【记录】图像语义分割网络,FCN-SegNet-Unet-Enet-LinkNet-DenseNet~~~~
注:只为记录,知道网络架构
图像语义分割网络
- 1. FCN
- 2.SegNet
- 3.Unet
- 4.Enet
- 5. LinkNet
- 6.DenseNet
- 7.PixelNet
- 8.ICNet
- 9.RefineNet
- 10.PSPNet
- 11.HDC-DUC
- 12.ShelfNet和LadderNet
- 13.DANet
- 14.BiseNet
- 15. ESPNet
- 16.DenseASPP
- 17.Fast-SCNN
1. FCN
Paper:
Fully Convolutional Networks for Semantic Segmentation
网络:
FCN作为把深度学习应用于图像语义分割的开山之作,斩获CVPR2015的最佳论文。
网络图如下所示:
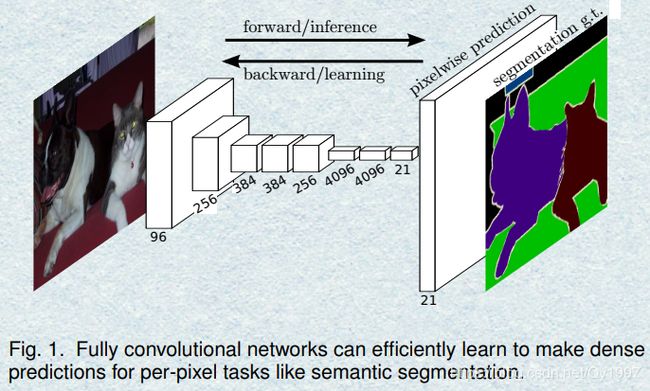
把一般用于分类网络的最后一层全连接层替换成卷积层,从而形成整个全卷积网络(Fully Convolutional Networks)。整个网络有三个要点:
- 卷积层(Convolution):用于特征提取。
- 上采样(Upsampling):FCN中的上采样选择的是反卷积操作(Deconvolution)
- 跳连层(Skip layer fusion):由于直接将最后一层进行上采样比较粗糙,会丢失大量信息,所以将前面比较lower的feature-map与最后的输出进行融合(在FCN中,fusion采用的是逐像素相加)。所以,出于对选取feature-map的不同产生了FCN-32S,FCN-16S,FCN-8S。如下图所示:
FCN整个网络还是比较清晰的,作为开山之作,本篇的内容也由此展开!
2.SegNet
Paper:
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
网络:
SegNet是语义分割中一种Encoder-Decoder模型的网络,网络图如下所示:

编码器(Encoder)部分有13个卷积层,与之相对应的解码器(Decoder)也有13个卷积层,整个流程就是卷积->下采样->->->上采样->卷积->->然后将最后一层的输出作为输入放入一个softmax-classifier(分类器),最终输出一个K(class的数量)个channel的概率图,从而得到分割图像。
- 值得一提的是SegNet在下采样池化的过程中记住了Pooling的位置信息,从而在进行上采样池化时即使不需要进行学习也能保留大量信息。下图描述了SegNet与FCN上采样的区别。
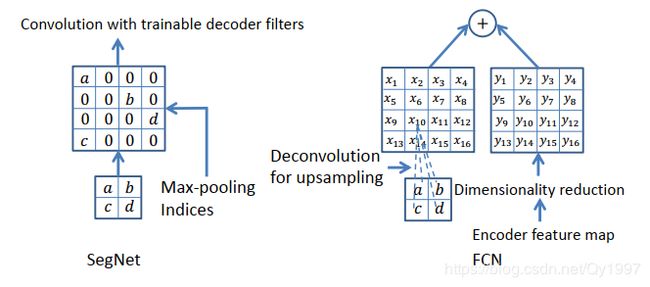
pytorch直接提供了这个pooling Indices的接口
#Encoder部分的下采样,x_01,x_10d为上一个卷积层的输出
import torch.nn.functional as F
x_0, indices_0 = F.max_pool2d(x_01, kernel_size=2, stride=2, return_indices=True)
#Decoder部分的上采样
x_0d = F.max_unpool2d(x_10d, indices_0, kernel_size=2, stride=2, output_size=dim_0)
3.Unet
Paper:
U-Net: Convolutional Networks for Biomedical Image Segmentation
网络
Unet是图像语义分割中的一个经典的网络,也是一个典型的Encoder-Decoder模型,因其网络模型呈现一个U字形而得名,其网络如下图所示: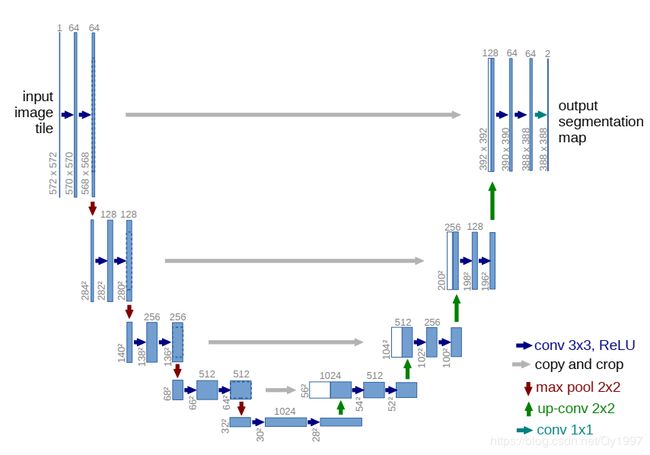
根据网络图来看,整个架构还是很intuitive的,Encoder部分不断地进行卷积,下采样,然后Decoder部分进行卷积上采样。要注意的是在Decoder部分采用了一个跳连结构(Skip connection),这与FCN的Skip layer fusion有些类似。Unet将Encoder部分对应的low-level的feature-map与Decoder部分的feature-map相加然后进行卷积,这里的相加采用的concatenate,就是堆积木一样叠在一起。
Unet-family
Unet发表于2015的MICCAI,在医学图像领域有着卓越的表现。在Unet的基础上,大量学者及研究人员开发出了各种Unet的变体形式,如U-Net, R2U-Net, Attention U-Net, Attention R2U-Net,后续可能会记录部分Unet的变体。Github上有一个Unet-family的项目罗列了各种Unet
Unet-family
4.Enet
Paper:
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
网络:
Enet是一种实时(也就是速度快)的语义分割网络,它的网络组成如下表显示(论文中没有结构图,QAQ我也比较懒就不画了…)
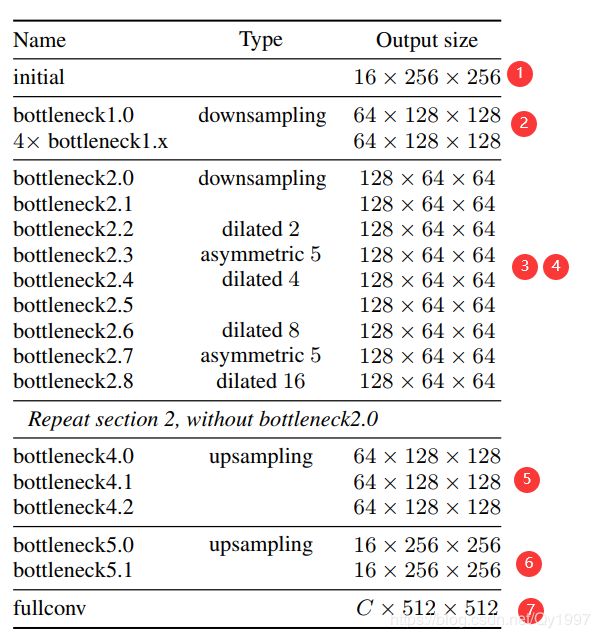
整个网络由七个部分组成,主要是由两个模块initial block和bottleneck module组成。下面先介绍这两个模块。
- initial block
initial block的组成很简单,如下图所示,就是将input分别经过一3x3,stride=2的卷积以及一个MaxPooling,然后连接起来,这里的卷积操作所用的filter个书为13,再加上MaxPooling的三个通道,就是得到16个channel的输出,与网络表中的Section 1也对应上了。

- bottleneck module
bottleneck module借鉴了ResNet的residual block,如下图所示
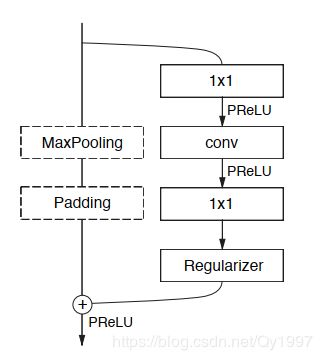
得到输入之后,有两个分支,一个分支直接做MaxPooling,另一个分支做convolution,这里采用了两个1*1的卷积块分别用来压缩和扩展通道数,目的是减少计算量,中间的卷积层可采用普通卷积,膨胀卷积(dilated convolution)或者非对称卷积(asymmetric convolution)。
再回到网络表看整个网络,首先经过Section 1的初始化模块,然后经过Section 2的下采样,接着进入Section 3的下采样,Section 3中的每个卷积层采用不同的卷积操作,然后重复Section 3 即进行Section 4,注意在Section 4中丢弃了bottleneck module2.0,即不再下采样,这就完成了Encoder部分,接着进入Decoder部分Section 5 和Section 6。论文中提到,在Section 6的上采样过程中不使用pooling indices,其原因是,第一次下采样是卷积和pooling同时进行的。最后经过一个full conv得到输出。
作者在论文中阐述了一些网络设计的细节,我在这里就不做赘述了,有兴趣的同学可以去看一下。
5. LinkNet
Paper:
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation
网络:
“Unlike existing neural network architectures which are being used for segmentation, our novelty lies in the way we link each encoder with decoder.”LinkNet的创新点是将Encoder部分与Decoder部分的feature-map融合起来。网络结构如下图所示:
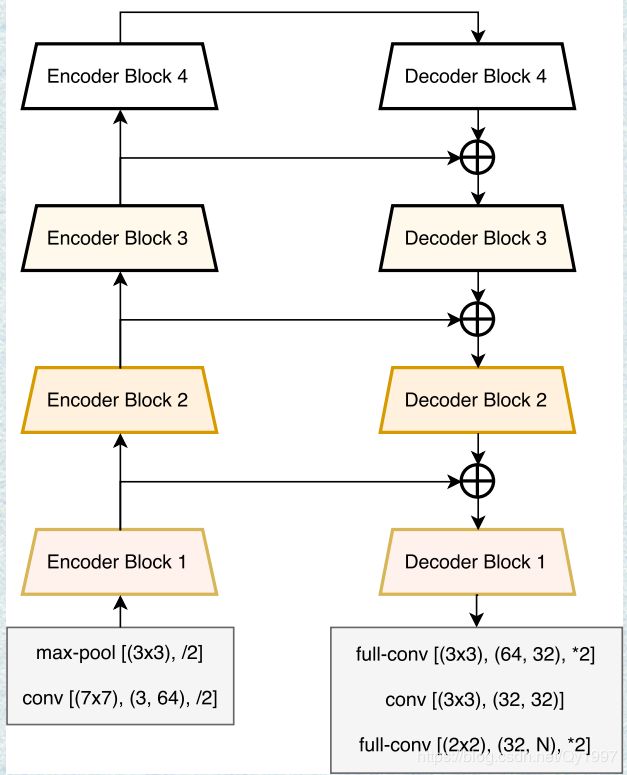
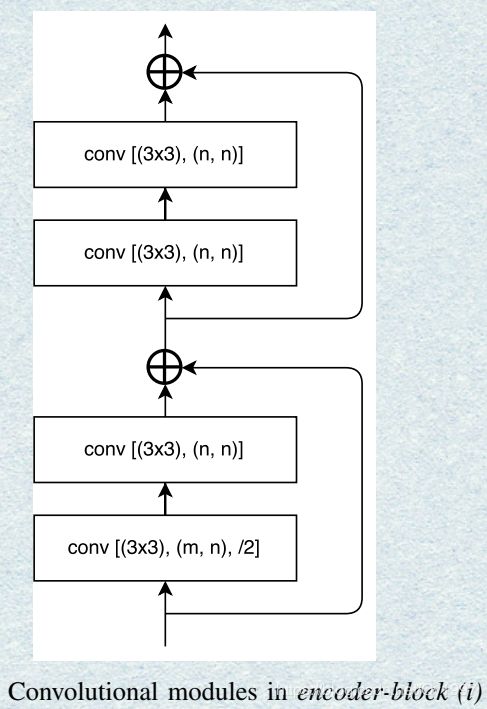
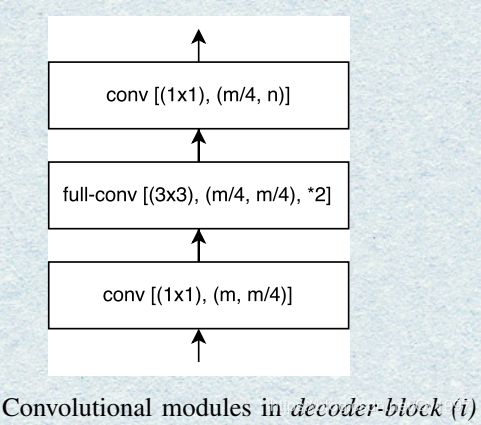
正如图中所看到的,解码的时候将Encoder部分的feature-map加进来然后输入下一个Decoder Block。其中的Encoder Block和Decoder Block分别如下图所示:
6.DenseNet
Paper:
Densely Connected Convolutional Networks
网络:
DenseNet有着与ResNet类似的结构,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过逐像素相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起。如下图所示
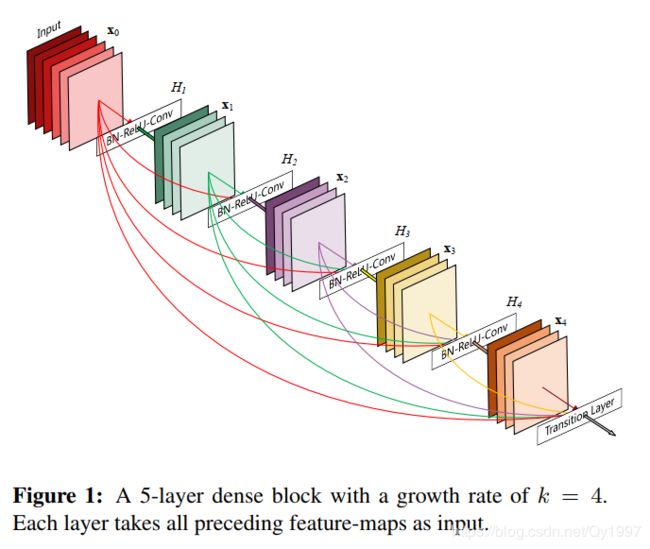
下面根据论文来讲讲一些细节
- Dense connectivity:将每一层的feature-map都直接连接到后面的所有层中 x l = H l ( [ x 0 , x 1 , . . . , x ( l − 1 ) ] ) x_l=H_l([x_0,x_1,...,x_(l-1)]) xl=Hl([x0,x1,...,x(l−1)])
- Composite function:论文中把 H l ( . ) H_l(.) Hl(.)定义为三个连续的操作:BN(Batch Normalization)层,Relu层和一个3x3的卷积层。
- Pooling layers:因为前面的block产生feature-map在尺寸上会与后面的feature-map不同,所以在连接之前要做进行池化。论文中把这一步称为transition layers,包括一个BN层,1x1的卷积层和2x2的平均池化(average pooling layer)。
- Growth rate:如果每一个 H l ( . ) H_l(.) Hl(.)会产生 k k k个feature-maps,那么第 l l l层就会有 k 0 + k ∗ ( l − 1 ) k_0+k*(l-1) k0+k∗(l−1)个feature-maps作为输入,其中 k 0 k_0 k0是最开始的输入通道数。把 k k k这个超参数称为网络的Growth rate
- Bottleneck layers在每3×3卷积之前可以引入1×1卷积作为瓶颈层,以减少输入特征映射的数量,从而提高计算效率。这种设计对于DenseNet也有效,并将具有瓶颈层的网络称为DenseNet-B,即具有BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3)版本的 H l H_l Hl
7.PixelNet
Paper:
PixelNet: Towards a General Pixel-Level Architecture
网络
这篇论文没太看懂,但其核心思想在论文中是这么说的:作者通过实验论证了只需对每个图像采样一小部分的像素就足以进行学习,这是因为像素之间的空间相关性。这种采样也使得我们可以探索几种用于提高基于FCN的架构的效率和性能的方法。
论文中的结构图如下

看结构图好像还挺简单明了的,但是代码实现上有点搞不懂怎么处理的,论文中也没给代码…我太菜了。
(有机会再来看看这篇论文吧 /捂脸/捂脸/捂脸/)
8.ICNet
Paper:
ICNet for Real-Time Semantic Segmentationon High-Resolution Images
网络
ICNet是针对高分辨率图像的实时语义分割网络,其网络结构图如下
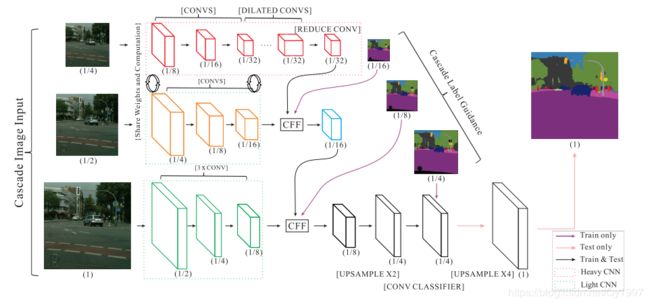
- ICNet利用的多尺度的图片输入,分别为大,中,小的图片,逐级递减1/2。每一层可以看作是一个单独的语义分割任务
- 在第一层与第二层,也就是小中两层的权重是共享的以减少参数。
- 可以看到在第二层第三层有个CFF模块,来接收上一层的输出以及一个大小相同的label进行loss的计算,作为一个Guidence来更好地提取特征。在第三层的后面也有一个类似的操作,不过不再需要额外的featur-map输入。需要注意的是这些操作只在训练时进行。
- 在测试时,会有最后一步的4倍的上采样来输出与原图大小相同的预测图。
下面介绍CFF模块:
Cascade Feature Fusion:
内部结构图如下
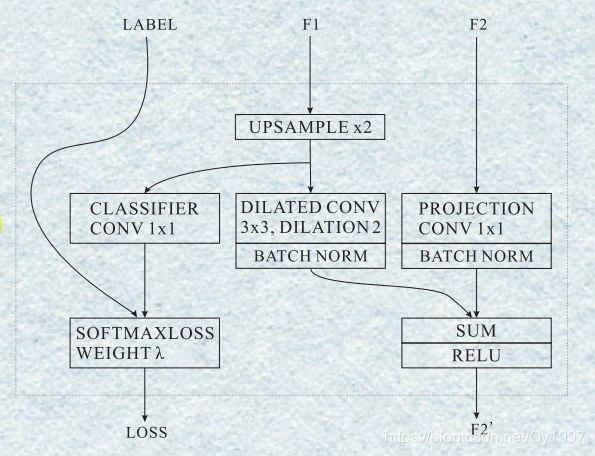
F1是来自上一层输出的feature-map,F2是这一层前面卷积得到的feature-map,根据前面的网络图可以看到F1是比F2的尺寸要小的,所以要先通过一个双线性插值进行上采样,然后经过卷积层,BN层与F2相加,在此之前,要先将F2用一个1x1的卷积使得channel与F1相同。最终输出F2’。另外有一个分支是将上采样的F1与Label作loss,相当于一个监督作用,来加强F1的表征。
9.RefineNet
Paper:
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
网络
RefineNet是一个用于高分辨率图像的分割模型,我觉得也只能用于高分辨率,因为小图根本无法支持那么多下采样= =。
网络结构如下图所示
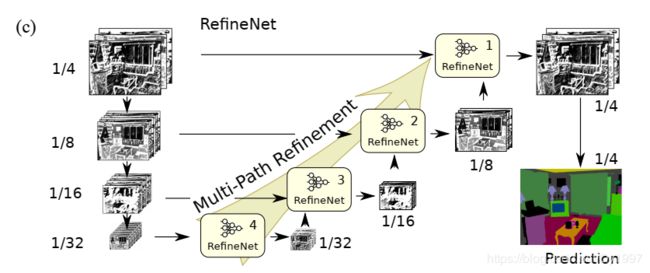
一开始就有四个路径,每个路径分辨率逐渐降低,并且每条路径都有一个RefineNet。低层次的RefineNet输出特征图加入到上一层中。
下面给出RefineNet的具体内部结构图

可以看到在每一个RefineNet内部又有多尺度- -。所以说低分辨率的图根本禁不住这么多下采样
如图所示RefineNet主要由三个模块组成,下面依次介绍这三个模块:
- Residual convolution unit:是个简化版的ResNet Block,如图中所示,只有ReLU和Conv,移除了BN层。对于每一个输入,filter的数量在RefineNet-4,也就是最底部的RefineNet是512,其他RefineNet的filter数量为256
- Multi-resolution fusion:来自RCU的输入都会先做一个自适应的卷积,然后上采样,使得每一个输入的维度相同,然后进行逐元素的相加。
- Chained residual pooling:来自最前方的输入不断地进行池化、卷积然后以元素相加的形式跳连到后面的feature-map上
10.PSPNet
Paper:
Pyramid Scene Parsing Network
网络
整个网络一目了然,首先经过一个CNN得到feature-map,然后进行不同尺度的pooling,PSPNet的亮点就在于这个Pyramid Pooling Module,此后的很多网络都采用或这借鉴了这个模块,它将此前的feature-map进行不同尺度的池化,以不同(更大)的感受野获得context information,然后进行卷积。论文中分别采用了1x1,2x2,3x3,6x6四个level的feature-map。然后与先前的feature-map 融合之后再进行卷积得到Prediction。
11.HDC-DUC
Paper
Understanding Convolution for Semantic Segmentation
网络结构
如图所示
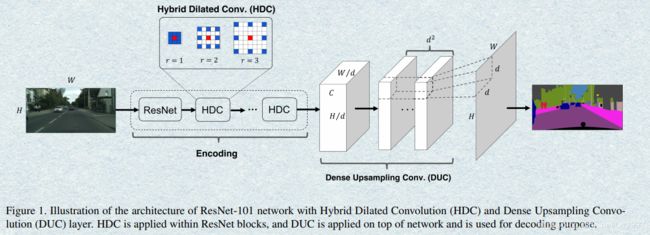
Encoder部分用多次不同rate的膨胀卷积。
Decoder部分:标准的双线性插值是没有参数需要学习的,对于像素级的分割任务,会造成部分细节信息丢失。DUC模块则是将最后的Prediction分成 d 2 d^2 d2个通道去学习。假如原始图像大小为 H ∗ W H*W H∗W,卷积之后变为 H / d ∗ W / d H/d*W/d H/d∗W/d,用 h ∗ w h*w h∗w代替,具体为:先将原先的 h ∗ w ∗ c h∗w∗c h∗w∗c变成 h ∗ w ∗ ( d 2 ∗ L ) h∗w∗(d^2∗L) h∗w∗(d2∗L),L为分割的类别数目,将此后的输出reshape为 H ∗ W ∗ L H∗W∗L H∗W∗L,以此引入多个学习的参数,提升对细节的分割效果。
12.ShelfNet和LadderNet
前后隔了一段阅读这两篇论文,发现网络结构惊人的相似,思路大致都是在不同大小的feature上进行多次的卷积。然后看了下两篇论文的作者,果不其然,是同一个人。
Paper:
LadderNet: Multi-path networks based on U-Net for medical image segmentation
ShelfNet for Fast Semantic Segmentation
网络结构
LadderNet如下图所示

ShelfNet结构如下图所示
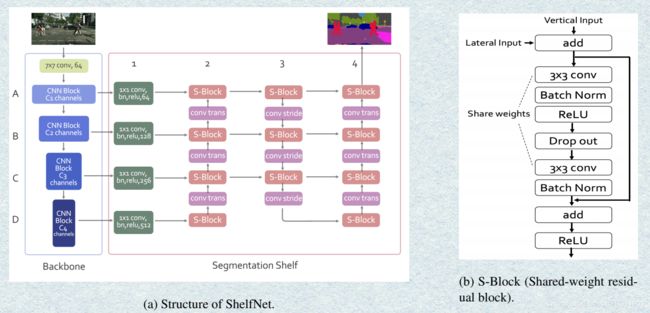
可以看到两个结构的pipeline是及其相似的,区别在于LadderNet是以Unet的结构为基础的。两个网络都用了一个S-Block虽然在LadderNet中没有命名,但结构是一样的,即在residual block的基础上加了个参数共享。
13.DANet
Paper:
Dual Attention Network for Scene Segmentation
网络结构
网络如下图所示

DANet是一个全景分割网络,引入了自注意力机制,分为两个分支。这也是这篇论文的重点所在。看网络图还是很直观的,选取ResNet作为backbone,然后分别经过一个Position Attention Module和Channel Attention Module,最后做一个fusion然后得到Prediction。
下面就主要介绍一下Position Attention Module个Channel Attention Module
- Position Attention Module
大体结构如下图
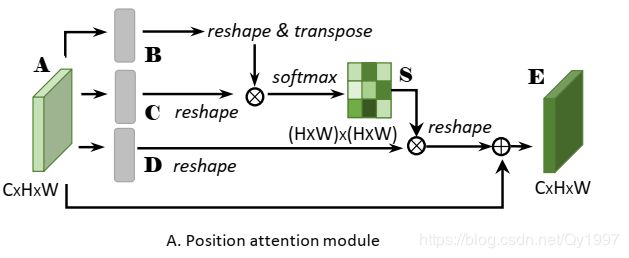
首先得到前面Backbone输出的local feature A ( C ∗ H ∗ W ) A(C*H*W) A(C∗H∗W),然后把 A A A进行卷积得到两个相同大小的 B B B和 C C C,对 B B B和 C C C进行reshape之后的维度是 C ∗ N C*N C∗N,其中 N = H ∗ W N=H*W N=H∗W,然后把 B B B和 C C C进行矩阵相乘,得到的结果还要做一个softmax
,这样就得到了一个spatial attention map S ( N ∗ N ) S(N*N) S(N∗N)。可以用下面的公式来表达
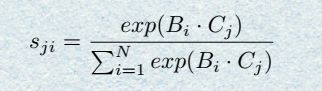
在进行以上操作的同时, A A A还会经过一个分支进行卷积得到 D ( C ∗ H ∗ W ) D(C*H*W) D(C∗H∗W),同样reshape成 C ∗ N C*N C∗N然后跟 S S S的转置进行矩阵相乘,把得到的结果reshape成 C ∗ H ∗ W C*H*W C∗H∗W,最后乘上一个系数α并与原来的feature A A A相加。用公式表达为
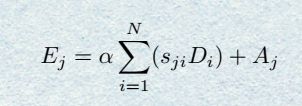
- Channel Attention Module
大体结构如下图所示
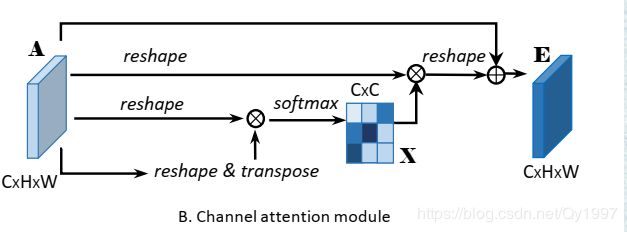
还是由Backbone得到的feature A ( C ∗ H ∗ W ) A(C*H*W) A(C∗H∗W)开始,先把 A A Areshape成 C ∗ H C*H C∗H,然后得到attention map X = A ∗ A T X=A*A^T X=A∗AT, X X X维度为 C ∗ C C*C C∗C,同样的在经过一个softmax层,可以用公式表示为
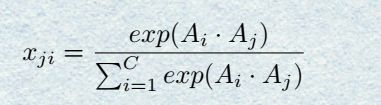
类似的,对 X X X的转置和A进行矩阵相乘,再把结果reshape成 C ∗ H ∗ W C*H*W C∗H∗W,最后乘上一个系数β再最初的feature A A A相加得到output E E E。
最后将两个module的输出相加就完事了。
14.BiseNet
Paper:
BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
网络结构
BiseNet考虑到spatial information和context information,通过提取这种两种特征,然后融合,平衡了速度与精度,得到了更好的分割效果。
网络图如下:
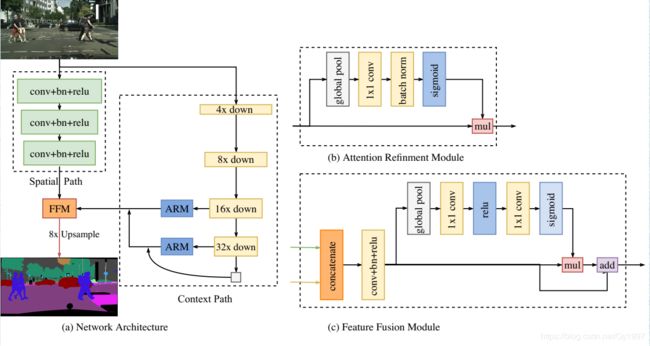
如图所示,整个网络分为两部分,Spatial path和Context path,Context path中有个Attention Refinement Module,最后有个Feature Fusion Module来融合两部分的信息。下面分别介绍各个组件。
- Spatial path
Spatial path有三层网络,每一层为步长为2的卷积+batch normalization+ReLu输出的feature-map尺寸下采样为原来的1/8 - Context path
Context path先是利用轻量级网络来实现快速下采样,论文中采用的是Xception,可以看到Context path尾部有两个Attention Refinement Module - Attention Refinement Module
Attention Refinement Module组成很简单,将上层的feature-map先做global pooling,然后经过一个1x1卷积,紧跟着一个Batch Normalization和Sigmoid,得到结果再与下一层的feature-map相乘即可 - Feature Fusion Module
Feature Fusion Module是用来融合Spatial path和Context path的特征,考虑到两个feature-map是不同level的,不能简单的直接融合,所以先将两个feature-map进行 concatenate,然后经过一层卷积,通过batch normalization来平衡尺度差异。记此时的feature-map为 A A A, A A A要先经过global pooling+1x1conv+relu+1x1conv+sigmoid得到 A 1 A_1 A1, A 1 A_1 A1再与 A A A相加得到最终的输出。
15. ESPNet
Paper:
ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
网络结构
ESPNet是轻量级网络中的佼佼者,充分利用了膨胀卷积,其核心为efficient spatial pyramid (ESP) module
主要分析下这个ESPmodule

假设输入的feature-map尺寸为 M ∗ W ∗ H ∗ M M*W*H*M M∗W∗H∗M,首先经过一个1x1卷积降维成 M ∗ W ∗ H ∗ N M*W*H*N M∗W∗H∗N,然后分成K个path进行膨胀卷积,每个path的卷积核个数为 M / N M/N M/N,且每个path的dilation rate是不同,形成一种金字塔结构,然后再将每个path的输出以上图所示的方式进行Sum Conact。
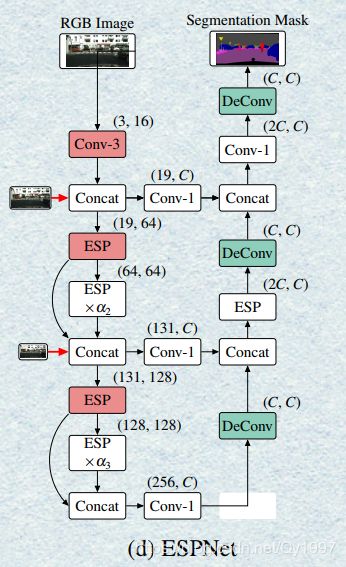
ESPNet中还结合了多尺度的输入,并且encoder层与对应的decoder层用通过卷积相结合。
16.DenseASPP
Paper:
DenseASPP for Semantic Segmentation in Street Scenes
网络结构
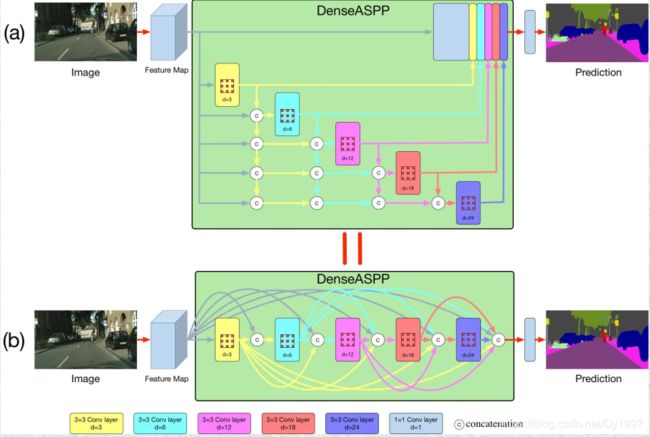
DenseNet+ASPP…就不多说了,一目了然。
17.Fast-SCNN
Paper:
Fast-SCNN: Fast Semantic Segmentation Network
网络结构
网络图如下:
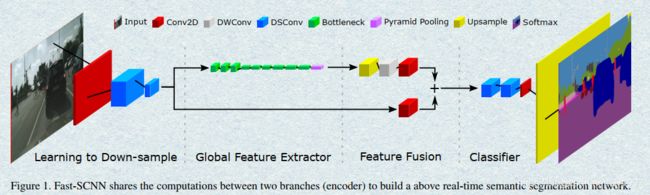
这篇论文中的图真是一言难尽…属实有点丑。可以看到这篇论文的思想也是两个branch,一个Spatial information和一个Context information,网络中的卷积绝大多数都采用了depthwise separable convolution,从而提高了速度。
在Global Feature Extractor最后还采用了Pyramid Pooling来汇总基于不同区域的Context information。
这篇文章就到这里吧,其实还有很多网络没写,像经典的deeplab系列,Unet的一些变体啥的,那些准备另起炉灶了。其实写到这里可以感受到网络设计的技巧就那么些,当然,有些文章还是比较亮眼的。