GAN的Loss的比较研究(1)——传统GAN的Loss的理解1
GAN(Generative Adversarial Network)由两个网络组成:Generator网络(生成网络,简称G)、Discriminator网络(判别网络,简称D),如图:
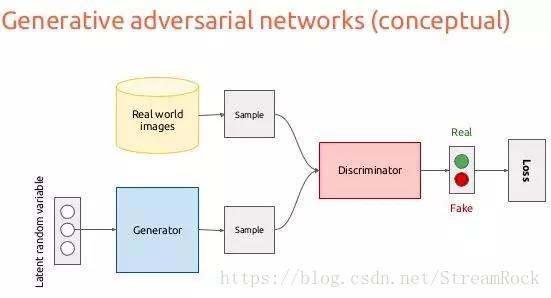
图1 GAN概念图
因而有两个Loss:Loss_D(判别网络损失函数)、Loss_G(生成网络损失函数)。
Loss_D只有两个分类,Real image判为1,Fake image(由G生成)判为0,因而可以用二进制交叉熵(BCELoss)来实现Loss_D。
熵(Entropy),是描述一个随机信号源的信息量的指标,为叙述方便,采用离散信号源。设信号源(S)可以发送N个符号 { S 1 , S 2 , . . . , S N } \{ S_1,S_2,...,S_N\} {S1,S2,...,SN},符号 S i S_i Si出现的概率为 P i P_i Pi,则该信号源所发送一个符号的平均信息量,即熵为:
H ( S ) = − ∑ i N P i log P i ( 1 ) H(S) = -\sum_i^N P_i\log P_i\qquad(1) H(S)=−i∑NPilogPi(1)
于是,熵就可以看成是一个概率的信息度量,于是从信息论过渡到概率度量上。对于连续概率分布,使用概率密度 p ( x ) p(x) p(x)代替(1)式中的概率 P i P_i Pi,有:
H ( S ) = − ∫ x p ( x ) log p ( x ) d x ( 2 ) H(S)=-\int_x p(x)\log p(x)dx\qquad(2) H(S)=−∫xp(x)logp(x)dx(2)
交叉熵(Cross Entropy)是描述两个随机分布(P、Q)差异的一个指标,其定义如下:
离 散 : H ( P ∣ Q ) = − ∑ i N P i log Q i ( 3 ) 连 续 : H ( P ∣ Q ) = − ∫ x p ( x ) log q ( x ) d x ( 4 ) 离散:H(P\vert Q) = -\sum_i^N P_i\log Q_i\qquad(3)\\ 连续:H(P\vert Q)=-\int_x p(x)\log q(x)dx\qquad(4) 离散:H(P∣Q)=−i∑NPilogQi(3)连续:H(P∣Q)=−∫xp(x)logq(x)dx(4)
P、Q的顺序不能互换。当P与Q相同时,交叉熵取最小值,此时计算的是P(或Q)的熵。
所谓二进制交叉熵(Binary Cross Entropy)是指随机分布P、Q是一个二进制分布,即P和Q只有两个状态0-1。令p为P的状态1的概率,则1-p是P的状态0的概率,同理,令q为Q的状态1的概率,1-q为Q的状态0的概率,则P、Q的交叉熵为(只列离散方程,连续情况也一样):
H ( P ∣ Q ) = − ( p log q + ( 1 − p ) log ( 1 − q ) ) ( 5 ) H(P|Q)=-( p\log q + (1-p)\log(1- q))\qquad(5) H(P∣Q)=−(plogq+(1−p)log(1−q))(5)
在GAN中,判别器(Discriminator)的输出与ground-truth(它的取值只有0-1)被看作是概率。交叉熵就是用来衡量这两个概率之间差异的指标:p反映的是ground-truth认为来自real的概率,用L表示(ground truth label)此分布,它只取两个值100%和0%,即1和0;q反映的是Discriminator认为的来自real的概率,用D(Discriminator prediction)表示此分布,它的取值是 [ 0 , 1 ] [0,1] [0,1]。
一个样本(1幅图片)x,假如来自real,p则为1,q为 D ( x r ) D(x_r) D(xr),其交叉熵输出是:
− ( 1 ∗ log D ( x r ) + ( 1 − 1 ) ∗ log ( 1 − D ( x r ) ) = − log D ( x r ) -(1*\log D(x_r)+(1-1)*\log( 1-D(x_r))=-\log D(x_r) −(1∗logD(xr)+(1−1)∗log(1−D(xr))=−logD(xr)
假如来自fake,p则为0,q为 D ( x f ) D(x_f) D(xf),其交叉熵为:
− ( 0 ∗ log D ( x f ) + ( 1 − 0 ) ∗ log ( 1 − D ( x f ) ) = − log ( 1 − D ( x f ) ) -(0*\log D(x_f)+(1-0)*\log( 1-D(x_f))=-\log (1-D(x_f)) −(0∗logD(xf)+(1−0)∗log(1−D(xf))=−log(1−D(xf))
于是,对于一个样本集,一半来自真实(real),一半来生成器(fake),其交叉熵的平均是:
H ( L ∣ D ) = − 1 M ( ∑ x r M log ( D ( x r ) ) + ∑ x f M l o g ( 1 − D ( x f ) ) ) ( 6 ) H(L|D)=-\frac{1}{M}(\sum_{x_r}^M\log (D(x_r))+\sum_{x_f}^M log(1-D(x_f)))\qquad(6) H(L∣D)=−M1(xr∑Mlog(D(xr))+xf∑Mlog(1−D(xf)))(6)
D的目标是让 P d P_d Pd接近理想概率分布 P i P_i Pi( P i P_i Pi分布是:real sample输入时,概率输出为1;fake sample输入时,概率输出为0)。因此交叉熵越小越好,即:
L o s s _ D ( L , D ) = − ( 1 M ∑ x r M log ( D ( x r ) ) − 1 M ∑ x f M l o g ( 1 − D ( x f ) ) ( 7 ) Loss\_D(L, D)=-(\frac{1}{M}\sum_{x_r}^M \log (D(x_r))-\frac{1}{M}\sum_{x_f}^M log(1-D(x_f))\qquad(7) Loss_D(L,D)=−(M1xr∑Mlog(D(xr))−M1xf∑Mlog(1−D(xf))(7)
(这里解释一下:传统的GAN的object function是:
min G max D E x ∼ q ( x ) [ log D ( x ) ] + E z ∼ p ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D E_{x\sim q(x)}[\log D(x)]+E_{z\sim p(z)}[\log (1-D(G(z)))] GminDmaxEx∼q(x)[logD(x)]+Ez∼p(z)[log(1−D(G(z)))]
因此,在GAN第一阶段——求Discriminator最大化时是:
max D E x ∼ q ( x ) [ log D ( x ) ] + E z ∼ p ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \max_D E_{x\sim q(x)}[\log D(x)]+E_{z\sim p(z)}[\log (1-D(G(z)))] DmaxEx∼q(x)[logD(x)]+Ez∼p(z)[log(1−D(G(z)))]
在当前的DeepLearning平台上,统计梯度是对最小值进行寻优的,因此实际操作上是对目标函数做最小化处理:
min D ( − E x ∼ q ( x ) [ log D ( x ) ] − E z ∼ p ( z ) [ log ( 1 − D ( G ( z ) ) ) ] ) \min_D (-E_{x\sim q(x)}[\log D(x)]-E_{z\sim p(z)}[\log (1-D(G(z)))]) Dmin(−Ex∼q(x)[logD(x)]−Ez∼p(z)[log(1−D(G(z)))])。据此,公式(7)中Loss_D等于目标函数取负号。
)
为求最优判别器 D ∗ D^* D∗,(7)的等价形式如下,即求两类别各自的期望:
L o s s _ D ( L , D ) = E x r ( − log ( D ( x r ) ) ) + E x f ( − l o g ( 1 − D ( x f ) ) ) ( 8 ) Loss\_D(L, D)= E_{x_r}(-\log (D(x_r)))+ E_{x_f}(-log(1-D(x_f)))\qquad(8) Loss_D(L,D)=Exr(−log(D(xr)))+Exf(−log(1−D(xf)))(8)
以下是一段来自https://github.com/znxlwm/pytorch-MNIST-CelebA-GAN-DCGAN/blob/master/pytorch_MNIST_DCGAN.py的代码:
y_real_ = torch.ones(mini_batch) # ground-truth 全为1
y_fake_ = torch.zeros(mini_batch) # 全为0
x_, y_real_, y_fake_ = Variable(x_.cuda()), Variable(y_real_.cuda()), Variable(y_fake_.cuda())
D_result = D(x_).squeeze()
D_real_loss = BCE_loss(D_result, y_real_) # 应用BCELoss
z_ = torch.randn((mini_batch, 100)).view(-1, 100, 1, 1)
z_ = Variable(z_.cuda())
G_result = G(z_)
D_result = D(G_result).squeeze()
D_fake_loss = BCE_loss(D_result, y_fake_) # 应用BCELoss
D_fake_score = D_result.data.mean()
D_train_loss = D_real_loss + D_fake_loss # 实现上述公式7
以上是判别器Discriminator的Loss,生成器Generator的目标是尽可能以假乱真,即D对G生成的图像也判为1的概率越高越好,即 D ( x f ) D(x_f) D(xf)越高越好,而且它是概率, 0 ≤ D ( x f ) ≤ 1 0\le D(x_f)\le 1 0≤D(xf)≤1,它的单调性与 log D ( x f ) \log D(x_f) logD(xf)相同,在ML中,要求最小值,因而取反,即 − log D ( x f ) -\log D(x_f) −logD(xf),因此,有:
L o s s _ G = − log D ( x f ) = − ( 1 ∗ log D ( x f ) + 0 ∗ log ( 1 − D ( x f ) ) = H ( L ∣ D f ) ( 9 ) Loss\_G=-\log D(x_f)=-(1*\log D(x_f)+0*\log (1-D(x_f))=H(L|D_f)\qquad(9) Loss_G=−logD(xf)=−(1∗logD(xf)+0∗log(1−D(xf))=H(L∣Df)(9)
H ( L ∣ D f ) H(L|D_f) H(L∣Df)是输入fake图像,判为1的概率 D f D_f Df,其目标是100%。(9)实际是 D f D_f Df与1的二进制交叉熵。
实现代码如下:
G_train_loss = BCE_loss(D_result, y_real_) # y_real_全部为1
G_train_loss.backward()
G_optimizer.step()
BCELoss的解释:

(在推导的过程中,很容易出现符号的错误。)
GAN很强大,它生成的样本比VAE要更加清晰(边界清楚)和质量更好,但GAN很难训练,体现为两个方面:
1、模型坍塌,即产生的样本单一,没有了多样性。
2、训练过程收敛不易,一方面会出现梯度消失,另一方面会产生巨大的梯度不稳定。
Martin Arjovsky在他那两篇著名文章中,对Loss造成的影响进行了讨论:《Towards principled methods for training generative adversarial networks》、《Wasserstein GAN》。