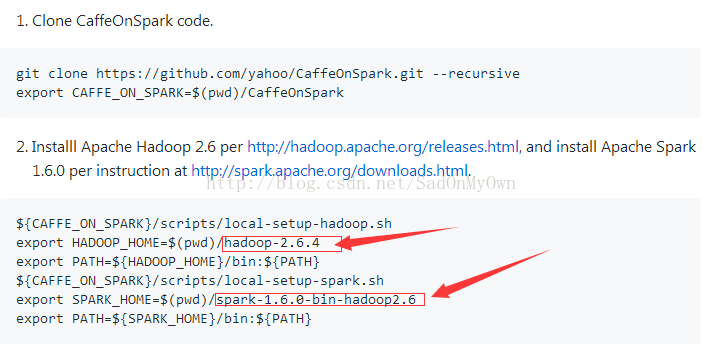
CaffeOnSpark安装和使用教程系列一:CaffeOnSpark的安装
由于实习公司的任务要求,需要学习CaffeOnSpark的安装和使用,作为一个对DL学习不到一个月的小白,拿到这个任务的时候真的是一脸懵逼,没招只能上网找教程。可能这个技术比较新,网上的教程比较少,比较详细的一个是:
参考教程。这个教程对于有一定深度学习基础的朋友来说应该足够了,但像我这样入门级的菜鸟,中间会掉一个又一个的坑。通过半个多月的掉坑、爬坑的痛哭煎熬过程,终于完成了CaffeOnSpark的安装和测试案例的使用。废话不多说,直接上干货!
说明:本教程默认hadoop和spark集群已经搭建完成,由于网上关于搭建hadoop集群和spark集群的教程很多,在此就不过多介绍具体的搭建过程。
1、更新源
sudo apt-get update
2、下载CaffeOnSpark
确保服务器中已经安装git,如果没有,执行如下命令:
sudo apt-get install git
下载CaffeOnSpark:
sudo git clone https://github.com/yahoo/CaffeOnSpark.git --recursive
3、安装maven
(1)确保已经安装好jdk
(2)下载apache-maven-3.2.5-bin.tar.gz
(3)解压
tar -zxvf apache-maven-3.2.5-bin.tar.gz
(4)修改环境变量
sudo vim /etc/profile
在末尾添加:
export M2_HOME=/home/master/software/apache-maven-3.2.5
export PATH=$M2_HOME/bin:$PATH
使环境变量生效
source /etc/profile
(5)检测是否安装成功
mvn -v
如果出现如下结果表示安装成功:

4、安装Caffe
(1)安装依赖包
sudo apt-get install libprotobuf-dev protobuf-compiler
sudo apt-get install libleveldb-dev
sudo apt-get install libsnappy-dev
sudo apt-get install libopencv-dev
sudo apt-get install libhdf5-serial-dev
sudo apt-get install --no-install-recommends libboost-all-dev
sudo apt-get install libatlas-base-dev
sudo apt-get install python-dev
sudo apt-get install libgflags-dev
sudo apt-get install libgoogle-glog-dev
sudo apt-get install liblmdb-dev
(2)下载Caffe
git clone https://github.com/bvlc/caffe.git
(3)修改Caffe中的Makefile.config,打开CPU_ONLY选项:
cd caffe/
mv Makefile.config.example Makefile.config
vim Makefile.config
去掉CUP_ONLY :=1前边的“#”
(4)编译Caffe
make all
4、修改CaffeOnSpark中caffe-public下的Makefile.config配置文件:
cd CaffeOnSpark/caffe-public
sudo mv Makefile.config.example Makefile.config
sudo vim Makefile.config
去掉CUP_ONLY :=1前边的“#”

在配置文件中添加:
![]()
INCLUDE_DIRS +=${JAVA_HOME}/include
5、编译CaffeOnSpark
在CaffeOnSpark的主目录下执行命令:
sudo make build
使用sudo为了保证编译过程中对系统访问的权限,但是最好之前先运行:
alias sudo=”sudo env PATH=$PATH”
注:因为系统预装的sudo在编译时缺省使用了--with-secure-path参数,因此当前用户使用sudo时,之前设置的环境变量$PATH会被覆盖。通过添加上面那行别名设置,就会在执行sudo时把当前的$PATH的值再套用上,达到想要的效果。
出现下述信息,则表示编译成功:
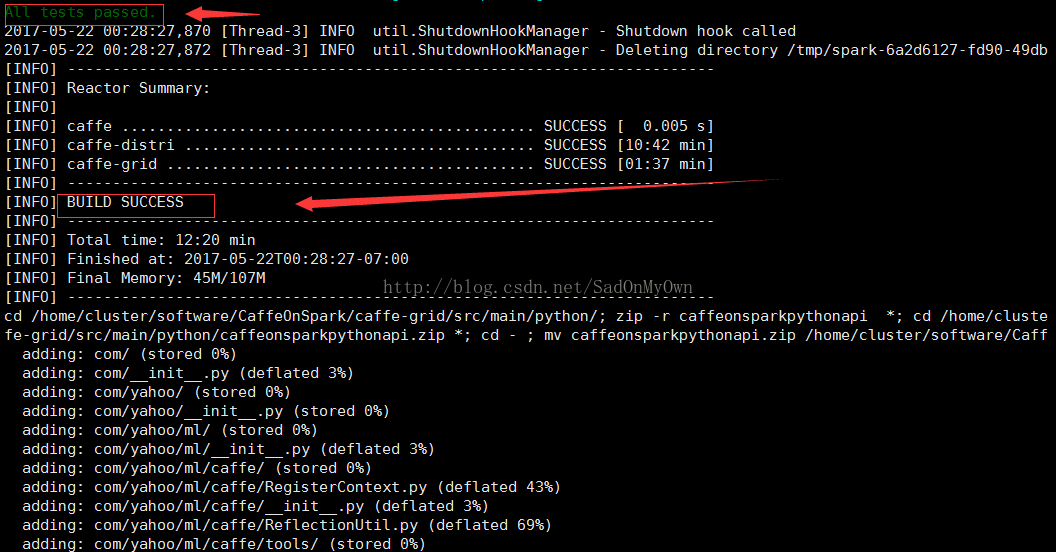
注:1、判断编译成功有两个标志:一是比较在输出信息中明显的看到BUILD SUCCESS;二是在控制台看到All tests passed信息输出。由于在CaffeOnSpark编译过程中会自动进行测试,有“All tests passed”信息输出,表示通过了所有的测试案例。
2、在编译过程中需要下载很多东西,需要较长的时间。如果网络不好的话,可能出现编译出错的提示,可以等到网络稳定了在make build一次。
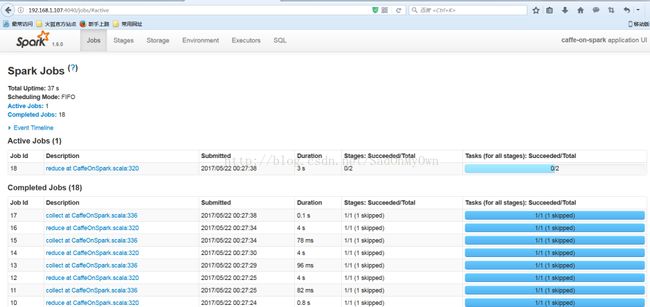
在编译过程中会进行测试,可通过Spark集群的master:4040web页面查看测试案例的执行情况:
注:1、在编译CaffeOnSpark时,若出现如下错误:

解决办法:
sudo apt-get install python-numpy
2、在编译CaffeOnSpark时,出现:
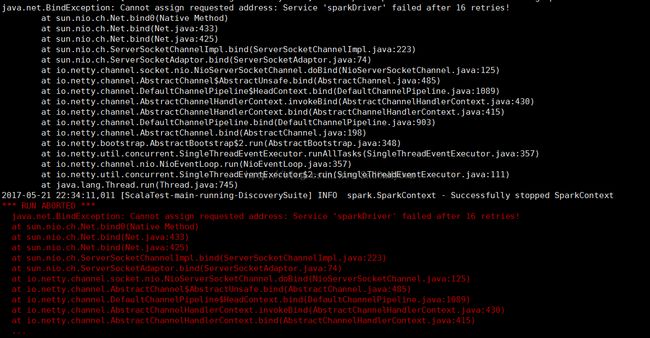
产生原因:没有指定Spark集群的Master节点IP
解决办法:在Spark的conf目录下修改spark-env.sh配置文件:
添加:
export SPARK_MASTER_IP=192.168.1.107
3、在编译CaffeOnSpark时,出现如下错误(比较重要的问题,若在编译过程中不解决,在随后使用过程中也会出现类似问题):
ERROR: testTrain (__main__.PythonApiTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/master/CaffeOnSpark/caffe-grid/src/test/python/PythonApiTest.py", line 28, in setUp
self.cos=CaffeOnSpark(sc)
File "/home/master/CaffeOnSpark/caffe-grid/target/caffeonsparkpythonapi.zip/com/yahoo/ml/caffe/CaffeOnSpark.py", line 25, in __init__
self.__dict__['caffeonspark']=wrapClass("com.yahoo.ml.caffe.CaffeOnSpark")
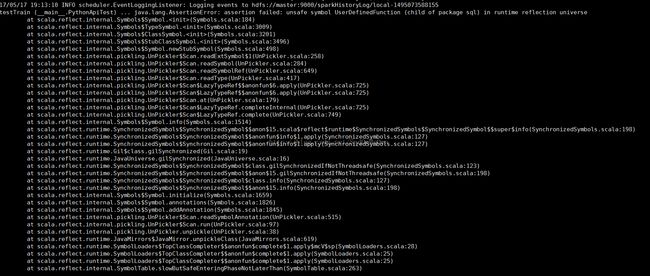
产生原因:从上边截取的部分错误信息记录可以看到出现的错误在com.yahoo.ml.caffe包下的CaffeOnSpark类中。在该类中需要调用Spark sql包中的UserDefinedFunction类的相关接口,但在Spark2.0的版本org.apache.spark.sql包已经没有UserDefinedFunction这个类。
解决办法:按照yahoo在Github上CaffeOnSpark的官方文档中的介绍更改hadoop和spark的版本,使用hadoop的版本为hadoop-2.6.4,spark的版本为spark-1.6.0。