大数据实战项目之新闻话题分析 学习笔记(八)
文章目录
- 第9章:Hbase分布式集群部署与设计
- 下载HBase版本并安装
- HBase分布式集群的相关配置
- HBase相关的服务介绍及启动测试
- 通过Shell进行数据表的操作测试
- HBase集群中Master-backup配置
- 根据业务需求创建表结构
- 第10章:Kafka分布式集群部署
- Kafka服务简介及版本下载安装
- Kafka分布式集群配置
- 启动Kafka依赖于Zookeeper的服务并进行测试
- Kafka分布式服务配置启动注意的地方
- 第11章:Flume用户行为数据采集准备
- Flume节点服务设计
- Flume版本下载安装
- Flume服务架构及配置说明
- Flume Agent-1采集节点服务配置
- Flume Agent-2采集节点服务配置
- 第12章:Flume+HBase+Kafka集成与开发
- Flume-3数据合并节点服务思路梳理
- 下载Flume源码并导入Idea开发工具
- 下载实验日志数据
- Flume与HBase集成配置
- 对日志数据进行格式处理
- 自定义SinkHBase程序设计与开发
- Idea中自定义SinkHBase程序编译打jar包
- Flume与kafka集成配置
- 第13章:数据采集/存储/分发完整流程测试
- 应用服务模拟程序开发
- 模拟程序Jar包上传与分发
- 编写运行模拟程序的shell脚本
- 编写Flume集群服务启动脚本
- 编写Kafka Consumer执行脚本
- 启动模拟程序服务并测试
- hdfs集群服务启动并测试
- Zookeeper集群服务启动并测试
- hdfs-HA启动并测试(一)
- HBase集群启动并测试
- kafka集群启动并整理topic
- kafka服务创建业务数据topic
- HBase中创建业务数据表
- Flume服务启动并解决出现的问题(一)
- Flume服务启动并解决出现的问题(二)
- 完成数据采集全流程测试
- 关于kafka集群中问题的解答
- 第14章:MySQL安装
- 配置MySql在线安装的yum源
- 在线安装mysql并启动服务测试
- 第15章:Hive集成HBase进行数据分析
- Hive概述
- Hive在Hadoop生态系统中的位置
- Hive架构设计
- Hive的优点及应用场景
- Hive版本下载及安装部署
- Hive与Mysql集成
- Hive服务启动与测试
- 根据业务需求创建Hive数据分析表结构
- Hive与HBase集成进行数据离线分析
第9章:Hbase分布式集群部署与设计
下载HBase版本并安装
总的版本选择

补充:
- 查看本地磁盘占用情况命令:df
HBase分布式集群的相关配置
1.HBase架构体系介绍
 备注:
备注:
红线——
- 数据还是存放在hdfs上的,所以有很强的可扩展性。
- 通过regionServer进行数据存放及数据表的管理(数据的region–数据很大时的数据分区)。 (类比于datanode–管理数据节点的)
- Master–管理整个regionserver服务的,类比于namenode。它接收来自regionServer的心跳反馈。
黑线——
- regionServer向Zookeeper注册状态
- 除了regionServer主动心跳反馈给Master,Master也可以从Zookeeper获取regionServer的状态
所以配置HBase服务之前要保证hdfs和Zookeeper服务是ok的。
2.HBase配置
1)hbase-env.sh
export JAVA_HOME=……
export HBASE_MANAGES_ZK=false #禁用自带的Zookeeper
2)hbase-site.xml

HBase相关的服务介绍及启动测试
- 启动:
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
通过Shell进行数据表的操作测试
连接hbase shell:
bin/hbase shell
建表
create tableName,familyName
插入数据
put ‘table1’,‘nicole’,‘info:username’,‘ynh’
浏览表
scan
删除表
drop表前需要先disable(禁用)表
 结果:
结果:


HBase集群中Master-backup配置
添加conf/backup-masters
启动hbase
查看端口:60010
根据业务需求创建表结构
- 从数据源下载数据:此处使用的搜狗实验室提供的数据
- 启动hbase shell:bin/hbase shell
- 创建表:
- create ‘weblogs’,‘info’
第10章:Kafka分布式集群部署
Kafka服务简介及版本下载安装
- kafka特点:
- 消息订阅&发布系统
- 实时处理数据
- 在分布式集群中存储流式数据
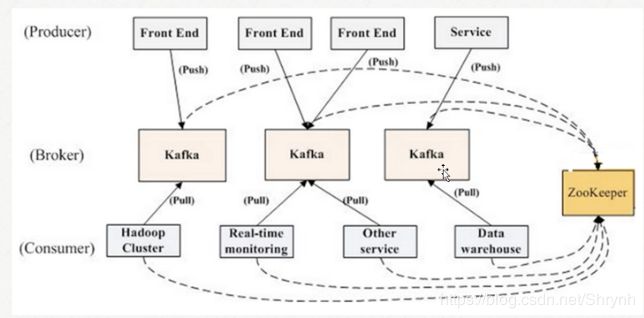
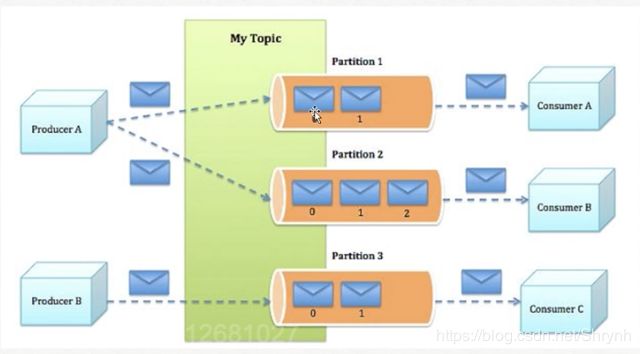
备注:
- kafka要依赖外部的Zookeeper服务。
- Broker注册:是分布式部署并且相互之间相互独立,但是需要有一个注册系统能够将整个集群中的Broker管理起来,此时就使用到了Zookeeper。在Zookeeper上会有一个专门用来进行Broker服务器列表记录的节点:
/brokers/ids - 管理topic的分区信息及与broker的对应关系:在Kafka中,同一个Topic的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与Broker的对应关系也都是由Zookeeper在维护,由专门的节点来记录,如:
/borkers/topics - 生产者负载均衡:由于同一个Topic消息会被分区并将其分布在多个Broker上,因此,生产者需要将消息合理地发送到这些分布式的Broker上,那么如何实现生产者的负载均衡,Kafka支持传统的四层负载均衡,也支持Zookeeper方式实现负载均衡。
- 消费者负载均衡:与生产者类似,Kafka中的消费者同样需要进行负载均衡来实现多个消费者合理地从对应的Broker服务器上接收消息,每个消费者分组包含若干消费者,每条消息都只会发送给分组中的一个消费者,不同的消费者分组消费自己特定的Topic下面的消息,互不干扰。
- 管理分区与消费者的关系:在Kafka中,规定了每个消息分区 只能被同组的一个消费者进行消费,因此,需要在 Zookeeper 上记录 消息分区 与 Consumer 之间的关系,每个消费者一旦确定了对一个消息分区的消费权力,需要将其Consumer ID 写入到 Zookeeper 对应消息分区的临时节点上,例如:
/consumers/[group_id]/owners/[topic]/[broker_id-partition_id] - 消息消费进度Offset记录
- 消费者Consumer注册
- Broker注册:是分布式部署并且相互之间相互独立,但是需要有一个注册系统能够将整个集群中的Broker管理起来,此时就使用到了Zookeeper。在Zookeeper上会有一个专门用来进行Broker服务器列表记录的节点:
Kafka分布式集群配置
1.解压安装包
2.server.properties配置
3.producer.properties配置
启动Kafka依赖于Zookeeper的服务并进行测试
步骤:
1.启动Zookeeper
bin/zkServer.sh start
2.启动kafka:
bin/kafka-server-start.sh config/server.properties
3.创建topic:
bin/kafka-topics.sh --create --zookeeper bigdata-pro01.ynh.com:2181,bigdata-pro02.ynh.com:2181,bigdata-pro03.ynh.com:2181 --replication-factor 1 --partition 1 --topic protest
4.查看创建的话题:(在zookeeper中查看,因为broker的topic是由Zookeeper进行管理)
启动Zookeeper客户端:
bin/zkCli.sh
在/brokers/topics中查看
![]()
5.生产者生产一个消息:
bin/kafka-console-producer.sh --broker-list bigdata-pro01.ynh.com:9092,bigdata-pro02.ynh.com:9092,bigdata-pro03.ynh.com:9092 --topic protest
6.启动一个consumer:
bin/kafka-console-consumer.sh --zookeeper bigdata-pro01.ynh.com:2181,bigdata-pro02.ynh.com:2181,bigdata-pro03.ynh.com:2181 --from-beginning --topic protest
实际结果测试:
机器2作为producer发布消息:
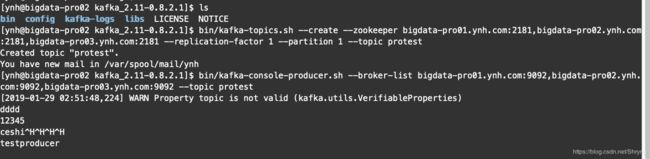 同时在机器2(clone session)上创建一个consumer实时获取消息
同时在机器2(clone session)上创建一个consumer实时获取消息

Kafka分布式服务配置启动注意的地方
- 在producer.properties配置中:broker-list:开启几台kafka服务器用于生产消息就可以写几台
第11章:Flume用户行为数据采集准备
Flume节点服务设计
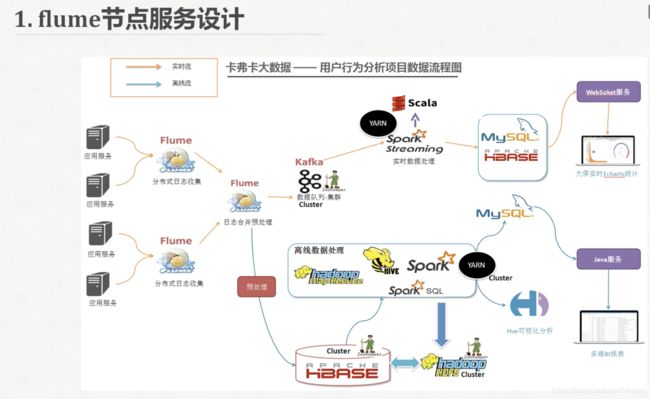 备注:
备注:
- 中间的Flume节点是很关键的,它会进行内容的合并分发,分为两方面:一是用于离线存储、而是给kafka进行实时处理。
Flume版本下载安装
Flume服务架构及配置说明
整体架构:
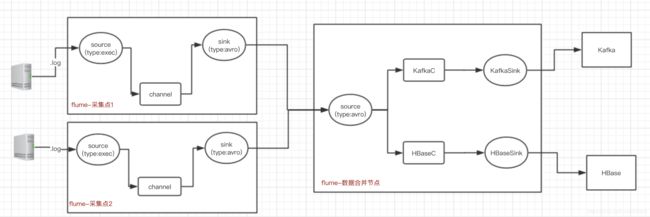
备注:
- Agent节点中的3个线程:
- Source :数据源端
- channel:通道,发送数据到数据接收端sink。
- sink:数据接收端
Flume Agent-1采集节点服务配置
flume-env.sh:

flume-conf.properties:

Flume Agent-2采集节点服务配置
flume-env.sh:
flume-conf.properties:

第12章:Flume+HBase+Kafka集成与开发
Flume-3数据合并节点服务思路梳理

下载Flume源码并导入Idea开发工具

下载实验日志数据
数据来源:搜狗实验室
Flume与HBase集成配置
说明:具体请参考Flume官网与其他框架集成时的source、channel、sink的配置介绍
Flume数据合并节点(机器1)的配置:
1.flume-env.sh:
2.flume-conf.properties:

对日志数据进行格式处理
1.将下载的日志文件中的tab替换为逗号
cat weblogs.log|tr “\t” “,” > weblog2.log
cat weblog2.log|tr " " “,” > weblog3.log
2.然后将数据分发到2,3机器
自定义SinkHBase程序设计与开发
创建自定义的类(参考自带的AsyncHbaseEventSerializer类):
package org.apache.flume.sink.hbase;
import com.google.common.base.Charsets;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.FlumeException;
import org.apache.flume.conf.ComponentConfiguration;
import org.apache.flume.sink.hbase.SimpleHbaseEventSerializer.KeyType;
import org.hbase.async.AtomicIncrementRequest;
import org.hbase.async.PutRequest;
import java.util.ArrayList;
import java.util.List;
public class MyAsyncHbaseEventSerializer implements AsyncHbaseEventSerializer {
private byte[] table;
private byte[] cf;
private byte[] payload;//列的value
private byte[] payloadColumn;//列名
private byte[] incrementColumn;
private String rowPrefix;
private byte[] incrementRow;
private KeyType keyType;
@Override
public void initialize(byte[] table, byte[] cf) {
this.table = table;//表名
this.cf = cf;//列名
}
@Override
public List<PutRequest> getActions() {//flume每get一次event(一行数据),就调用一次getActions
List<PutRequest> actions = new ArrayList<PutRequest>();
if (payloadColumn != null) {
byte[] rowKey;
try {
String[] columns=new String(this.payloadColumn).split(",");
//每一行的数据
String[] values=new String(this.payload).split(",");
//自定义rowKey
String datetime=String.valueOf(values[0]);//valueOf可以将null转为String中的空字符串
String userid=String.valueOf(values[1]);
rowKey=SimpleRowKeyGenerator.getMyRowKey(userid,datetime);
for(int i=0;i<columns.length;i++){//将此行按列值存储
if(columns.length != values.length) break;
byte[] colColumn=columns[i].getBytes();
byte[] colValue=values[i].getBytes("UTF8");
PutRequest putRequest = new PutRequest(table, rowKey, cf,
colColumn, colValue);
actions.add(putRequest);
}
} catch (Exception e) {
throw new FlumeException("Could not get row key!", e);
}
}
return actions;
}
public List<AtomicIncrementRequest> getIncrements() {
List<AtomicIncrementRequest> actions = new ArrayList<AtomicIncrementRequest>();
if (incrementColumn != null) {
AtomicIncrementRequest inc = new AtomicIncrementRequest(table,
incrementRow, cf, incrementColumn);
actions.add(inc);
}
return actions;
}
@Override
public void cleanUp() {
// TODO Auto-generated method stub
}
@Override
public void configure(Context context) {
String pCol = context.getString("payloadColumn", "pCol");
String iCol = context.getString("incrementColumn", "iCol");
rowPrefix = context.getString("rowPrefix", "default");
String suffix = context.getString("suffix", "uuid");
if (pCol != null && !pCol.isEmpty()) {
if (suffix.equals("timestamp")) {
keyType = KeyType.TS;
} else if (suffix.equals("random")) {
keyType = KeyType.RANDOM;
} else if (suffix.equals("nano")) {
keyType = KeyType.TSNANO;
} else if(suffix.equals("uuid")){
keyType = KeyType.UUID;
}else{
keyType = KeyType.MYKEY;
}
payloadColumn = pCol.getBytes(Charsets.UTF_8);
}
if (iCol != null && !iCol.isEmpty()) {
incrementColumn = iCol.getBytes(Charsets.UTF_8);
}
incrementRow = context.getString("incrementRow", "incRow").getBytes(Charsets.UTF_8);
}
@Override
public void setEvent(Event event) {
this.payload = event.getBody();
}
@Override
public void configure(ComponentConfiguration conf) {
// TODO Auto-generated method stub
}
}
在SimpleRowKeyGenerator类中添加方法:
public static byte[] getMyRowKey(String userid, String datetime) throws UnsupportedEncodingException {
return (userid +"-"+ datetime +"-"+ String.valueOf(System.currentTimeMillis())).getBytes("UTF8");
}
补充:用maven编译Apache flume-ng 1.7.0问题:
1.
flume-ng-sinks
org.apache.flume
1.7.0
Fail!无法导入!
解决:在setting中引入阿里云镜像
2.import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.FlumeException;
import org.apache.flume.conf.ComponentConfiguration;
无法导入
解决:从官网的flume下的lib包里本地导入。
Idea中自定义SinkHBase程序编译打jar包
2.

3.Build->Build->Artifacts
Flume与kafka集成配置
参考前文“Flume数据合并节点(机器1)的配置”小节中的flume-conf.properties的完整配置
备注:
- 相对于kafka,flume相当于kafka的producer端
第13章:数据采集/存储/分发完整流程测试
应用服务模拟程序开发

备注:
- 模拟程序:用于实时生成日志数据,模拟实际情况中从日志服务器中拿数据。
package main.java;
import java.io.*;
/**
* Created by niccoleynh on 2019/2/1.
*/
public class LogReaderWriter {
static String readFileName;
static String writeFileName;
public static void main(String args[]){
readFileName = args[0];
writeFileName = args[1];
try {
// readInput();
readFileByLines(readFileName);
}catch(Exception e){
}
}
public static void readFileByLines(String fileName) {
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
String tempString = null;
try {
System.out.println("以行为单位读取文件内容,一次读一整行:");
fis = new FileInputStream(fileName);// FileInputStream
// 从文件系统中的某个文件中获取字节
isr = new InputStreamReader(fis,"GBK");
br = new BufferedReader(isr);
int count=0;
while ((tempString = br.readLine()) != null) {
count++;
// 显示行号
Thread.sleep(300);
String str = new String(tempString.getBytes("UTF8"),"GBK");
System.out.println("row:"+count+">>>>>>>>"+tempString);
method1(writeFileName,tempString);
//appendMethodA(writeFileName,tempString);
}
isr.close();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (isr != null) {
try {
isr.close();
} catch (IOException e1) {
}
}
}
}
public static void method1(String file, String conent) {
BufferedWriter out = null;
try {
out = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file, true)));
out.write("\n");
out.write(conent);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
模拟程序Jar包上传与分发
- 分发到所有Flume日志收集节点服务器
- 更改jar包的执行权限
chmod u+x XXX.jar
编写运行模拟程序的shell脚本
-
本地配置输入文件与输出文件目录
- weblog.log:读入文件来源
- weblog-flume.log:输出文件,用于模拟从服务器收集到的日志数据
-
编写读取日志执行脚本:weblog-shell.sh
#!/bin/bash
echo "start log......"
java -jar /opt/jars/LogReaderWriter.jar /opt/datas/weblog.log /opt/datas/weblog-flume.log
编写Flume集群服务启动脚本
1.每个flume节点如下所示编写脚本
flume-ynh-start.sh
#!/bin/bash
echo "flume-2 start......"
bin/flume-ng agent --conf conf -f conf/flume-conf.properties -n agent2 -Dflume.root.logger=INFO,console
编写Kafka Consumer执行脚本
用于测试flume-producer的数据是否接收到
#!/bin/bash
echo "consumer test……"
bin/kafka-console-consumer.sh --zookeeper bigdata-pro01.ynh.com:2181,bigdata-pro02.ynh.com:2181,bigdata-pro03.ynh.com:2181 --from-beginning --topic protest
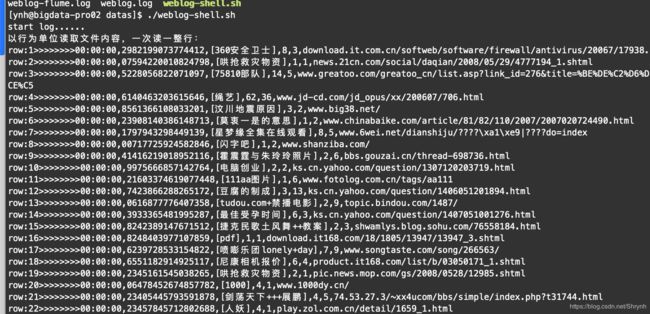
启动模拟程序服务并测试
- 启动(LogReaderWriter.jar )weblog-shell.sh
hdfs集群服务启动并测试
启动数据采集所有服务:

Zookeeper集群服务启动并测试
- 三台机器启动:bin/zkServer.sh start
- 查看leader和follower:bin/zkServer.sh status
- (或者也可以通过./zkCli.sh测试客户端启动状态)
hdfs-HA启动并测试(一)
说明:案例过程中:机器配置不够好时,可以不用使用HA
步骤:
1.启动zookeeper
2.启动Journalnode
3.启动hdfs服务
4.在各个namenode节点上启动DFSZK Failover Controller,先在哪台机器启动,那个机器的namenode就是active namenode
备注:
如果出现错误,请参考前面章节“HDFS-HA服务启动及自动故障转移测试”同步namenode元数据、初始化ZK
HBase集群启动并测试
步骤:
1.启动HBase集群
/bin/start-hbase.sh
2.查看web页面60010启动情况
3.检查shell启动情况:
bin/hbase shell
备注:
- 如果HBase启动不起来,根据具体情况,可能有如下几种原因和对应的解决方案:
- 可以进zkCli.sh中干掉Zookeeper中已经注册的HBase节点,再重新初始化启动HBase即可。
- 各个服务器间时间同步出现了问题。(因为HBase对时间敏感度很高,30几秒都可能造成HBase启动错误)
- 域名解析出问题。先检查本机配置的hosts是否正确。
kafka集群启动并整理topic
步骤:
1.kafka启动:
bin/kafka-server-start.sh config/server.properties
2.整理topic
进入zkCli
bin/zkCli.sh
ls /brokers/topics
删除多余的topic:
rmr /brokers/topics/XXX
kafka服务创建业务数据topic
1.创建业务topic
bin/kafka-topics.sh --create --zookeeper bigdata-pro01.ynh.com:2181,bigdata-pro02.ynh.com:2181,bigdata-pro03.ynh.com:2181 --replication-factor 2 --partitions 1 --topic weblogs
2.进入zkcli.sh 查看
ls /brokers/topics
HBase中创建业务数据表
1.进入HBase shell
2.创建业务数据表
create ‘weblogs’,info’
Flume服务启动并解决出现的问题(一)
- 检查配置文件2,3,1
- 启动机器2,3的flume服务
- 启动weblogs-shell.sh模拟程序
- 启动机器1的flume:
- 错误:can’t get conf/。 解决方案:在flume-env.sh中添加export hadoo_home和hbase_home
Flume服务启动并解决出现的问题(二)
- 报错:can’t get a row key.–程序逻辑问题。
- 解决方案:AsyncHBaseSink类中替换

- 解决方案:AsyncHBaseSink类中替换
完成数据采集全流程测试
注意: (参考官网安装说明注意事项)flume-1.7.0要对应kafka0.9X及以上。
1.创建kafka存放日志路径
mkdir kafka-logs
2.启动三台kafka
3.启动flume日志收集节点服务
4.启动flume日志合并分发节点服务
5. 启动weblog-shell.sh
6.启动一个consumer消费者,查看是否有数据
7.查看hbase是否拿到数据
进入hbase shell
count ‘weblogs’
scan ‘weblogs’


关于kafka集群中问题的解答
- kafka创建topic时副本数=kafka集群启动的机器数。(所以当3台机器其中几台服务down掉之后,消费者还可以从剩余机器消费数据)
第14章:MySQL安装
配置MySql在线安装的yum源
- 备份本地的Centos-Base.rep
- 下载新的CentOS-Base.repo (从这里可以下载)到/etc/yum.repos.d/,更名Centos-Base.repo
在线安装mysql并启动服务测试
步骤:
1.登入机器1的虚拟机
1)连接到外网:修改自动获取IP
2)切换到root用户
3)清除yum缓存(包括下载的软件包和header)
yum clean all
4)下载安装mysql服务
yum install mysql-server
5)查看mysql启动状态
service mysqld status
6)启动mysql服务
sudo service mysqld start
- 进入mysql,查看数据库信息
mysql -uroot -p123456
mysql命令:
show databases;
use test;
show tables;
第15章:Hive集成HBase进行数据分析

Hive概述
一、什么是Hive?
- 由Facebook开源用于解决海量结构化日志的数据统计;
- Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据(结构化数据:能够用二维表结构来逻辑表达的数据)映射成一张表,并提供类Sql查询功能;
- 类似于前置的映射的一个引擎,通过查询便捷地对hadoop的数据进行分析
- 构建在Hadoop之上的数据仓库;
- 使用HQL作为查询接口;
- 使用HDFS存储
- 使用MapReduce计算;
- 本质是:将HQL转化成MapReduce程序
- 灵活性和扩展性比较好:支持UDF,自定义存储格式等;
- 适合离线数据处理;
Hive在Hadoop生态系统中的位置
重点
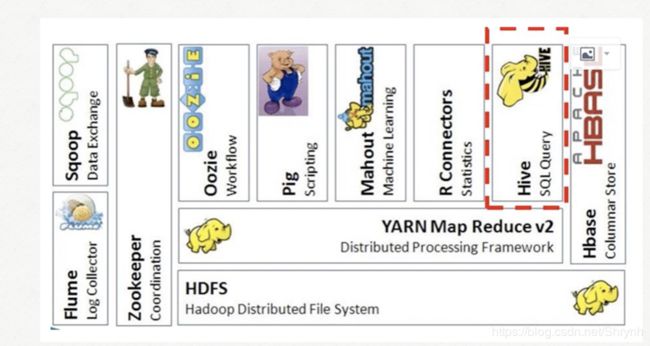
Hive架构设计
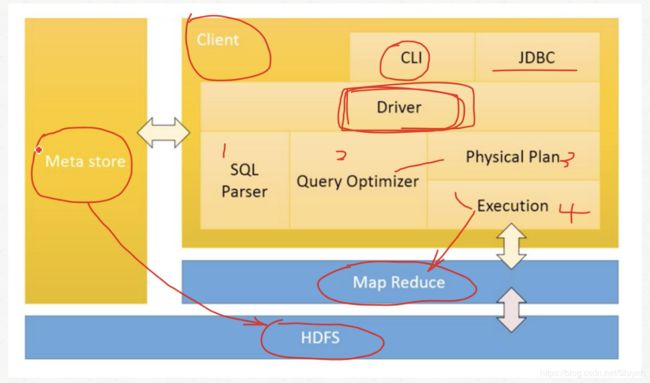
备注:
- Hive依赖的3个主要进程
- Meta store:外部的服务,存储Hive表的元数据 (本案例中使用MySql存储Hive表的元数据)
- HDFS
- MapReduce
- 查询执行流程:client通过CLI/JDBC发起查询->Driver->SQL解析、优化、物理执行计划->查询Meta Store中Hive表的元数据->MapReduce执行->HDFS中查询
Hive的优点及应用场景
- 操作接口采用类SQL语法,提供快速开发的能力(简单、易上手)
- 避免了去写MapReduce,减少开发人员的学习成本;
- 统一的元数据管理,可与impala/spark等共享元数据;
- 易扩展(HDFS+MapReduce:可以扩展集群规模;支持自定义函数);
- 数据的离线处理;比如:日志分析,海量结构化数据离线分析
- Hive的执行延迟比较高,因为hive常用于数据分析的,数据量很大,对实时性要求不高的场合;
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
Hive版本下载及安装部署
步骤:
-
官网下载版本0.13.1
-
机器3上解压(机器1,2做了HA,为了减缓1,2的压力)
-
配置hive-env.sh:
- HADOOP_HOME
- HIVE_CONF_DIR
-
启动hdfs服务
-
在hdfs上创建hive的目录
bin/hdfs dfs -mkdir -p /user/hive/warehouse
bin/hdfs dfs -chmod g+w /user/hive/warehouse
- 启动hive服务:
bin/hive
- 查看hive表信息
show databases;
use databaseName;
show tables;
Hive与Mysql集成
-
在hive/conf下新建hive-site.xml文件。我们将hive元数据的在mysql上的存储配置在这个文件(类似于JDBC连接配置)
-
设置用户的链接:
-
进入mysql
-
查询用户信息:
-
select host,user,password from user;
-
更新用户信息:
-
update user set host=’%’ where user=‘root’ and host='localhost’
-
删除用户信息(只留下此条):
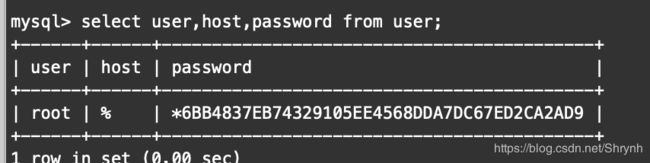
- delete from user where user=‘root’ and host=‘127.0.0.1’;
- delete from user where user=‘root’ and host=‘bigdata-pro01.ynh.com’;
- select user,host,password from user;
- delete from user where host=‘localhost’;
-
刷新信息
-
flush privileges;
-
-
-
拷贝驱动包mysql-connector-java-5.1.27-bin.jar到hive的lib目录下:
-
保证机器3到其他机器能够无秘钥登录(参考前面章节设置机器间的无秘钥登录)
Hive服务启动与测试
步骤:
1.启动hdfs和yarn
2.启动hive
bin/hive
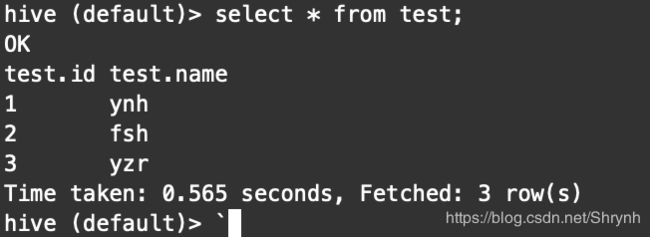
3.通过hive创建表
create table test(id int,name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
4.创建数据文件test.txt
5.加载数据文件到hive表中
load data local inpath ‘opt/datas/test.txt’ into table test;
备注:
-
hive-site.xml中最好还添加上显示列名的配置项(可在hive-default.xml)中查找。
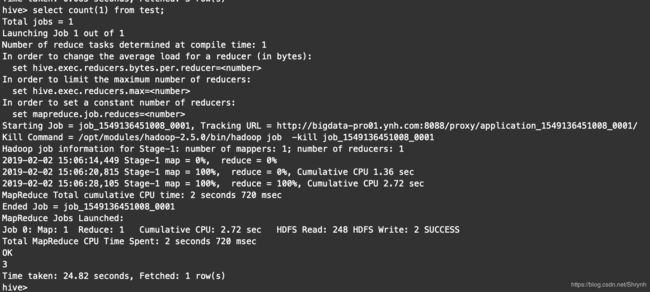
-
count语句测试(物理执行的时候,启动了mapreduce)
-
查看mysql中hive表的元数据

根据业务需求创建Hive数据分析表结构
Hive与HBase集成进行数据离线分析
步骤:
1.在hive-site文件中配置Zookeeper,hive通过这参数的配置去连接HBase

2.将hbase的这9个包copy到hive/lib下,如果是hbase和hive都是下载的CDH同版本的,就不需要copy,因为CDH本身已经做了集成。
ln -s $HBASE_HOME/lib/hbase-server-0.98.6-cdh5.3.0.jar $HIVE_HOME/hbase-server-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-client-0.98.6-cdh5.3.0.jar $HIVE_HOME/hbase-client-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-protocol-0.98.6-cdh5.3.0.jar $HIVE_HOME/hbase-protocol-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-it-0.98.6-cdh5.3.0.jar $HIVE_HOME/hbase-it-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/htrace-core-2.04.jar $HIVE_HOME/htrace-core-2.04.jar
ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-0.98.6-cdh5.3.0.jar $HIVE_HOME/hbase-hadoop2-compat-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compat-0.98.6-cdh5.3.0.jar $HIVE_HOME/hbase-hadoop-compat-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/high-scale-lib-1.1.1.jar $HIVE_HOME/high-scale-lib-1.1.1.jar
ln -s $HBASE_HOME/lib/hbase-common-0.98.6-cdh5.3.0.jar $HIVE_HOME/hbase-common-0.98.6-cdh5.3.0.jar
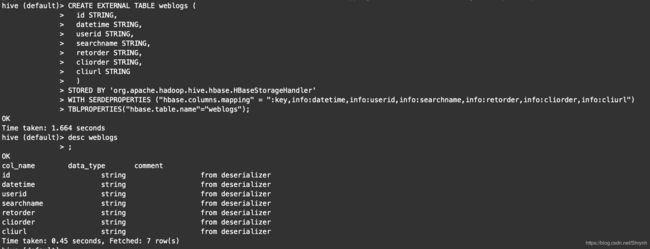
3.创建Hive的外部表,与HBase集成
CREATE EXTERNAL TABLE weblogs (
id STRING,
datetime STRING,
userid STRING,
searchname STRING,
retorder STRING,
cliorder STRING,
cliurl STRING
)
STORED BY ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler’
WITH SERDEPROPERTIES (“hbase.columns.mapping” = “:key,info:datetime,info:userid,info:searchname,info:retorder,info:cliorder,info:cliurl”)
TBLPROPERTIES(“hbase.table.name”=“weblogs”);
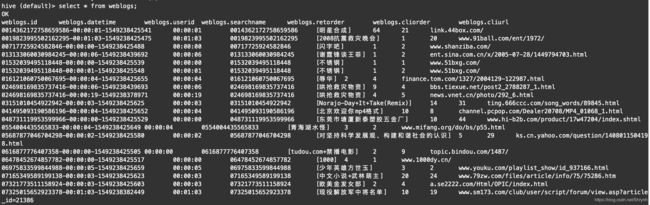
结果展示:

4.启动Hive关系的其他的服务集群
1)启动hdfs集群服务
2)启动yarn集群服务
3)启动Zookeeper集群服务
4)启动HBase集群服务
5)启动hive服务
补充:
- “hive与hbase的区别”链接
- Hive下的其他命令
- bin/hiveservice2
- bin/beeline
说明:
此系列文章为网课学习时所记录的笔记,希望给同为小白的学习者贡献一点帮助吧,如有理解错误之处,还请大佬指出。学习不就是不断纠错不断成长的过程嘛~