Python读取txt文件数据(用于接口自动化参数化数据)
小试牛刀:
1.需要python如何读取文件
2.需要python操作list
3.需要使用split()对字符串进行分割
代码运行截图 :
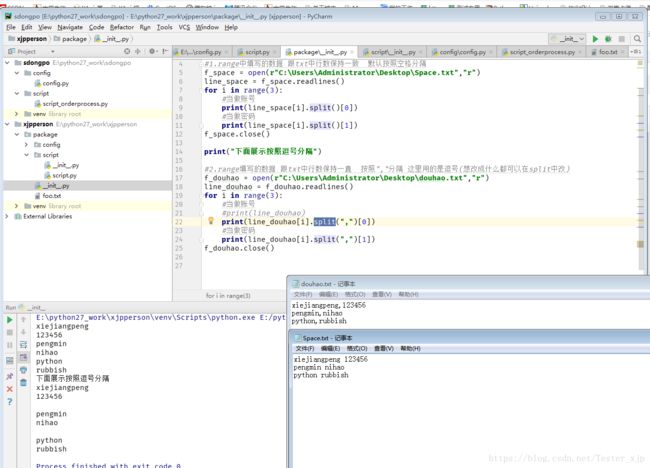
代码(copy)
#encoding=utf-8
#1.range中填写的数据 跟txt中行数保持一致 默认按照空格分隔
f_space = open(r"C:\Users\Administrator\Desktop\Space.txt","r")
line_space = f_space.readlines()
for i in range(3):
#当做账号
print(line_space[i].split()[0])
#当做密码
print(line_space[i].split()[1])
f_space.close()
print("下面展示按照逗号分隔")
#2.range填写的数据 跟txt中行数保持一直 按照","分隔 这里用的是逗号(想改成什么都可以在split中改)
f_douhao = open(r"C:\Users\Administrator\Desktop\douhao.txt","r")
line_douhao = f_douhao.readlines()
for i in range(3):
#当做账号
#print(line_douhao)
print(line_douhao[i].split(",")[0])
#当做密码
print(line_douhao[i].split(",")[1])
f_douhao.close()
当然你可能觉得这样并没啥问题了,好,下面我们在看一个问题
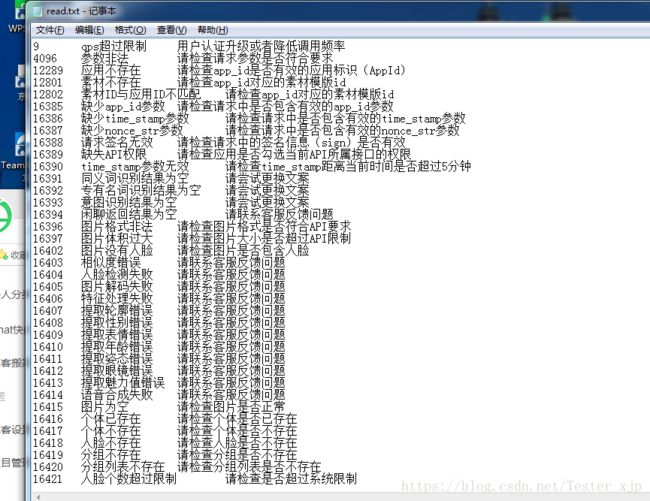
小便再一次学习汇总,需要将在这个txt文本文档中,的错误码对应的内容,存到一个dict中(第一列当key,后面二列当value)
但是继续使用Python2.7版本,就恼火了,直接字符串读出来的乱码了
先粘贴一份原始代码
#coding=utf-8
import sys
f_space = open("C:\\Users\\xjp\\Desktop\\read.txt","r")
line_space = f_space.readlines()
print("当前python版本为:"+str(sys.version))
dictnum={}
for i in range(0,len(line_space)):
dictnum[line_space[i].split()[0]]=line_space[i].split()[1]+line_space[i].split()[2]
print(dictnum)
运行如下
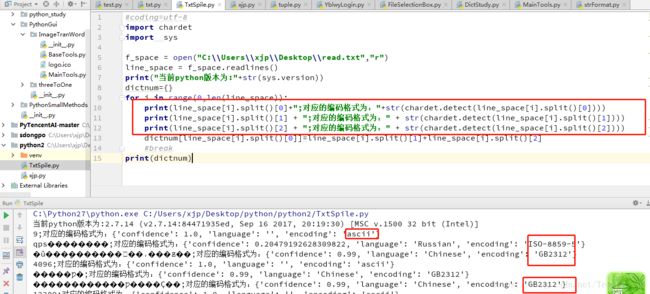
将读取的字符串打印了一下编码,发现编码格式根据数据,和中文,这个字符有不同的格式,下面就介绍一下解决方式(在python代码中将这些编码格式改成utf-8可以,但是那样很繁琐)
我们只需要打开文件,另存为,选择utf-8的编码格式就行了,再次运行软件,我们发现,真的恢复了。而且编码格式都恢复成了utf-8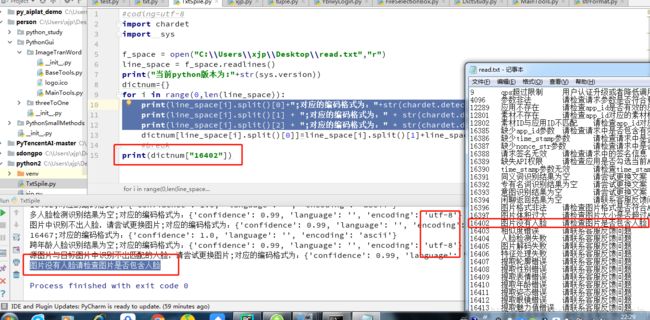
可是,这里面其实还是隐藏着一个问题,看下图
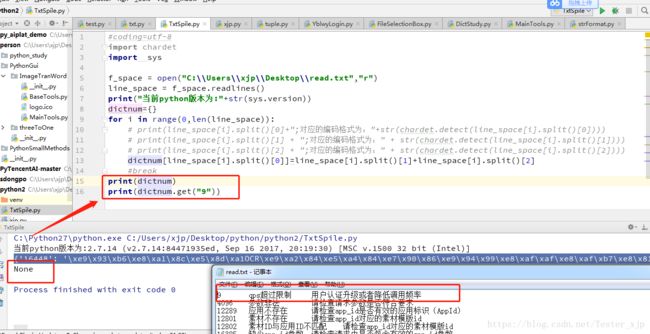
这个时候,只有第一行数据对应的key是找不到value值的,这个具体原因是因为第一行一般是用于bom声明编码变量的,所以我们如果是使用python2.7版本的时候,可以直接跳过第一行,从第二行开始读取。
另外其他的值,存进了字典,打印整个字典也是出现乱码,但是使用key取值,却没有什么问题。
在这里,如果你是python3.x版本,由于是unicode的编码,所以你读取中文和英文的时候,都不会出现啥问题,对于字符编码来说python3.x确实有时候可以免去很多问题。