http://blog.csdn.net/pizi0475/article/details/6243055
困扰了一个多月的问题,今天终于有个阶段性的了结了,虽然不知道算不算真正的了结.
多核的cpu现在是大势所趋,渲染是一个很费时的活,所以应该考虑考虑能不能利用多核来提升这部分的性能.引擎一开始没有在多线程方面作任何的考虑,因为我从来就不喜欢多线程,这方面的思考能力不强,而且一开始写个单线程的engine已经够费事了,要加入多线程的设计对我来说实在是太难了.但是在积累了这么多时间的经验以后,我开始考虑加入多线程的支持,这玩意对架构的影响很大,所以加入设计还是宜早不宜迟.一开始先加入了多线程载入资源的模块,也顺便恢复一下早已荒废多年的多线程编程技能.接下来就该考虑将渲染部分放入一个单独的线程中去了.
首先,为什么呢?为什么要把渲染部分放到一个单独的线程中去呢?有什么好处呢?我的理解是这样的:显卡可以看成是一个外设,渲染的过程就是cpu不停的给gpu发各种命令,根据d3d的文档上说,d3d内部有一个command buffer,cpu在调用各种d3d的api时,其实是往这个command buffer里添加命令,这个command buffer是有一定大小的,当这个buffer满了以后,会有一个flush过程:这个buffer里的命令会被一齐扔给gpu去执行,然后这个buffer会被清空,以接受新的命令.按照d3d的文档上说,这个flush过程是很慢的,它必须要等待这个command buffer里的命令全部被gpu执行完,才会返回,不过我自己测了测,似乎不完全是这样,会有等待,但等待的时间好像并不是全部的执行完这些命令的时间,具体为什么,我也搞不清楚,也许写显卡驱动的人会更了解一些吧,d3d对我们这些写应用程序的人来说就是黑盒子.不过阻塞是一定会有的.所以我认为可以把gpu连同D3D看成一个类似硬盘的io设备.cpu通过调用d3d的api来给这个设备发命令,大多数情况下,这些api立即就返回了(这些命令被cache在d3d内部的一个command buffer里),但是偶尔的,当一个api调用试图在一个已经满了的command buffer里再加入命令时,就会触发一次d3d内部的flush过程,而这个时候,这个api调用就必须等待这个io设备了,也就是cpu这个时候是空闲的,计算能力在这里被浪费了.很多关于d3d的教材都提到不要调用太多的draw call,应该把多个draw call合并在同一个batch里,我以前以为,可能是因为d3d api的调用本身有开销,我现在的理解是,draw call太多,会导致太多的d3d api调用,太多的命令,而这样会导致d3d内部的command buffer频繁溢出,从而导致d3d内部频繁的flush,加剧了cpu等待gpu的情况. 如果d3d的内部运作模式真是我上面描述的那样的话,把渲染部分放到一个单独的线程中去就显得有必要了,因为可以把cpu在等待gpu的时间充分利用起来,或者至少不会让这些等待耽误到主线程的运行.
接下来,就要考虑怎么来做了.显然,这是一个典型的producer-consumer的结构,主线程(procucer)将要执行的渲染命令不停的加到一个队列里,再开一个渲染线程(consumer)不停的从这个个队列里读取命令,并执行.一开始我主要考虑要减少这些命令的个数,这样实现可以简单些,效率可以高些,所以打算把我自己实现的整个渲染系统放到一个单独的线程中去,把原来的接口全部转换为可以被队列化的一个个命令.干了一段时间后,发现实现难度还不小,接口数量还是太多了,所以又打算把接口提升到更高的层次中去,也就是把整个场景的渲染模块放到一个单独的线程中去,这个渲染模块主要包含了渲染对象的场景管理以及渲染分类.这样做的确减少了接口数量,所以虽然比较艰辛,我终于几乎还是把它给实现了,不过就在接近实现的时候,我又把整个问题重新考虑了一下,发现似乎又走了弯路.我的想法是这样:
*.对于目前大多数的游戏,每一帧的运算主要包括两部分:渲染和逻辑.
*.对于3D游戏,gpu完成渲染部分,cpu完成逻辑部分.
*.渲染部分是非常耗时的,一般来说比逻辑部分的消耗的时间要多
*.发展的趋势是cpu朝多核方向发展,逻辑部分可以被分到多个线程去做.
*.XBOX360已经有6个核了.
*.gpu也会发展,但是目前的即时渲染的水平离电影级的渲染水平仍然有很大的差距.
*.所以,相当长的时间内,渲染的耗时仍然会是瓶颈
*.而目前的D3D的架构只允许使用一个单独的线程去驱动gpu
*.所以不应该让这个单独的线程做额外的工作了,也就是渲染线程应该越单纯越好,
*.而最最单纯的就是在这个渲染线程里只做一件事情,就是给D3D发命令.
所以最后我采取了这样的方法,我把所用到的D3D接口函数全部重新写了一下,在这些函数里,我把原来对d3d的调用全部转化成一个个的命令,加到一个队列里,而由一个单独的渲染线程从这个队列里读取命令,再把它们传递给D3D.这样做还有一个附加的好处就是,它对整个引擎的架构的影响很小,所有的功能被局限在一个集中的模块里,并且可以很方便的enable/disable,很方便的在多线程/单线程渲染这两者之间切换,便于对比调试.而且如果这个模块写得完美,甚至可以开放给公众使用.
Threading the OGRE3D Render System(by Jeff Andrews)
,这篇文章也提到过这种方法,它提出了三种线程化的方案,主要也是按照渲染线程所处的层级来分的,和我上面说的比较类似,并且讨论了不少实现细节.不过它似乎认为在最高层次上进行线程化可以最大限度的发挥多核的威力,我想他可能是站在cpu计算瓶颈的角度上来看的吧.作者也为在最低层次上线程化的方案(重写D3D接口)作了实现(有源代码下载,我参考了一下),并做了测试,但效果似乎并不那么显著.不过他说it's doable.
实现这套接口对我来说并不是件容易的事,先是磨磨蹭蹭花了一周才写完,测了一下,结果很糟糕,在同事的双核电脑上比单线程版本要慢很多,以我贫乏的多核应用经验,一开始我以为是cpu的问题,后来在vista上测试的时候,发现了不错的结果,多线程版本比单线程版本几乎快了一倍(说实话,我第一次对vista有了好感),但是xp下就不行,进而怀疑操作系统的问题,下载了一个多核性能的bench mark,结果一切正常,问题看来还是在自己身上.最终还是找出了问题所在.目前的这个测试用例在双核的电脑上的有不小的性能提升,执行时间大概是单线程版本的60%左右,在单核的电脑上性能有微小的下降.还没有用更多的例子测过,所以不一定能说明问题,但至少说明是有前途的,是doable的.
实现过程中有一个地方值得注意,就是vertex buffer的Lock()/Unlock()的处理.上面说的这篇文章里也重点提到了这个问题,并提出了两种解决方法,Partially Buffered Locks和Fully Buffered Locks.我的方法有所不同,我将vb的lock分为三种情况:
1.static的vertex buffer,通常这种vb用来存储不会发生变化的vertex 数据,一般只在初始化的时候需要lock()/unlock(),对性能的影响不是很大,所以在lock时,会对command buffer进行一次flush,也就是说主线程等待渲染线程将当前command buffer里的所有命令全处理完后,才进行lock()/unlock()
2.dynamic的vertex buffer,no overwrite的lock(),所谓no overwrite的lock,就是lock vb后,使用者可以保证不去覆写那些已经被用到的vertex数据(这些vertex的数据可能正在被gpu用来绘制),在这种情况下,可以比较简单的处理,只要暂时冻结渲染线程的处理,然后进行lock就行了,然后在unlock后,再恢复渲染线程的处理.
3.dynamic的vertex buffer,discard的lock(),这种lock将会丢弃原来vb中的所有内容,这时候显然不能简单的对这个vb使用discard标志进行lock,因为使用这个vb进行绘制的命令可能还在command buffer里,等待渲染线程的处理.我一开始的解决方法是:先冻结住渲染线程的执行,然后添加一条release这个vb的命令到command buffer中去,然后再创建一个新的dynamic的vertex buffer,并对它进行lock,返回lock的数据指针,当unlock后,再恢复渲染线程的执行.后来做了些优化,因为在nVidia的卡上,创建一个vertex buffer似乎对性能有很大的影响,所以我改为使用一个vertex buffer的pool,vb不会被真正release掉,而是扔到这个pool里,当需要新的vb时,再从这个pool里分配.这样可以使性能开销降到最低.
在实际应用中,情况2应该是最常使用的,它的性能开销也是最小的.只需要要锁一下渲染线程.
对于texture/surface的lock()/unlock(),似乎没有很好的方法,必须flush一下command buffer.好在这种情况并不会太频繁的出现.而偶尔flush一下command buffer也不是那么的不可忍受.
顺便提一下多线程编程的一个注意点,A线程访问变量a,同时B线程访问变量b,如果a和b这两个变量在地址空间上离的很近的话,是会降低性能的,不能做到真正的同步访问,所谓false sharing.要避免这种情况,这两个变量要分配在不同的内存段上面,内存段的长度可能和硬件有关系吧,一般比如说128个字节,不放心的话,再远一点.
首先我们得明确3D引擎使用多线程的目的所在:
1、在CPU上进行的逻辑计算(比如骨骼动画粒子发射等)不影响渲染速度
2、较差的GPU渲染速度的低下不影响逻辑速度
第一个目标已经很明确了,我来解释下需要达到第二个目标的原因:许多动作游戏的逻辑判定是基于帧的,所以在渲染较慢的情况下,逻辑不能跳帧,而仍然需要严格执行才能保证游戏逻辑的正确性,这就导致了游戏速度的放慢,而实际上个人认为渲染保持15帧以上就已经可以正常进行游戏了。
在较差的GPU上跑《鬼泣4》《刺客信条》《波斯王子4》简直就像是慢镜头一样,完全没法玩。而实际上CPU跑满帧是没有问题的,如果能把逻辑帧和渲染帧彻底分离,即使渲染帧达不到要求,但CPU仍能正确的执行游戏逻辑,就可以解决动作游戏对GPU要求过高的问题。
我们先来看多线程Ogre的两种架构,第一种是middle-level multithread
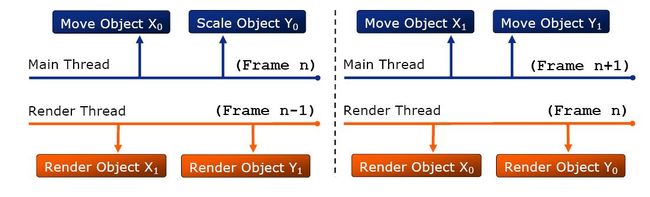
如上图所示,每个需渲染的实体被复制成了两份,主线程和渲染线程交替更新和渲染同一个实体的两个备份,并在一帧结束时同步,这种解决方案达到了第一个目标而并没有达到第二个目标,同时两份实体的维护也相对复杂,并且没法为更多核数的CPU进行扩展优化。
第二种Ogre多线程的方法是 low-level multithread
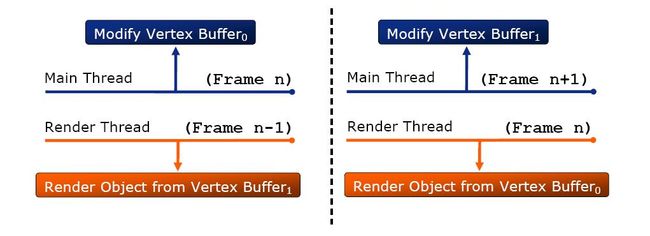
如图,将D3D对象复制两份,同样是在帧结束时同步并交换,和上面的优缺点类似。两种多线程Ogre的解决方案都是在引擎层完成的,对上层应用透明,对于用户而言无需考虑多线程细节,这点是非常不错的。
接下来我们来看SIGGRAPH2008上,id soft提出的多线程3D引擎的方案
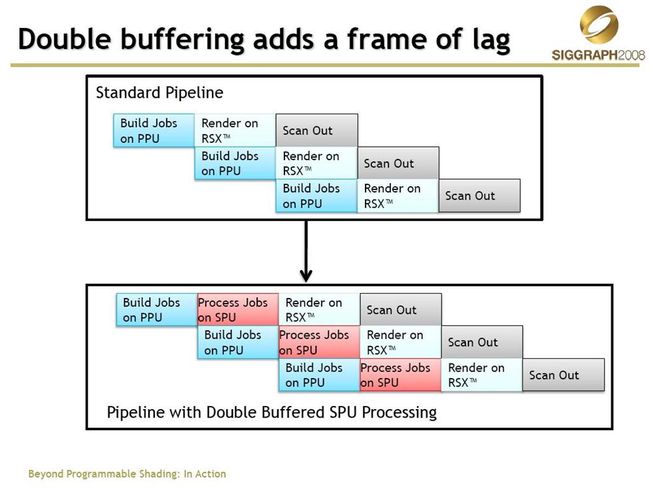
这里是已PS3的引擎结构为例的,与PC有较大的差别,其中SPU是Cell芯片的8个协处理器,拥有强大的并行能力,id的解决方案在SPU上进行了诸如骨骼动画、形变动画、顶点和索引缓存的压缩、Progressive Mesh的计算等诸多内容,同时与PPU上的物理计算RSX上的渲染工作交错进行,最大化的利用了PS3的硬件结构,最终的游戏产品《Rage》很快就会面世了!
最后是我的解决方案

特点是逻辑完全分离,无需同步,虽然成功的达到了文章开始提出的两个目标,但对于引擎的使用者必须考虑多线程的诸多问题,各种计算需放在哪个线程,如何在两个线程间交互,都需要深入思考,所以要应用到实际的游戏制作,恐怕还有很长的一段路要走。