python简单爬虫实例3之猫眼网top100抓取特定内容(一个页面)
实例2主要讲述一个抓取过程中可能会遇到的问题,也是非常基础的问题,类似的问题还有许多,以后也会逐步介绍。
在实例一的基础上,我们使用BeautifulSoup解析html,并从中抓取我们需要的数据。
BeautifulSoup的安装:
首先,进入项目所在的python环境。
这里外推荐使用Anacoda进行安装python环境。
再命令行中输入:
pip install beautifulsoup4提示:Successfully installed beautifulsoup4-4.7.1 soupsieve-1.8即说明安装成功。
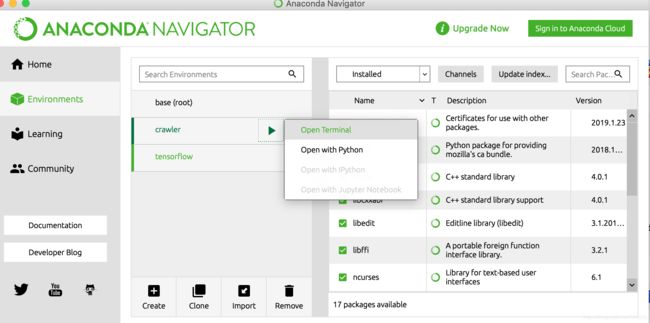
注意:如果安装后,使用时发现提示未引入,可能是环境不对,以上图为例,我的电脑上总共有三个环境base、 crawler、tensorflow,每个环境都安装了不同的库,可能是安装的环境和使用的环境不是同一个。
抓取网站的分析:
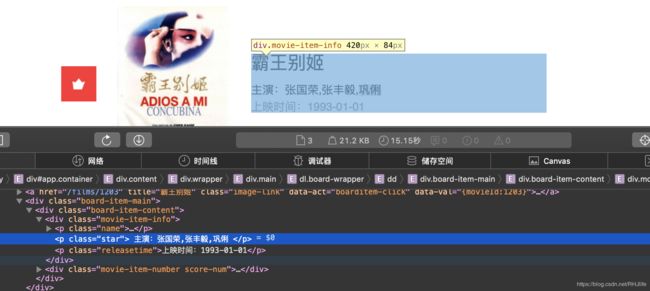
通过对网页前端代码的查看,我们可以清楚的看到需要提取内容的class属性
整理后如下:电影名->class="name"
主演->class="star"
上映日期->class="releasetime"
评分整数部分->class="integer"
评分小数部分->class="fraction"
代码如下:
from bs4 import BeautifulSoup
from urllib.request import urlopen
def get_one_page(x):
#字符串的格式化处理: {}占位符表示未知的参数,后面会补上
url = 'https://maoyan.com/board/4?offset={}'.format(x*10)
#第二种方法:url = 'https://maoyan.com/board/4?offset=%d'%(x*10)
response = urlopen(url)
return (response.read().decode())
html = get_one_page(0)
soup = BeautifulSoup(html,'html.parser')
#使用select定位
class_name = soup.select('.name')
class_star = soup.select('.star')
class_releasetime = soup.select('.releasetime')
class_integer = soup.select('.integer')
class_fraction = soup.select('.fraction')
#print(class_name,class_star,class_releasetime,class_integer,class_fraction)
for a,b,c,d,e in zip(class_name,class_star,class_releasetime,class_integer,class_fraction):
# 使用get_text()获取内容
print(a.get_text())
print(b.get_text().strip())
print(c.get_text())
print(d.get_text(),end='')
print(e.get_text().strip())
print()这样就将所需内容提取出来了,输出过程中有去除空格的操作。