腾讯大数据回答2019:鹅厂开源先锋,日均计算量超30万亿,全力打破数据墙
乾明 发自 腾讯汇
量子位 报道 | 公众号 QbitAI
开源,开源,开源。
这就是腾讯2019年技术领域最直观的变化。
最新代表事件,来自于腾讯首个开源的AI项目Angel,完成3.0版本进化后,得到全球技术专家认可,从开源基金会LF AI毕业,成为业内顶级AI开源项目。
这是中国首个得此认可的项目,消息传来自是引发好评热议。不过,这只是腾讯过去这一年开源成绩的注脚之一。

过去一年,腾讯开源势头愈发凶猛。截止12月份,对外开源项目超过92个,覆盖所有BG(事业群),微信、腾讯云、大数据、游戏、AI、安全等业务都在其中,累计获得超27万标星,赢得一片赞誉。
腾讯已然成为全球开源大厂之一。在这其中,腾讯大数据贡献不小。
腾讯业务的技术支撑方,腾讯大数据接连将自身核心组件开源,推动腾讯走向中国大数据领域开源最全面的厂商。
腾讯数据平台部总经理、AMS平台总经理、智慧零售战略合作部总经理蒋杰说,接下来将会持续推进,将整个大数据平台的所有东西全部开源。
为什么要如此“激进”开源?具体到业务中,他们发展如何?又有怎样的开源逻辑?
蒋杰对过去一年的总结回答,能够给出参考答案。

△ 蒋杰
作为腾讯开源先锋,腾讯大数据的回答,也传递着整个腾讯的开源策略与逻辑。所以鹅厂开源如何,不妨看下腾讯大数据。
开源底气:每日数据计算量超 30 万亿
2019年,是腾讯大数据平台成立的第十个年头,已经从零发展成为了整个集团业务的关键支撑:
每天有 1500 万的分析任务、30 万亿次的实时计算量,并且每天数据接入条数达 35 万亿条数据。基于腾讯云的分布式机器学习平台,能支撑 1 万亿维度的数据训练。
为什么能够做到这一点?来自于强大的技术实力。腾讯官方说法,经历10年发展,大数据平台已经建立起了“大数据 +AI”双引擎技术架构,立身于行业第一梯队。
尤其是核心项目之一腾讯第三代计算平台Angel,发展到3.0版本之后,已经能支持万亿维度数据,同样也可以兼容 Spark、PyTorch、TensorFlow 等生态,进一步降低了使用门槛,可扩大了兼容性。
虽然只需几句话,就能描述出系统概况,但想要打造这样一个系统,并不简单。

“整个过程中,你会遇到网卡的瓶颈,存储瓶颈,包括丢数据各种问题,”蒋杰说,“做系统是靠踩的一堆坑,有血的教训,一堆故障,才慢慢磨炼出来的。”
蒋杰解释称,对于腾讯这样体量的公司,也是如此。其开放出去的能力和技术,更是经历了很多考验。
原因也很简单,别人在你这踩坑了, 还会对你有信任感吗?“我们想要当领先者,但不是先烈,”蒋杰说。
如何做?他给出了一个关键词:“价值驱动”。
平台的发展不是闭门造车,而是跟着业务发展来发展,基于数据价值的驱动来演进。整个过程,是技术依赖于业务成长,技术回过头去反哺业务发展。
这也是腾讯大数据10年发展的路径。
从引进到自研再开源:腾讯大数据迎来转折点
从2009年开始,腾讯大数据平台经历离线计算、实时计算与机器学习三个阶段。
第一阶段,基于开源的Hadoop体系,离线计算平台,主要发力规模化。主要的业务导向是替代传统的数据仓库,做基于报表的服务。
这一阶段持续了3年,实现了从关系型数据库到自建大数据平台的全面迁移。
但到了2012年左右,移动互联网开始火爆起来,用户特征与用户画像方面的数据进一步丰富。
电商商品推荐,新闻的推荐等算法对数据平台提出了更高要求,第一阶段只有T+1的报表显然不够用,需要小时级、分钟级、秒级的实时监控。
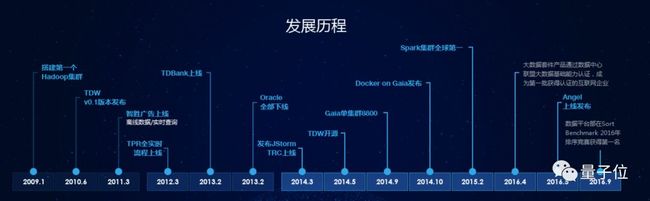
因此,原来的Hadoop转向Spark和Storm体系,在吸收开源技术的基础上,结合腾讯自身的需求进行重写,提供实时报表,实时查询、实时监控等支持。
并开始了探索流式计算、秒级采集系统的建设,构建企业级的实时数据分析体系。
这一阶段同样是持续了3年。蒋杰说,这一阶段完成后,腾讯大数据能力就已经位于国内第一梯队了。
到了2015年,数据量进一步增长,人群特征维度更多,广告推荐体系出现了一定的瓶颈。大数据平台向第三阶段发展,建设机器学习平台,支持腾讯各业务数据挖掘的需求。
并于2016年推出了自研机器学习平台Angel,专攻复杂计算场景,可进行大规模的数据训练,支撑内容推荐、广告推荐等AI应用场景,建立起了“大数据 +AI”双引擎技术架构。

整个过程中腾讯大数据提升了集群可扩展性,相对于原生调度器性能提升150倍,2016 年,腾讯打破 Sort Benchmark 四项世界纪录,标志着算力已经达到世界领先水平。
从业务中来,到业务中去,形成了腾讯大数据平台技术迭代的循环。
得益于开源,回馈于开源,是腾讯大数据甚至腾讯在技术社区中循环,也是其不断推动开源的驱动力之一。
全力打破数据墙,开源中向第四代大数据平台迭代
2019年,也是腾讯大数据平台第四代升级的元年。
蒋杰介绍称,腾讯正在研究以批流融合、ABC融合、以及数据湖和联邦学习为方向的下一代大数据平台的研究。
同样,这一平台的迭代也是来自于业务价值驱动——数据覆盖面更广更大,数据安全和隐私保护成为新的问题。
在物联网、云计算以及人工智能技术的推广应用下,平台需要具备混合部署、跨域数据共享和边缘计算等能力。
这背后也隐藏着大数据行业最大的障碍:数据墙。

“把数据共享出来,其实把自己的后背交给别人,谁也不愿意,这是最大的困难。”蒋杰说。
这也是环境使然,过去一年,数据泄露席卷各行各业,从金融保险、教育、医疗、科技到政府无一幸免,规模甚至达到十几亿。
另一方面,欧洲发布《通用数据保护条例》之后,整个行业对数据保护的重视度越来越高。
“不在共享情况下能够得到共享,联邦学习是一个方向。我们希望通过混合部署,漂移计算,加上整个联邦学习,构建严格的安全管控体系,打破这个数据墙。”
业务价值已经明确, 腾讯大数据平台也开始展开了行动。蒋杰表示,明年将会把联邦学习落实到场景中。与此同时,相关的研究成果也会同步开源出来。

鹅厂开源忙,大数据平台为先锋
所以腾讯为何开源?腾讯大数据的2019,能够给出部分答案:
首先,腾讯大数据早期发展得益于开源项目,从第一阶段的Hadoop到第二阶段的Spark等等,开源项目都提供了帮助。
其次,腾讯大数据在发展过程中,技术实力快速发展,技术实力能够拿出来,给更多的人使用,从而让社区不再重复造轮子踩坑。
这是具体业务层面上的考虑,但提高视角,放到整个腾讯甚至整个行业来说,又能得到不同角度的答案。
开源协同是腾讯当下最重要的技术战略之一。
对于腾讯来说,内部的开源协同,实际上是对最底层和共性技术能力的一次梳理和拉通,一方面是减少重复造轮子,另一方面提升公司的研发效能和运营效率。
在内部协同共建的基础上,腾讯在推动更底层、更重磅的技术对外开放,不断完善开源治理,打造开发者共建的生态。

2019年,由腾讯大数据主导的协同小组Oteam,共建了一个名为“天穹”的大数据项目,将腾讯六大事业群的大数据相关的系统做了统一,希望打造成一个具有统一技术栈的公司级大数据平台体系。
蒋杰介绍说:“一项开源的技术能够有良好的发展,常常需要背靠一个强大的公司,具有一定的经济实力和良好的业务发展。腾讯有强大的业务支撑,这使得我们能够去投入研发最好的技术,走在行业的最前沿。
目前,腾讯内部已协同的项目横跨了各个技术领域,经过海量用户验证。腾讯正在源源不断向开源社区输出优质开源项目。
今年8月份,马化腾首次对外谈起腾讯开源,进一步表明了腾讯对待开源的态度:
腾讯希望在科研领域投入更多力量,把“科技向善”纳入公司新的使命与愿景。我们将通过内外部开放源代码等方式,积极参与“全球科技共同体”的共建。

当然,对于腾讯来说,开源也是战略的体现,不仅仅在于“科技向善”愿景的落实,更有布局产业互联网的考虑。
通过有价值的开源项目,会吸引更多的用户加入腾讯生态,推动机器学习和人工智能的广泛应用。
腾讯开源也在与腾讯云紧密结合,为开发者提供更多便利的基础服务、工具和开源项目。
目前,腾讯已经把网络、存储、数据库等IaaS能力,大数据、机器学习等PaaS的能力,以及上层的图像、语音、NLP、BI等SaaS能力,通过腾讯云对外开放。
小争争事,大争争势,起于2010年的腾讯开放战略,在2020年到来之时,也变得愈发成熟,腾讯的格局也变得越来越大。
— 完 —
AI内参|把握AI发展新机遇
拓展优质人脉,获取最新AI资讯&论文教程,欢迎加入AI内参社群一起学习~

跟大咖交流 | 进入AI社群


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !