leveldb源码剖析--数据写入(DBImpl::Write)
前面我们介绍了leveldb中数据的编码 ,数据在内存中的存储形式(MemTable),数据在磁盘中的存储格式(sstable),以及sstable的形成过程等等。本篇博文将从leveldb用户的角度,详细走一遍leveldb用户写入数据的整个流程。
接口
leveldb对用户提供两个可以写入数据的接口:
Status Write(const WriteOptions& options, WriteBatch* updates);
Status Put(const WriteOptions&, const Slice& key, const Slice& value);这两个参数的形参不一样,第一个是writebatch,第二个是key-value。第二个比较好理解,第一个是什么意思呢?其实顾命思议,writebatch就是批量写入。后面我们将会看到,其实put函数后面也是要用write接口。我们可以跟下去看一下put函数的实现:
DBImpl::Put -> DB::Put -> DBImpl::Write我们下面看一下DB:Put中是怎么把key-value加入到writebatch然后调用write函数的:
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
WriteBatch batch;
batch.Put(key, value);//将key-value加入到writebatch中
return Write(opt, &batch);
}void WriteBatch::Put(const Slice& key, const Slice& value) {
//Count函数计算当前的writebatch中有多少对key-value
//setCount 将当前的键值对数加1,因为这里新加入了一对键值
WriteBatchInternal::SetCount(this, WriteBatchInternal::Count(this) + 1);
//将键值对的type加入到rep末尾
rep_.push_back(static_cast<char>(kTypeValue));
//将键值对(包括他们的长度)加入到rep中
PutLengthPrefixedSlice(&rep_, key);
PutLengthPrefixedSlice(&rep_, value);
}从Writebatch类的实现中我们知道,writebatch空间布局具有如下形式:
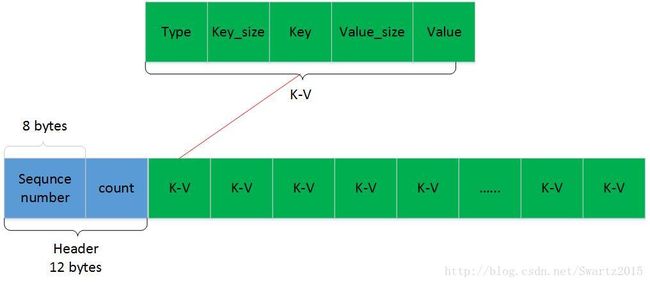
其中count表示这个writebatch中有多少个K-V,sequence number表示writebatch中起始K-V的序列号,它的具体含义我们后面再介绍。
所有write函数是写入的核心。下面我们看一下write函数的实现:
Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) {
Writer w(&mutex_);
w.batch = my_batch;
w.sync = options.sync;
w.done = false;
MutexLock l(&mutex_);
writers_.push_back(&w);这里主要工作是把writebatch放入到一个Writer结构中,这个结构除了记录需要写入的数据writebatch外,还记录了写入的状态等其他管理信息。最后将Writer放入到writers_中,Writers_是一个双端队列-deque。这里需要加锁,主要是因为leveldb支持多线程,因此为了保护writers_结构,需要加一个互斥锁。
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
if (w.done) {
return w.status;
}这里其实就是用条件变量实现了生产者和消费者模式。而且不用额外开启别的线程做消费者,而是直接用一个生产者线程当消费者。回忆一下生产者消费者模型:

Writers_相当于一个任务队列,生产者线程不断向任务队列中添加待处理的任务。一般计算模型是将消费者和生产者分开,也就是这里另开线程处理任务。但是leveldb选择从生产者线程中找一个线程来处理任务。问题在于选择哪个生产者作为消费者线程。
从上面代码中我们可以知道,每个生产者在向Writers_队列中添加任务之后,都会进入一个while循环,然后在里面睡眠,只有当这个生产者所加入的任务位于队列的头部或者该线程加入的任务已经被处理(即writer.done == true),线程才会被唤醒,这里需要注意,线程被唤醒后会继续检查循环条件,如果满足条件还会继续睡眠。这里分两种情况:
- 所加入的任务被处理
- 所加入的任务排在了队列的头部
对于第一种情况,线程退出循环后直接返回。对于第二种情况,leveldb将这个生产者选为消费者。然后让它进行后面的处理。为什么选择第一种情况下的生产者作为消费者呢?这主要是为了保证每次只有一个消费者对writers_队列进行处理。因为不管在什么情况下,只会有一个生产者线程的任务放在队列头部,但是有可能一个时间会有多个生产者线程的任务被处理掉。
下面我们看一下生产者变为消费者后,它是怎么处理任务的:
Status status = MakeRoomForWrite(my_batch == NULL);
uint64_t last_sequence = versions_->LastSequence();
Writer* last_writer = &w;前面我们曾经说过,leveldb首先将数据写入内存中的MemTable,然后再将MemTable写盘生成sstable。这里的MakeRoomForWrite就是检查内存中的Memtable是否有足够的空间可供写。last_sequence记录的是leveldb中已经写入的数据的最大序列号,
if (status.ok() && my_batch != NULL) {
WriteBatch* updates = BuildBatchGroup(&last_writer); 顾名思义这里就是将生产者队列中的所有任务组合成一个大的任务。结合这里的场景,就是将所有任务中的writebatch,组合在一起形成一个包含所有writebatch的K-V的大的writebatch——updates,因此,BuildBatchGroup函数里面会遍历当前writers_中的所有Writer,并将他们组合。
WriteBatchInternal::SetSequence(updates, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(updates);结合这里,我们就可以解释一直以来的sequence number(序列号)的具体含义了。之前说过,Count函数返回writebatch中的key-value对数,因此sequence number记录的就是当前加入leveldb中的键值对个数,每个键值对都会对应一个序列号,而且是独一无二的。last_sequence一如既往,记录当前的最大序列号。
mutex_.Unlock();
status = log_->AddRecord(WriteBatchInternal::Contents(updates)); // 写日志
bool sync_error = false;
if (status.ok() && options.sync) {
status = logfile_->Sync();
if (!status.ok()) {
sync_error = true;
}
}下面这部分是写日志,这是一种保护措施,后面我们再详细介绍。
if (status.ok()) {
status = WriteBatchInternal::InsertInto(updates, mem_);
}这里就是向内存中的MemTable添加数据了。这个函数把updates里面的所有K-V添加到Memtable中,当然,sequence number也会融合在key里面,回顾之前的博文就可以清楚了。这个地方是不加锁的,因此虽然InsertInto可能会执行较长时间,但是它也不会影响其他生产者线程向队列中添加任务
mutex_.Lock();
if (sync_error) {
// The state of the log file is indeterminate: the log record we
// just added may or may not show up when the DB is re-opened.
// So we force the DB into a mode where all future writes fail.
RecordBackgroundError(status);
}
}
if (updates == tmp_batch_) tmp_batch_->Clear();
versions_->SetLastSequence(last_sequence);
}这部分就是一些错误处理,以及设置last_sequence了。没什么好说的。
while (true) {
Writer* ready = writers_.front();
writers_.pop_front();
if (ready != &w) {
ready->status = status;
ready->done = true;
ready->cv.Signal();
}
if (ready == last_writer) break;
}这部分代码是呼应最开始时的while循环里面的条件变量等待。前面虽然该消费者线程已经将任务都处理完了(添加到Memtable中)。但是任务并没有从队列中删除,这个while循环就是将已经处理的任务从队列中移除的过程,同时还会通知相应任务的生产者线程说明它所添加的任务已经处理完毕了(通过设置writer.done标记位),可以直接返回了,结合前面的while循环看一下还是很简单的。
if (!writers_.empty()) {
writers_.front()->cv.Signal();
}最后这行代码也是和前面的while等待相呼应。它会唤醒在队列头等待的生产者线程,这个线程会充当下一轮的消费者。
总结
这篇博文主要介绍了leveldb将数据写入Memtable中的流程。有一些关键的地方没有作介绍。但总体上我们了解了写入数据时的生产者消费者模型,sequence number等的实现。我们可以看到,leveldb采用的是批量写入的方法,而不是每来一个key-value就写入一次。当然这里的写入主要还是写入内存中的Memtable中。后面我们将会介绍MakeRoomForWrite,详细了解当内存中的Memtable已经没有空间可写时,leveldb是怎么处理的。