原创,转载请注明出处
论文连接:https://arxiv.org/abs/1512.02325
这篇文章是2016ECCV的oral paper,目标检测领域的经典论文,值得一读。
一、背景介绍
- 目标检测
- 输入:一张图片
-
输出:感兴趣物体的包围框(bounding box) + 置信度(confidence)

- 评价指标:准确度:mAP
速度:FPS
- 相关工作
当前目标检测方法主要分为两类:Two Stage 和 One Stage的。
1)Two Stage
① 生成 Region Proposals(候选区域框)
② 对候选区域框进行分类以及位置精修
代表算法:R-CNN系列:R-CNN、Fast R-CNN、Faster R-CNN
优缺点:准确率高,但速度慢
2)One Stage
无需生成region proposals,直接生成物体包围框以及类别概率
代表算法:YOLO系列
优缺点:速度快,准确率低
二、整体框架

SSD的整体框架如上图,其将整个检测过程整合为一个single-pass deep neural network,它针对当前目标检测算法的缺点,做了改进,主要有三个key points。
- 在多层多尺度特征图上进行检测
- 采用default boxes的方式避免使用region proposal
- 采用卷积预测
接下来逐一介绍这三点改进:
1. 在多层多尺度特征图上进行检测
图像中的目标通常都有着不同的尺度,传统的目标检测多在一层特征图上进行检测,多尺度物体检测效果欠佳。低层特征图具有细节信息,看得比较细,而高层特征图中具有高级语义信息,看得比较广,SSD提出同时利用低层特征图和高层特征图进行检测。

SSD的基础网络是VGG,同时把最后两层全连接fc,换成了卷积层;SSD为了避免利用太低层的特征,从VGG后面开始,又往后添加了4层卷积层,如此就得到了多层次的特征图。
论文里具体采用的是conv4_3、conv7、conv8_2、conv9_2、conv10_2、conv11_2,这6层特征图来进行检测。输入一张300x300的图片进去,这6层特征图的大小分别为:38x38, 19x19, 10x10, 5x5, 3x3, 1x1
2. default boxes
two-stage 方法太慢,计算代价大。SSD中的第二个关键第是避免使用region proposals,而采用default boxes。SSD借鉴RPN网络中的anchor box概念。首先将feature map划分为小格子叫做feature map cell,再在每个cell中设置一系列不同长宽比的default box。
比如下面这张图,在每个cell设置4个不同长宽比的default boxes,因此整个8x8特征图上default boxes的数量为: 8x8x4=256个。
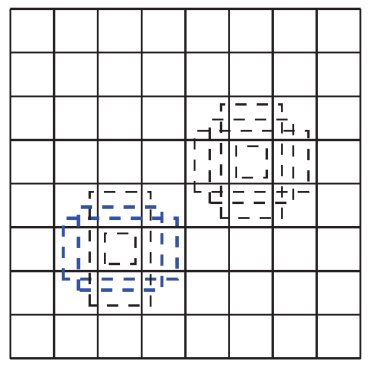
每个cell对应设置:4个不同长宽比的default boxes, 整张 8x8 feature map上的default boxes数量:8x8x4=256。
SSD中的default box与RPN中的anchor的区别在于,RPN中的anchor box用于在一层特征图中,而SSD中的default box用于多个特征层。假设要用m个feature map进行预测,那么每层default box的scale是通过这个公式进行计算的,这里的scale是default box边长对于输入图片边长的比例。其中,s_{min}和s_{max}分别表示最底层和最高层的的scale。具体在实现中s_{min}和s_{max}分别设置成了0.2和0.9。
default box可以有不同的长宽比,在这论文中取了如下这五种,同时,依据长宽比可以计算出每个default box的宽度和高度;并且在长宽比为1 的情况下,多添加一个scale,此时,一共有6种default box。
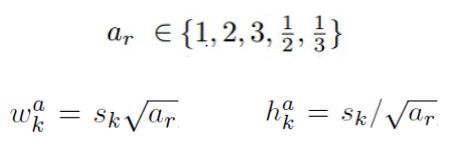
同时,default box的中心点的坐标可以通过如下的方式计算得到,其中|f_k|是第k个特征图的大小。可以看出坐标是大于0小于1的
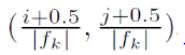
如此,default box在不同的feature层有不同的scale,在同一个feature层又有不同的长宽比。因此,基本上可以覆盖输入图像中的各种形状和大小的物体。
每个default box可以用中心点x坐标、中心点y坐标、宽度、长度,四个数值来表示。
SSD具体在在实现时,在第一层以及倒数两层特征图中去掉长宽比为3和1/3的default box,采用了4种default boxes,而在其余3层中采用6种default box当输入图片是300x300时,整个网络中default box的数量是可以算出来的,有8732个,可以看到,非常多。(#Default Box = 4x38x38 + 6x(19x19 + 10x10 + 5x5) +4x3x3 + 4x1x1 = 8732)
3. 用卷积层来预测
SSD的第三个改进是在向default box回归的时候,采用了3x3的卷积。
在YOLO中,首次提出了将特征图划分为格子,以格子为单位进行分类回归预测,但其采用了全连接层,导致参数非常多。SSD借鉴了Faster R-CNN的RPN网络,将YOLO中的全连接层换成了3x3的卷积。
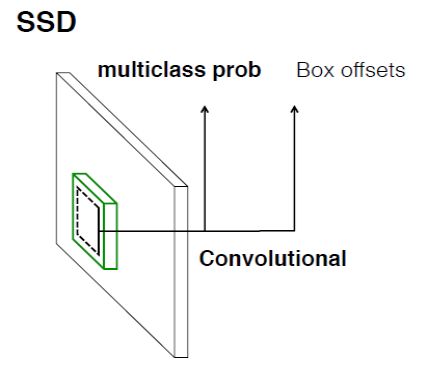
3x3的卷积在特征图上进行操作,在特征图的每个点提取特征,然后对每个default box生成四个偏移量来表示生成的bounding box,这四个偏移量分别表示生成框中心x坐标、y坐标、宽度、高度对应于当前default box的偏移量,这里的计算方法采用了RPN中的方法。同时,针对每个bounding box, 卷积会进行分类操作,输出C个分类数值,注意这里的C包括背景类。因此对于每个default box有C+4个输出值,而K个default box就有K(C+4)个输出值,因此,总共需要K*(C+4)个3x3卷积。
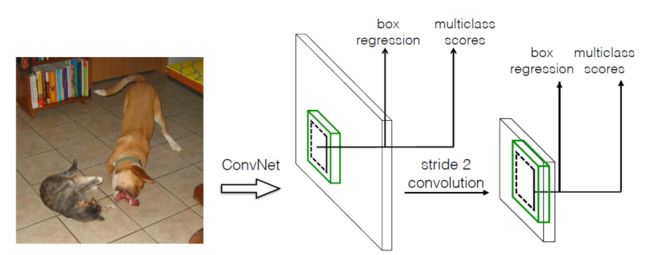
3x3的卷积可以很容易的应用在多层特征图上。
将SSD的三点关键点整合起来,就得到了SSD的整体架构。总的来说就是采用default box的方式,在多层多尺度的特征图上使用卷积进行检测(分类+回归)。对于300x300的图像来说,最后输出的时候会为每个类预测8732个bounding box
三、Training
1. gt 标定
在SSD训练过程中,比较特殊的是ground truth的标定。SSD训练时需要将ground truth需要赋予到default boxes上,SSD中通过IoU进行匹配。SSD中提出了一个匹配策略:对于每个gt,匹配与其IoU最大的default box;其次,对于某个default box存在gt box与其IoU大于0.5,匹配成功;匹配成功则该default box是positive正样本的;如果匹配不上,就是negative负样本。由此,ground truth 与 default box的关系是多对多的,应该也是论文标题中MultiBox的来源。

通过匹配策略,负样本数量远大于正样本,正负样本不平衡,导致训练很难收敛,因此采用Hard Negative Mining的方法,使得 负样本:正样本至多为3:1。
2. Training Objective
训练的loss:整个损失由分类和回归两部分组成

这里N是正样本数量,也即匹配成功default box数量,如果N为0,整个loss被设置为0。阿尔法是一个超参数,用来控制分类loss和回归loss两者的比重,SSD在实现中通过交叉验证将其设为1。
1) Bounding Box Regression(回归loss):
回归loss是采用了Fast R-CNN中的smooth L1 loss的形式。左侧的l表示:预测的box与default box之间的偏移量,也即网络输出的4个值;右侧的g表示,ground truth与default box的偏移量(在给定输入图片groudth与为整个网络设置好default box后,该值是可以直接计算出来的,其计算公式沿用了RPN网络的中的公式)。回归部分的loss是希望预测的box与default box之间的差距尽可能与ground truth和default box差距接近,这样预测的box就能尽量和ground truth一样。

注意:bounding box regression loss,只对属于正样本的default box进行计算;其次,在SSD的匹配策略下,default box与gt box之间的关系是多对多的,这里会对default box匹配到的所有ground truth box计算回归loss。
2) Confidence Loss:(分类loss):
Confidence loss是一个softmax分类loss,为每个default box进行分类。
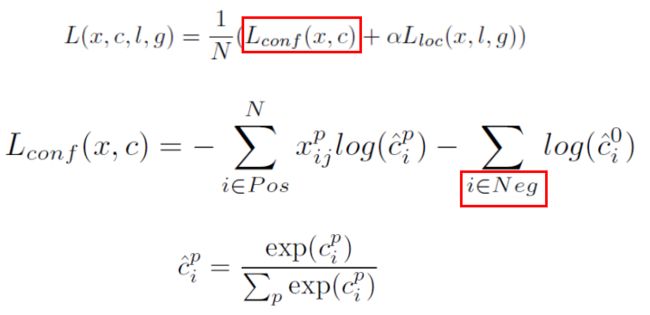
值得注意的是,confidence loss分类里不仅需要考虑正样本,同时也要考虑负样本。
3) Data Augmentation:
为了使得模型对于不同大小、不同形状的物体具有鲁棒性,因此采用了data augmentation。这篇论文在训练时,首先对一张图片进行random crop,然后将其resize的原图尺度,然后以0.5的概率进行水平翻转、同时添加一些色彩变换。
四、Inference
在测试部分,SSD没有什么特殊的地方,过一遍网络,拿到所有层上预测的结果,比如输入一张300x300的图片,会生成 8732*类别数个bounding box,而其中很多bounding box的置信度都非常低。通过confidence threshold设为0.01,过滤掉大多数的boxes。再通过后处理NMS,为每张图片保留置信度最高的200个检测结果,在论文中NMS的IoU设置为0.45。
五、实验
最后,SSD这篇paper中,作者做了相当多的实验,这里就不详细介绍。