被唤醒,中断或者时间耗尽的情况下仍然能够被唤醒,这叫做伪唤醒。虽然在实际中,这种情况很少发生,但是程序一定要测试这个能够唤醒线程的条件,并且在条件不满足时,线程继续等待。换言之,wait操作总是出现在循环中,就像下面这样:
synchronized(对象){
while(条件不满足){
对象.wait();
}
对应的逻辑处理
}
- notify方法
通知可能等待该对象的对象锁的其他线程。由JVM(与优先级无关)随机挑选一个处于wait状态的线程。
- 在调用notify()之前,线程必须获得该对象的对象级别锁
- 执行完notify()方法后,不会马上释放锁,要直到退出synchronized代码块,当前线程才会释放锁
- notify()一次只随机通知一个线程进行唤醒
- notifyAll()方法
和notify()差不多,只不过是使所有正在等待池中等待同一共享资源的全部线程从等待状态退出,进入可运行状态
让它们竞争对象的锁,只有获得锁的线程才能进入就绪状态
每个锁对象有两个队列:就绪队列和阻塞队列
- 就绪队列:存储将要获得锁的线程
- 阻塞队列:存储被阻塞的线程
读取一个大量的log日志,如何提取所有指定时间戳的日志内容
Tomcat
直接看这个链接就可以啦~
Servlet
懒得弄了,看这个就ok