目录
- 一、基本数据类型
- 1.1数字类型
- 1.1.1整数类型
- 1.1.2浮点数类型
- 1.1.3数值运算操作符
- 1.2字符串类型
- 1.2.1字符串
- 1.2.2字符串的使用
- 1.2.3字符串操作符
- 1.2.4字符串处理函数
- 1.2.5字符串处理方法
- 1.1数字类型
- 二、组合数据类型
- 2.1集合
- 2.1.1定义
- 2.1.2操作符
- 2.1.3处理方法
- 2.1.4应用场景
- 2.2序列
- 2.2.1定义
- 2.2.2操作符
- 2.2.3函数与方法
- 2.2.4元组
- 2.2.5列表
- 2.2.6应用场景
- 2.3字典
- 2.3.1定义
- 2.3.2函数
- 2.1集合
一、基本数据类型
1.1数字类型
1.1.1整数类型
- 十进制:1010,-219
- 二进制:以0b或0B开头:0b010,-0B101
- 八进制,以0o或0O开头:0o123,-0O234
- 十六进制,以0x或0X开头:0x9a,-0X89
1.1.2浮点数类型
1、运算存在不确定尾数,但不是bug
round(x,d):对x四舍五入,d是小数截取位数(浮点数间运算、比较可用该函数辅助)
2、可采用科学计数法表示
使用字母e或E作为幂的符号,以10为基数,格式:e,表示 a*10^b。如:4.3e-3 为0.0043,9.6E5 为960000.0
1.1.3数值运算操作符
/ 除运算,结果为浮点数
// 整除运算
** 幂运算
类型间可以进行混合运算,生成结果为“最宽”类型:整数->浮点数->复数
#daydayupQ1.py
dayfactor=0.001
dayup=pow(1+dayfactor,365)
daydown=pow(1-dayfactor,365)
print("向上:{:.2f},向下:{:.2f}\n".format(dayup,daydown))
#daydayupQ2.py
def dayUP(df): # def保留字用于定义函数
dayup=1
for i in range(365):
if i%7 in [6,0]:
dayup*=1-0.01 #休息日能力退步
else:
dayup*=1+df #工作日能力进步
return dayup
dayfactor=0.01
while dayUP(dayfactor)<37.78:
dayfactor+=0.001
print("工作日的努力参数是:{:.3f}".format(dayfactor))1.2字符串类型
1.2.1字符串
1、定义:由0个或多个字符组成的有序字符序列
- 由一对单引号或双引号表示单行字符串
- 由一对三单引号或三双引号表示多行字符串。多行注释也是一种字符串,只是没有赋给变量
- 是字符的有序序列,可以对其中的字符进行索引
2、2类4种表示方法
- 希望在字符串中包含双引号或单引号(包含单引号时,外侧用双引号;包含双引号时,外侧用单引号),如:'这里有个双引号(")' 或 "这里有个单引号(')"
- 希望在字符串中既包括单引号又包括双引号(外侧使用三单引号),如:'''这里既有单引号(' ')又有双引号(" ")'''
3、字符串的序号:正向递增序号(第一个字符从0开始),反向递减序号(最后一个字符从-1开始)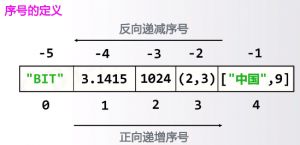
1.2.2字符串的使用
1、使用[]获取字符串中一个或多个字符
- 索引:返回字符串中单个字符 [M],如:TempStr[-1]
- 切片:返回字符串中一段字符子串 [M:N](从第M个开始,不到第N个。M缺失表示从头开始,N缺少表示到结尾),如:TempStr[0:-1]
高级用法:使用[M:N:K]根据步长对字符串切片,如:"0123456789"[1:8:2] 的结果为 "1357"。如果想对字符串逆序,可用"0123456789"[::-1]
2、转义符 表达特定字符的本意,如:"这里有个双引号(")",即外侧也可使用双引号
形成组合,表示特殊含义,如:\n,\b等
1.2.3字符串操作符
- x+y:连接两个字符串
- xn 或 nx:复制 n次字符串 x
- x in s:若 x是 s的子串,返回True,否则返回False
1.2.4字符串处理函数
- len(x):返回字符串 x的长度(Python中,数字、标点符号、字母、汉字都是一个字符),如:len("一二三456") 为 6
- str(x):任意类型 x对应的字符串形式,如:str([1,2]) 为 "[1,2]"
- hex(x)或oct(x):整数 x的十六进制或八进制小写形式字符串,如:hex(425) 为 "0x1a9",oct(425) 为 "0o651"
- chr(u):u为Unicode编码,返回对应字符
- ord(x):x为字符,返回对应Unicode编码
1.2.5字符串处理方法
方法:特指 .()风格中的函数 ();其本身也是函数,但与 有关,以 .()风格使用;字符串及变量也是 ,存在一些方法
- str.lower()或str.upper():返回字符串的副本,全部字符小写/大写
- str.split(sep=None):返回一个列表,由 str根据 sep被分隔的部分组成,如:"A,B,C".split(",") 为 ['A','B','C']
- str.count(sub):返回子串 sub在 str中出现的次数,如:"an apple a day".count("a") 为 4
- str.repiace(old,new):返回字符串 str的副本,所有 old子串被替换为 new
- str.center(width,[,fillchar]):字符串 str根据宽度 width居中,fillchar可选,如:"python".center(20,"=") 为 '=======python======='
- str.strip(chars):从 str中去掉在其左侧和右侧 chars中列出的每个字符(而不是整体的字符串),如:"= python=".strip(" =np") 为 "ytho"
- str.join(iter):在 iter变量除最后元素外每个元素后增加一个 str(主要用于字符串分隔),如:",".join("12345") 为 "1,2,3,4,5"
#获取星期字符串
#输入:1-7的整数,表示星期几
#输出:输入整数对应的星期字符串
weekStr="星期一星期二星期三星期四星期五星期六星期日"
weekID=eval(input("请输入星期数字(1-7):"))
pos=(weekID-1)*3
print(weekID[pos:pos+3])
#简化版
weekStr="一二三四五六日"
weekID=eval(input("请输入星期数字(1-7):"))
print("星期"+weekStr[weekID-1])二、组合数据类型
2.1集合
2.1.1定义
(与数学中的集合概念一致)
集合元素不可更改,不能是可变数据类型
- 用大括号 {} 表示,元素间用逗号分隔
- 建立集合类型用 {} 或 set()
- 建立空集合类型,必须使用 set()
A={"python",123,("python",123)}
#为:{123,'python',('python',123)}
B=set("python123")
#为:{'1','p','2','3','y'} 无序的
C={"python",123,"python",123}
#为:{'python',123}2.1.2操作符
- S|T:返回一个新集合,包括在集合 S和 T中的所有元素
- S-T:返回一个新集合,包括在集合 S但不在 T中的元素
- S&T:返回一个新集合,包括同时在集合 S和 T中的元素
- S^T:返回一个新集合,包括集合 S和 T中的非相同元素
- S<=T或S
- S>=T或S>T:返回 True/False,判断 S和 T的包含关系
增强操作符
- S|=T:更新集合 S,包括在集合 S和 T中的所有元素
- S-=T:更新集合 S,包括在集合 S但不在 T中的元素
- S&=T:更新集合 S,包括同时在集合 S和 T中的元素
- S^=T:更新集合 S,包括集合 S和 T中的非相同元素
A={'p','y',123}
B=set("pypy123")
A-B
#为:{123}
A&B
#为:{'p','y'}
A^B
#为:{'2',123,'3','1'}
B-A
#为:{'3','1','2'}
A|B
#为:{'1','p','2','y','3',123}2.1.3处理方法
- S.add(x):如果 x不在集合 S中,将 x增加到 S
- S.discard(x):移除 S中元素 x;如果 x不在集合 S中,不报错
- S.remove(x):移除 S中元素 x;如果 x不在集合 S中,产生 KeyError异常
- S.clear():移除 S中所有元素
- S.pop():随即返回 S的一个元素,更新 S,若 S为空产生 KeyError异常
A={"p","y",123}
for item in A:
print(item,end="")
try:
while True:
print(A.pop(),end="") #从 A中弹出一个元素,当列表为空时返回异常
except:
pass #此时 A为空2.1.4应用场景
- 关系比较
- 数据去重
"p" in {"p","y",123}
#为:True
{"p","y"}>={"p","y",123}
#为:False
ls=["p","p","y","y",123]
s=set(ls) #利用集合无重复元素的特点
#{'p','y',123}
lt=list(s) #再将集合转换为列表
#['p','y',123]2.2序列
2.2.1定义
具有先后关系的一组元素
- 一维元素向量,元素可以相同,元素类型可以不同(如:)
- 类似数学元素序列:S0,S1,...Sn-1
- 元素间由序号引导,通过下标访问序列的特定元素
基类类型,衍生出 字符串类型,元组类型,列表类型
2.2.2操作符
- x in s:如果 x是序列 s中的元素,返回 True,否则返回 False
- x not in s:如果 x是序列 s中的元素,返回 False,否则返回 True
- s+t:连接两个序列 s和 t
- sn或ns:将序列 s复制 n次
- s[i]:索引,返回 s中第 i 个元素,i 是序列的序号
ls=["python",123,".io"]
ls[::-1]
#为:['.io',123,'python']
s="python123.io"
ls[::-1]
#为:'oi.321nohtyp'2.2.3函数与方法
- len(s):返回序列 s的长度
- min(s):返回序列 s的最小元素,s中元素需要可比较
- max(s):返回序列 s的最大元素,s中元素需要可比较
- s.index(x)或s.index(x,i,j):返回序列 s从 i开始到j位置中第一次出现元素 x的位置
- s.count(x):返回序列 s中出现 x的总次数
ls=["python",123,".io"]
len(ls)
#为:3
s="python123.io"
max(s)
#为:'y'2.2.4元组
- 一种序列类型,一旦创建就不能扩展
- 使用小括号()或tuple()创建,元素用逗号分隔
- 小括号不是必需的
def func():
return 1,2
#实际返回的是(1,2)的元组
creature="cat","dog","tiger","human"
#为:('human','tiger','dog','cat')
color=(0x001100,"blue",creature)
#为:(4352,'blue',('cat','dog','tiger','human'))
color[-1][2]
#为:'tiger'2.2.5列表
1、定义
- 一种序列类型,创建后可以随意修改
- 使用方括号[]或list[]创建,元素用逗号分隔
- 各元素类型可以不同,无长度限制
2、函数
- ls.append(x):在列表 ls最后增加一个元素 x
- ls.clear():删除列表 ls的所有元素
- ls.copy():生成一个新列表,赋值 ls中所有元素
- ls.insert(i,x):在列表 ls的第 i个位置插入元素 x
- ls.pop(i):将列表 ls中第 i个位置的元素取出并删除该元素
- ls.remove(x):将列表 ls中出现的第一个元素 x删除
2.2.6应用场景
- 元素遍历
- 数据保护(转换成不能扩展的元组类型)
ls=["cat","dog","tiger",1024]
#为:['cat','dog','tiger',1024]
lt=ls
#lt为:['cat','dog','tiger',1024]。赋值仅传递引用,lt和ls其实指向的是同一个2.3字典
2.3.1定义
映射是一种键(索引)和值(数据)的对应
字典类型是“映射”的体现
- 键值对:键是数据索引的扩展
- 字典是键值对的集合,键值对之间无序
- 使用大括号和 dist()创建,键值对用冒号 : 表示,如:{:,:,...,:}
字典变量中通过键获得值
- ={:,:,...,:}
- =[] []=
- [ ] 用来向字典变量中索引或增加元素
d={"中国":"北京","法国":"巴黎"}
d["中国"]
#为:北京
de={}
#大括号仅用于建造 空字典2.3.2函数
- del d[k]:删除字典 d中键 k对应的数据
- k in d:判断键 k是否在字典中,在则返回 True
- d.keys():返回字典 d中所有键的信息
- d.values():返回字典 d中所有值的信息
- d.items():返回字典 d中所有键值对的信息
- d.get(k,):键 k存在则返回对应值,否则返回 default
- d.pop(k,):键 k存在则取出对应值,否则返回 default
- d.popitem():随即从字典中取出一个键值对,以元组形式返回
- d.clear():删除所有键值对
- len(d):返回字典中元素个数