Linux缓存回写——基于linux-4.15
这也是刚看,仅供参考~
1、Linux内核bdi系统
bdi是backing device info的缩写,它用于描述后端存储(如磁盘)设备相关的信息。相对于内存来说,后端存储的I/O比较慢,因此写盘操作需要通过page cache进行缓存延迟写入。
与bdi_writeback机制相关的主要数据结构有三个:
1)backing_dev_info:该数据结构描述了backing_dev的所有信息,通常块设备的request queue中会包含backing_dev对象。
2)bdi_writeback:该数据结构封装了writeback的内核线程以及需要操作的inode队列。
3)wb_writeback_work:该数据结构封装了writeback的工作任务。
在include/linux/backing-dev-defs.h中定义了前两个结构。
1.1 backing_dev_info
其中backing_dev_info结构定义如下:
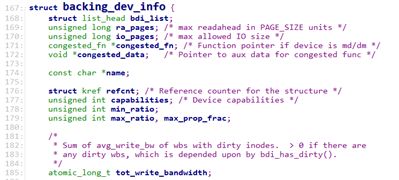
struct backing_dev_info {
struct list_head bdi_list;
unsigned long ra_pages; /* max readahead in PAGE_CACHE_SIZE units */
unsigned int capabilities; /* Device capabilities */
congested_fn *congested_fn; /* Function pointer if device is md/dm */
void *congested_data; /* Pointer to aux data for congested func */
char *name;
unsigned int min_ratio;
unsigned int max_ratio, max_prop_frac;
atomic_long_t tot_write_bandwidth;
struct bdi_writeback wb; /* the root writeback info for this bdi */
struct list_head wb_list; /* list of all wbs */
#ifdef CONFIG_CGROUP_WRITEBACK
struct radix_tree_root cgwb_tree; /* radix tree of active cgroup wbs */
struct rb_root cgwb_congested_tree; /* their congested states */
atomic_t usage_cnt; /* counts both cgwbs and cgwb_contested's */
#else
struct bdi_writeback_congested *wb_congested;
#endif
wait_queue_head_t wb_waitq;
struct device *dev;
struct timer_list laptop_mode_wb_timer;
#ifdef CONFIG_DEBUG_FS
struct dentry *debug_dir;
struct dentry *debug_stats;
#endif
};
1.2 bdi_writeback
bdi_writeback对象封装了需要处理的inode队列。当page cache/buffer cache需要刷新radix tree上的inode时,可以将该inode挂载到writeback对象的b_dirty队列上,然后唤醒writeback线程。在处理过程中,inode会被移到b_io队列上进行处理。
bdi_writeback定义如下:
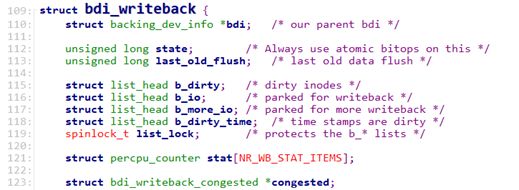
struct bdi_writeback {
struct backing_dev_info *bdi; /* our parent bdi */
unsigned long state; /* Always use atomic bitops on this */
unsigned long last_old_flush; /* last old data flush */
struct list_head b_dirty; /* dirty inodes */
struct list_head b_io; /* parked for writeback */
struct list_head b_more_io; /* parked for more writeback */
struct list_head b_dirty_time; /* time stamps are dirty */
spinlock_t list_lock; /* protects the b_* lists */
struct percpu_counter stat[NR_WB_STAT_ITEMS];
struct bdi_writeback_congested *congested;
unsigned long bw_time_stamp; /* last time write bw is updated */
unsigned long dirtied_stamp;
unsigned long written_stamp; /* pages written at bw_time_stamp */
unsigned long write_bandwidth; /* the estimated write bandwidth */
unsigned long avg_write_bandwidth; /* further smoothed write bw, > 0 */
unsigned long dirty_ratelimit;
unsigned long balanced_dirty_ratelimit;
struct fprop_local_percpu completions;
int dirty_exceeded;
spinlock_t work_lock; /* protects work_list & dwork scheduling */
struct list_head work_list;
struct delayed_work dwork; /* work item used for writeback */
struct list_head bdi_node; /* anchored at bdi->wb_list */
#ifdef CONFIG_CGROUP_WRITEBACK
struct percpu_ref refcnt; /* used only for !root wb's */
struct fprop_local_percpu memcg_completions;
struct cgroup_subsys_state *memcg_css; /* the associated memcg */
struct cgroup_subsys_state *blkcg_css; /* and blkcg */
struct list_head memcg_node; /* anchored at memcg->cgwb_list */
struct list_head blkcg_node; /* anchored at blkcg->cgwb_list */
union {
struct work_struct release_work;
struct rcu_head rcu;
};
#endif
};
1.3 wb_writeback_work
在fs/fs-writeback.c中定义了wb_writeback_work结构体,该数据结构封装了writeback的工作任务,其内容如下:
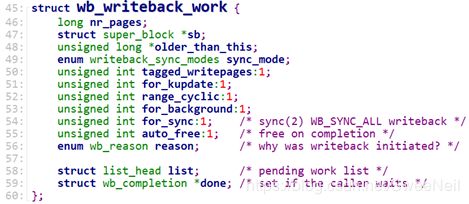
struct wb_writeback_work {
long nr_pages;
struct super_block *sb;
unsigned long *older_than_this;
enum writeback_sync_modes sync_mode;
unsigned int tagged_writepages:1;
unsigned int for_kupdate:1;
unsigned int range_cyclic:1;
unsigned int for_background:1;
unsigned int for_sync:1; /* sync(2) WB_SYNC_ALL writeback */
unsigned int auto_free:1; /* free on completion */
enum wb_reason reason; /* why was writeback initiated? */
struct list_head list; /* pending work list */
struct wb_completion *done; /* set if the caller waits */
};
wb_writeback_work数据结构是对writeback任务的封装,不同的任务可以采用不同的刷新策略。writeback线程的处理对象就是wb_writeback_work。如果writeback_work队列为空,那么内核线程就可以睡眠。
nr_pages:待回写页面数量;
sb: 该 writeback 任务所属的 super_block;
for_background: 若值为 1,表示后台回写;否则值为 0;
1.4 bdi-default内核线程
1.4.1 default_bdi_init
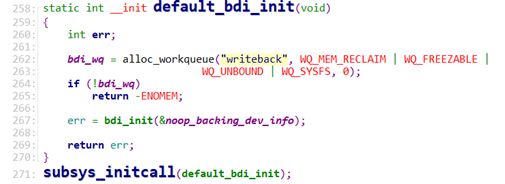
Linux内核启动时,会执行bdi模块default_bdi_init(),代码定义在文件mm/backing-dev.c中。主要工作如下:
1)创建名为writeback的线程,此线程由定时器来唤醒。
2)调用bdi_init,定义默认数据结构noop_backing_dev_info。

1.4.2 bdi_init
初始化bdi,其内容定义在mm/backing-dev.c中,内容如下:
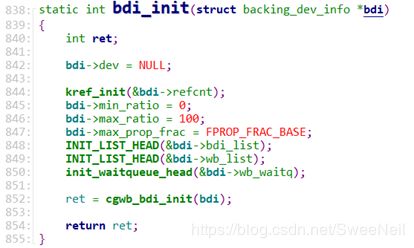
1.4.3 cgwb_bdi_init
cgwb_bdi_init有两个接口,都定义在mm/backing-dev.c下:
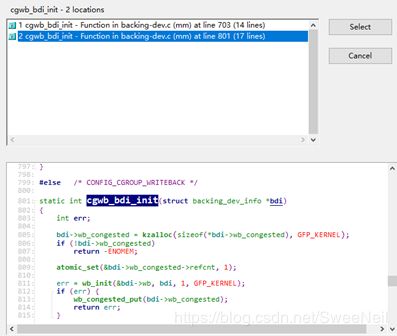
这两个接口中都调用了wb_init,整个调用流程如下:
内核启动
——default_bdi_init
————bdi_init
——————cgwb_bdi_init
————————wb_init
接下来进行第二部分分析。
2、delayed_work接口
writeback是通过delayed_work来实现的,在wb_init()函数里初始化了这个delayed_work。
2.1 wb_init()
wb_init()函数,定义在mm/backing-dev.c中,其内容如下:
![]()
static int wb_init(struct bdi_writeback *wb, struct backing_dev_info *bdi,int blkcg_id, gfp_t gfp)
{
int i, err;
memset(wb, 0, sizeof(*wb));
if (wb != &bdi->wb)
bdi_get(bdi);
wb->bdi = bdi;
wb->last_old_flush = jiffies;
INIT_LIST_HEAD(&wb->b_dirty);
INIT_LIST_HEAD(&wb->b_io);
INIT_LIST_HEAD(&wb->b_more_io);
INIT_LIST_HEAD(&wb->b_dirty_time);
spin_lock_init(&wb->list_lock);
wb->bw_time_stamp = jiffies;
wb->balanced_dirty_ratelimit = INIT_BW;
wb->dirty_ratelimit = INIT_BW;
wb->write_bandwidth = INIT_BW;
wb->avg_write_bandwidth = INIT_BW;
spin_lock_init(&wb->work_lock);
INIT_LIST_HEAD(&wb->work_list);
INIT_DELAYED_WORK(&wb->dwork, wb_workfn);
wb->dirty_sleep = jiffies;
wb->congested = wb_congested_get_create(bdi, blkcg_id, gfp);
if (!wb->congested) {
err = -ENOMEM;
goto out_put_bdi;
}
err = fprop_local_init_percpu(&wb->completions, gfp);
if (err)
goto out_put_cong;
for (i = 0; i < NR_WB_STAT_ITEMS; i++) {
err = percpu_counter_init(&wb->stat[i], 0, gfp);
if (err)
goto out_destroy_stat;
}
return 0;
out_destroy_stat:
while (i--)
percpu_counter_destroy(&wb->stat[i]);
fprop_local_destroy_percpu(&wb->completions);
out_put_cong:
wb_congested_put(wb->congested);
out_put_bdi:
if (wb != &bdi->wb)
bdi_put(bdi);
return err;
}
其中比较重要的是:INIT_DELAYED_WORK(&wb->dwork, wb_workfn);
2.2 wb_workfn()
在wb_workfn()会wakeup这个delayed_work,来实现周期性的writeback。进入到wb_workfn函数中,查看其内容。wb_workfn()函数定义在fs/fs-writeback.c文件中。
void wb_workfn(struct work_struct *work)
{
struct bdi_writeback *wb = container_of(to_delayed_work(work),
struct bdi_writeback, dwork);
long pages_written;
set_worker_desc("flush-%s", dev_name(wb->bdi->dev));
current->flags |= PF_SWAPWRITE;
if (likely(!current_is_workqueue_rescuer() ||
!test_bit(WB_registered, &wb->state))) {
do {
pages_written = wb_do_writeback(wb);
trace_writeback_pages_written(pages_written);
} while (!list_empty(&wb->work_list));
} else {
pages_written = writeback_inodes_wb(wb, 1024,
WB_REASON_FORKER_THREAD);
trace_writeback_pages_written(pages_written);
}
if (!list_empty(&wb->work_list))
mod_delayed_work(bdi_wq, &wb->dwork, 0);
else if (wb_has_dirty_io(wb) && dirty_writeback_interval)
wb_wakeup_delayed(wb);
current->flags &= ~PF_SWAPWRITE;
}
在wb_workfn()会wakeup这个delayed_work,来实现周期性的writeback。
2.3 wb_do_writeback()
wb_do_writeback()函数,定义在fs/fs-writeback.c中,其内容如下:
static long wb_do_writeback(struct bdi_writeback *wb)
{
struct wb_writeback_work *work;
long wrote = 0;
set_bit(WB_writeback_running, &wb->state);
while ((work = get_next_work_item(wb)) != NULL) {
struct wb_completion *done = work->done;
trace_writeback_exec(wb, work);
wrote += wb_writeback(wb, work);
if (work->auto_free)
kfree(work);
if (done && atomic_dec_and_test(&done->cnt))
wake_up_all(&wb->bdi->wb_waitq);
}
wrote += wb_check_old_data_flush(wb);
wrote += wb_check_background_flush(wb);
clear_bit(WB_writeback_running, &wb->state);
return wrote;
}
在wb_do_writeback函数中又使用了,wb_check_old_data_flush以及wb_check_background_flush函数。
writeback分以下两种方式:
1. periodic writeback
对应wb_check_old_data_flush();
2. background writeback
对应wb_check_background_flush()。
对于backgroud writeback如果dirty数据超过bg_thresh则进行writeback ,bg_thresh可以通过/proc/sys/vm/dirty_background_bytes或/proc/sys/vm/dirty_background_ratio来设置。
2.4 wb_writeback
wb_check_background_flush和wb_check_old_data_flush的函数只是设置wb_writeback_work的各项参数,然后执行wb_writeback函数,该函数是Writeback机制中真正执行写回的函数。Writeback机制中的写回磁盘操作都是通过wb_writeback函数实现的,wb_writeback调用与文件系统有关的write函数,执行写回磁盘的操作。
wb_writeback函数定义如下所示:
static long wb_writeback(struct bdi_writeback *wb,
struct wb_writeback_work *work)
{
unsigned long wb_start = jiffies;
long nr_pages = work->nr_pages;
unsigned long oldest_jif;
struct inode *inode;
long progress;
struct blk_plug plug;
oldest_jif = jiffies;
work->older_than_this = &oldest_jif;
blk_start_plug(&plug);
spin_lock(&wb->list_lock);
for (;;) {
/*
* Stop writeback when nr_pages has been consumed
* 消耗nr_pages时停止回写
*/
if (work->nr_pages <= 0)
break;
/*
* Background writeout and kupdate-style writeback may
* run forever. Stop them if there is other work to do
* so that e.g. sync can proceed. They'll be restarted
* after the other works are all done.
* 后台写出和kupdate风格的回写可能会永远运行。
* 如果还有其他工作需要进行,可以停止它们,例如同步可以执行。
* 在完成其他工作后,它们将重新启动。
*/
if ((work->for_background || work->for_kupdate) &&
!list_empty(&wb->work_list))
break;
/*
* For background writeout, stop when we are below the
* background dirty threshold
* 对于后台写入,当我们低于后台脏阈值时停止
*/
if (work->for_background && !wb_over_bg_thresh(wb))
break;
/*
* Kupdate and background works are special and we want to
* include all inodes that need writing. Livelock avoidance is
* handled by these works yielding to any other work so we are
* safe.
* Kupdate和后台工作很特别,我们希望包含所有需要编写的inode。
* 活锁避免是通过这些工作处理任何其他工作,所以我们是安全的。
*/
if (work->for_kupdate) {
oldest_jif = jiffies -
msecs_to_jiffies(dirty_expire_interval * 10);
} else if (work->for_background)
oldest_jif = jiffies;
trace_writeback_start(wb, work);
if (list_empty(&wb->b_io))
queue_io(wb, work);
if (work->sb)
progress = writeback_sb_inodes(work->sb, wb, work);
else
progress = __writeback_inodes_wb(wb, work);
trace_writeback_written(wb, work);
wb_update_bandwidth(wb, wb_start);
/*
* Did we write something? Try for more
* 我们写了什么吗? 尝试更多
*
* Dirty inodes are moved to b_io for writeback in batches.
* The completion of the current batch does not necessarily
* mean the overall work is done. So we keep looping as long
* as made some progress on cleaning pages or inodes.
* 脏的inode被移动到b_io以便批量回写,完成当前批次并不一定意味着整体工
作已经完成。
* 因此,只要在清理页面或inode上取得一些进展,我们就会继续循环。
*/
if (progress)
continue;
/*
* No more inodes for IO, bail
* 没有更多的inode需要IO ,保释
*/
if (list_empty(&wb->b_more_io))
break;
/*
* Nothing written. Wait for some inode to
* become available for writeback. Otherwise
* we'll just busyloop.
* 如果没有什么要写的,就等待一些需要回写的inode,否则函数只会一直忙碌。
*/
if (!list_empty(&wb->b_more_io)) {
trace_writeback_wait(wb, work);
inode = wb_inode(wb->b_more_io.prev);
spin_lock(&inode->i_lock);
spin_unlock(&wb->list_lock);
/* This function drops i_lock...
这个函数丢了i_lock ... */
inode_sleep_on_writeback(inode);
spin_lock(&wb->list_lock);
}
}
spin_unlock(&wb->list_lock);
blk_finish_plug(&plug);
return nr_pages - work->nr_pages;
}
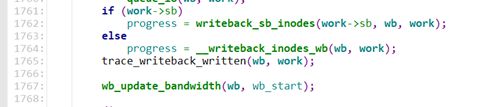
若定义了回写任务中的 work‐>sb,则表示只回写该 superblock 下面的脏 inodes,不管是否回写指定 superblock 下面的 inodes,最终都会调用 writeback_inodes_wb()来执行写操作。
2.5 writeback_sb_inodes
writeback_sb_inode函数定义在fs/writeback.c中,其内容如下:
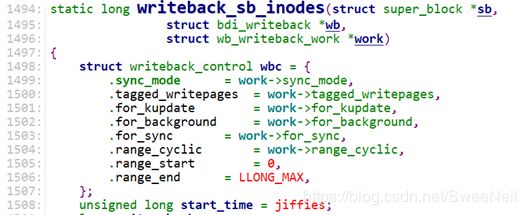
static long writeback_sb_inodes(struct super_block *sb,
struct bdi_writeback *wb,
struct wb_writeback_work *work)
{
struct writeback_control wbc = {
.sync_mode = work->sync_mode,
.tagged_writepages = work->tagged_writepages,
.for_kupdate = work->for_kupdate,
.for_background = work->for_background,
.for_sync = work->for_sync,
.range_cyclic = work->range_cyclic,
.range_start = 0,
.range_end = LLONG_MAX,
};
unsigned long start_time = jiffies;
long write_chunk;
long wrote = 0; /* count both pages and inodes */
while (!list_empty(&wb->b_io)) {
struct inode *inode = wb_inode(wb->b_io.prev);
struct bdi_writeback *tmp_wb;
if (inode->i_sb != sb) {
if (work->sb) {
redirty_tail(inode, wb);
continue;
}
break;
}
spin_lock(&inode->i_lock);
if (inode->i_state & (I_NEW | I_FREEING | I_WILL_FREE)) {
spin_unlock(&inode->i_lock);
redirty_tail(inode, wb);
continue;
}
if ((inode->i_state & I_SYNC) && wbc.sync_mode != WB_SYNC_ALL) {
spin_unlock(&inode->i_lock);
requeue_io(inode, wb);
trace_writeback_sb_inodes_requeue(inode);
continue;
}
spin_unlock(&wb->list_lock);
if (inode->i_state & I_SYNC) {
/* Wait for I_SYNC. This function drops i_lock... */
inode_sleep_on_writeback(inode);
/* Inode may be gone, start again */
spin_lock(&wb->list_lock);
continue;
}
inode->i_state |= I_SYNC;
wbc_attach_and_unlock_inode(&wbc, inode);
write_chunk = writeback_chunk_size(wb, work);
wbc.nr_to_write = write_chunk;
wbc.pages_skipped = 0;
__writeback_single_inode(inode, &wbc);
wbc_detach_inode(&wbc);
work->nr_pages -= write_chunk - wbc.nr_to_write;
wrote += write_chunk - wbc.nr_to_write;
if (need_resched()) {
blk_flush_plug(current);
cond_resched();
}
tmp_wb = inode_to_wb_and_lock_list(inode);
spin_lock(&inode->i_lock);
if (!(inode->i_state & I_DIRTY_ALL))
wrote++;
requeue_inode(inode, tmp_wb, &wbc);
inode_sync_complete(inode);
spin_unlock(&inode->i_lock);
if (unlikely(tmp_wb != wb)) {
spin_unlock(&tmp_wb->list_lock);
spin_lock(&wb->list_lock);
}
if (wrote) {
if (time_is_before_jiffies(start_time + HZ / 10UL))
break;
if (work->nr_pages <= 0)
break;
}
}
return wrote;
}
在函数writeback_sb_inodes中使用了结构体,writeback_control,该结构体定义在include/linux/writeback.h中,其内容如下:

struct writeback_control {
long nr_to_write; /* Write this many pages, and decrementthis for each page written */
long pages_skipped; /* Pages which were not written */
/*
* For a_ops->writepages(): if start or end are non-zero then this is
* a hint that the filesystem need only write out the pages inside that
* byterange. The byte at `end' is included in the writeout request.
*/
loff_t range_start;
loff_t range_end;
enum writeback_sync_modes sync_mode;
unsigned for_kupdate:1; /* A kupdate writeback */
unsigned for_background:1; /* A background writeback */
unsigned tagged_writepages:1; /* tag-and-write to avoid livelock */
unsigned for_reclaim:1; /* Invoked from the page allocator */
unsigned range_cyclic:1; /* range_start is cyclic */
unsigned for_sync:1; /* sync(2) WB_SYNC_ALL writeback */
#ifdef CONFIG_CGROUP_WRITEBACK
struct bdi_writeback *wb; /* wb this writeback is issued under */
struct inode *inode; /* inode being written out */
/* foreign inode detection, see wbc_detach_inode() */
int wb_id; /* current wb id */
int wb_lcand_id; /* last foreign candidate wb id */
int wb_tcand_id; /* this foreign candidate wb id */
size_t wb_bytes; /* bytes written by current wb */
size_t wb_lcand_bytes; /* bytes written by last candidate */
size_t wb_tcand_bytes; /* bytes written by this candidate */
#endif
};
writeback_control结构中重要的成员变量如下:
sync_mode:指定同步模式,WB_SYNC_ALL表示当遇到锁住的inode时,它必须等待该inode解锁,而不能跳过。WB_SYNC_NONE表示跳过被锁住的inode;
nr_to_write:要回写的脏页数量;
pages_skipped:跳过回写的页面数量;
for_kupdated: 若值为1,则表示回写操作是周期性的机制;否则值为0;
for_background: 若值为1,表示后台回写;否则值为0;
……

在writeback_sb_inodes中,函数依次从wb->b_io链表中取出脏inode,判断inode是否需要回写。如需要回写,则调用writeback_single_inode()完成回写;否则,将其添加到某个链表中或返回。

首先检查 bdi_writeback任务上的inode 所属的superblock是否与传递进来的superblock一致。若参数中指定必须回写属于某个文件系统的脏 inode,那么通过 redirty_tail()将该inode 重新弄脏,redirty_tail()会修改 inode 弄脏的时间并将其添加到 dirty 链表的头部,然后继续下一次循环。
若不一致,说明该 inode 属于另外一个 superblock。若参数中并未指定一定回写属于某个文件系统(superblock)的脏 inode,那么直接向调用者返回 0。
接下来判断inode是否确认需要被回写,如果此inode被锁定以进行回写,并且我们没有执行writeback-for-data-integrity,则将其移至b_more_io,以便可以使用s_io上的其他inode继续写回。……
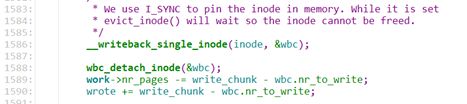
之后就是使用__writeback_single_inode来来回写inode上的脏页面。
2.6 __writeback_inodes_wb
writeback_inodes_wb()函数定义在文件fs/fs-writeback.c中,其内容如下:
static long __writeback_inodes_wb(struct bdi_writeback *wb,
struct wb_writeback_work *work)
{
unsigned long start_time = jiffies;
long wrote = 0;
while (!list_empty(&wb->b_io)) {
struct inode *inode = wb_inode(wb->b_io.prev);
struct super_block *sb = inode->i_sb;
if (!trylock_super(sb)) {
/*
* trylock_super() may fail consistently due to
* s_umount being grabbed by someone else. Don't use
* requeue_io() to avoid busy retrying the inode/sb.
* trylock_super()可能会因为其他thread获取了s_umount而一直失败。
不要使用requeue_io(),避免繁忙重试inode / sb。
*/
redirty_tail(inode, wb);
continue;
}
wrote += writeback_sb_inodes(sb, wb, work);
up_read(&sb->s_umount);
/* refer to the same tests at the end of writeback_sb_inodes */
if (wrote) {
if (time_is_before_jiffies(start_time + HZ / 10UL))
break;
if (work->nr_pages <= 0)
break;
}
}
/* Leave any unwritten inodes on b_io */
return wrote;
}
2.7 __writeback_single_inode
__writeback_single_inode()函数主要任务就是将某个inode下的脏页回写到存储上,代码实现在fs/fs-writeback.c文件中。
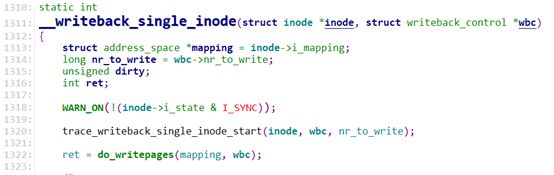
__writeback_single_inode函数写出一个inode及其脏页,不更新回写列表链接,这留给了调用者(writeback_sb_inodes),同时调用者还负责设置I_SYNC标志并调用inode_sync_complete()来清除它。
在写回元数据之前确保收到了data.这对于文件系统通过数据I/O完成修改元数据至关重要。函数不为sync做 writeback,因为它还有一个单独的外部IO 完成路径以及sync_fs来保证inode 元数据被正确地写回。
其中最重要的函数就是do_writepages,使用该函数来进行写回。
2.8 do_writepages
do_writepages定义在文件mm/page-writeback.c中:
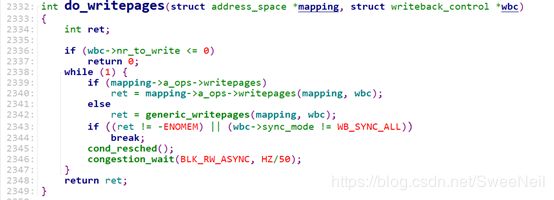
do_writepages()函数简单封装a_ops->writepages()或generic_writepages()。ext4文件系统中定义了相应的writepages方法ext4_writepages()
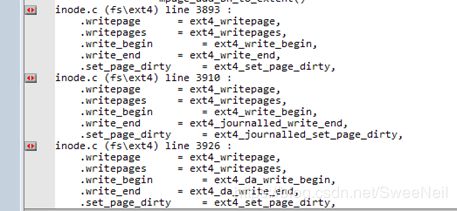
2.9 ext4_writepages
ext4_writepages定义在fs/ext4/inode.c文件中:
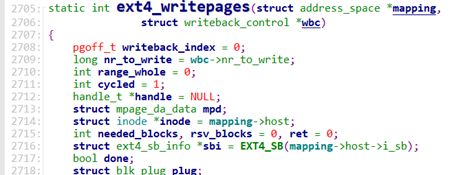
ext4_writepages将一个页写回磁盘,但是该函数实在太长了,逐步开始分析。

如果需要做日志,那么write_cache_pages。

如果文件系统崩溃了,它会变成只读模式,立即返回函数调用栈以清晰地表明产生问题的真实原因,内核开发人员尝试使用了EXT4_MF_FS_ABORTED来代替sb->s_flag’s SB_RDONLY,因为如果文件系统mounted为read-only后者需要被置为true,在这种情况下,ext4_writepages永远不会被调用,所以如果发生这种情况,我们会想要堆栈跟踪。

wb_init
——wb_workfn
————wb_do_writeback
——————wb_writeback
————————writeback_sb_inodes
————————__writeback_inodes_wb
——————————writeback_sb_inodes
————————————__writeback_single_inode
——————————————do_writepages
————————————————generic_writepages
————————————————ext4_writepages
参考文献
1、Linux内核延迟写机制. http://ilinuxkernel.com/?p=1578
2、Page Cache之writeback. https://blog.csdn.net/gami1226/article/details/80150764