VMware上部署Hadoop-2.8.5+Spark-2.3.0完全分布式集群
相信大多数初学者和我一样,对配置环境头疼的一批;
我在这里简单介绍一下hadoop基于虚拟机的完全分布式部署;
1 首先说一下我的电脑配置吧:
win10操作系统;8g内存;i5六代处理器;配置越高越好吧(要不然容易卡顿);
Ubuntu 16.04(这个镜像大家可以去网上下啊;之后安装什么的都比较简单就不说了)
我强调一点:可以先安装一个镜像进行配置然后进行复制,这样可以减少很多重复的配置。
我安装了三个镜像(也是完全分布最少的)
除了上面说到的再说一用到的配置文件:
java1.8 scala2.12 hadoop-2.8.5 spark-2.3.0 (这些资源自行百度下载!!!)
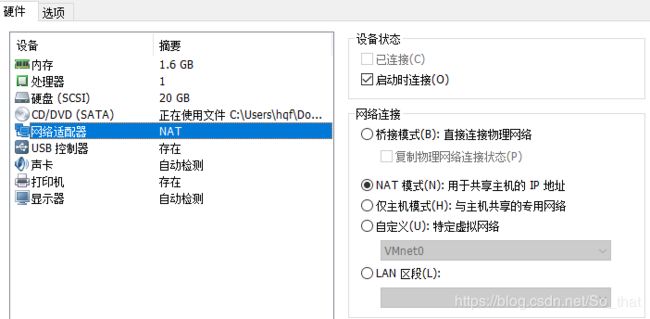
2 然后开始说一下网络配置
我配置的时NAT模式,在虚拟机中设置网络设配器中可以设置(三台都一样)这样了使虚拟机上网。
3 修改hostname和hosts
大家首先在cd etc; vim hostname 中修改一下名字 我是用的是Master,Slave1,Slave2;
也可以不着急修改等其他配置好了;在修改。
hosts文件也在etc下,这个文件的修改是这样的:
把文件改成如下格式:(IP123是自己节点ip)
127.0.0.1 localhost
IP1 Master
IP2 Slave1
IP3 Slave2
4 接下来就是一系列的配置
首先配置jdk 大家把安装包 拖到虚拟机的 home/(用户名)/ 下 然后解压;如 tar -zxf 文件名
我的所有的安装都是在usr中的,所以在解药完之后 就需要移动 mv 文件 /usr/java (文件名字自定义)
然后就是配置 profile 这个文件在 cd etc 中 vim profile 点击i修改:wq保存;
主要需要修改内容为(Hadoop spark java scala)***_home以及path我的配置如下:
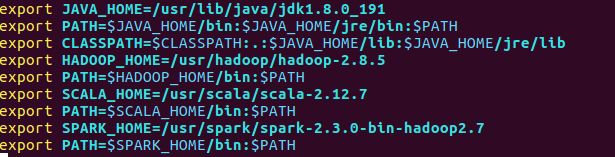
以上配置中文件路径大家根据实际情况进行修改。
再接着就是安装 Hadoop,spark,scala 都和上面过程一样,不再赘述。
下面说一下配置文件
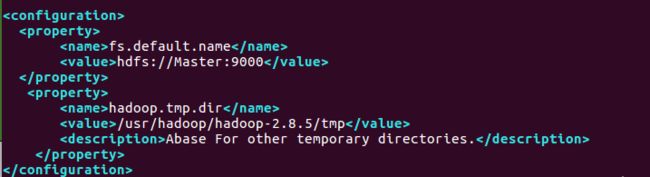
Hadoop需要配置三四个文件其中
cd usr/haoop/hadoop-2.8.5/etc/hadoop/core-site.xml ( 配置文件大都在这个目录)
vim hdfs-site.xml
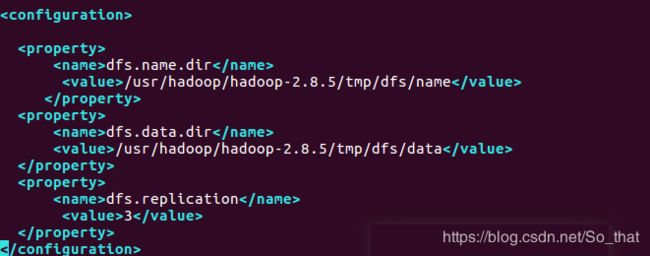
vim mapred-site.xml

vim yarn-site.xml

5 配置完成之后就是启动Hadoop 首先Hadoop namenode -format (只运行一次)然后启动
在sbin下 ./start-all.sh进行启动,然后通过jps查看(其中master和worker是spark启动之后才有的)
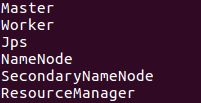
也可以通过 master:8088 或者 master:50070 查看
6 接着是spark的配置
在spark的conf下 使用cp a b (a b 为文件名)将a复制为b,如 cp spark-env.sh.tmplate spark-env.sh 然后修改成如下内容

在将slaves文件修改为 master slave1 slave2
这样配置就结束了,这个时候复制两个镜像(修改hostname和hosts:怎么修改前面已经介绍过了)
如果有镜像 也是使用scp 文件 ****@Slave1:home/ /****@Slave2传输文件。
最后启动hadoop 启动spark 启动spark-shell
最后进行测试。