Python内置库与第三方库
文章目录
- 1. 模块
- 1.1 内置模块
- 1.2 第三方模块
- 1.3 自定义模块
- 1.4 模块的定义
- 1.5 模块的导入
- 2. 内置模块
- 2.1 sys
- 2.2 os
- 2.3 json
- 2.4 pickle
- 2.5 shutil
- 2.6 time
- 2.7 datetime
- 2.8 logging
- 2.9 md5加密
- 2.10 getpass
- 2.11 csv
- 2.12 timeit
- 2.13 random
- 2.14 csv
- 3. 第三方模块
- 3.1 第三方模块的安装
- 3.2 jieba
- 3.3 pyInstaller
- 3.4 virtualenv
- 3.5 multiprocessing
- 3.6 wordcloud
1. 模块
模块可以是一个python文件也可以是文件夹。
1.1 内置模块
python模块内部提供的功能
# coding:utf-8
import sys
print(sys.argv)
1.2 第三方模块
安装:pip/pip3 install 需要安装的模块 [https://pypi.org/]
1.3 自定义模块
自己创建文件或者文件夹(这个文件夹也可以称为包,包中有 _ _ init _ _.py文件)
'''
自定义模块
'''
# coding:utf-8
def f1():
print('f1')
def f2():
print('f2')
'''
调用自定义模块
'''
# coding:utf-8
import modules
modules.f1()
modules.f2()
'''
f1
f2
'''
1.4 模块的定义
定义一个模块时,可以把一个一个python文件或一个文件夹(包)当作一个模块,放方便以后其它python文件调用。
注意:对包的定义,python2中必须要有_ _ init _ _.py文件;python3中不需要这个文件。不论python2还是python3都要加上这个文件。
1.5 模块的导入
① 模块导入方式一:import 模块,模块.函数
# 导入模块,加载此模块中所有值到内存(执行requests.py文件并加载到内存)
import requests # 执行requests.py文件并加载到内存
② 模块导入方式二:from 模块 import 函数或者*,函数
from time import time
from time import strftime
from time import time, strftime(推荐用这种,减少代码量)
from time import * # 导入所有功能
③ 模块导入方式三:from 模块 import 函数 as 别名,别名
模块导入方式二可能会出县如下问题:
from time import time
def time(): # 自己写的time函数把导入的time函数覆盖
print('kiku')
time()
可以给导入的模块起别名:from time import time as t
注意:如果存在包,可以采用下面的导入方式:
from xxx.xx import x
import xxx.xx.x
xxx是包(文件夹),xx是python文件,x是函数。
④ 相对导入
示例一:
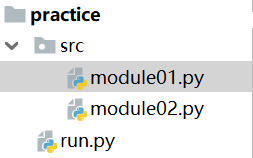
run.py
from src import module01
if __name__ == '__main__':
module01.foo()
module01.py
from . import module02
def foo():
print('module01')
module02.foo()
module02.py
def foo():
print('module02')
示例二:

run.py
import module01
if __name__ == '__main__':
module01.foo()
module01.py
from . import module02
def foo():
print('module01')
module02.foo()
module02.py
def foo():
print('module02')
使用from . import module02报错:ImportError: attempted relative import with no known parent package,相对导入至少需要两个python文件在同一个包中。如:


⑤ 模块导入总结
- 模块和要执行的python文件在同一目录,需要模块中很多功能时,推荐使用:import 模块
- 除此之外,推荐使用:from 模块 import 模块,模块.函数()
- 除此之外,推荐使用:from 模块.模块 import 函数,函数()
⑥ 导入模块练习题
练习一:运行某个脚本(python文件),python文件所在的目录会被放到sys.path中。

run.py:
'''
运行的使run.py文件,会将E:\pycharmProjects\practice\lib路径加入到sys.path中,所以lib目录下的文件,可以直接导入
'''
import client
'''
client module!
'''
client.py:
print('client module!')
- 练习二
目录结构:

run.py:
'''
如果要在run.py中导入test.py模块
'''
import os
print(__file__) # __file__是当前运行脚本所在的路径:E:/pycharmProjects/practice/lib/run.py
v = os.path.dirname(__file__)
print(v) # E:/pycharmProjects/practice/lib
v2 = os.path.dirname(v)
print(v2) # E:/pycharmProjects/practice
import test
'''
E:/pycharmProjects/practice/lib/run.py
E:/pycharmProjects/practice/lib
E:/pycharmProjects/practice
test module!
'''
test.py
print('test module!')
- 练习三
修改runn.py:
print(__file__)
当在run.py所在的文件夹lib中,执行python ./run.py,得到结果是./run.py
。也就是说,__ file __并不是是当前运行脚本所在的路径(在这里纠正练习二中的错误),而只是路径参数。如何解决这个问题?其实,我们可以绝对路径,os.path.abspath()
import os, sys
# print(__file__) # __file__是当前运行脚本所在的路径参数:E:/pycharmProjects/practice/lib/run.py
# print(os.path.abspath(__file__)) # E:\pycharmProjects\practice\lib\run.py
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# print(v) # E:\pycharmProjects\practice
'''
将E:\pycharmProjects\practice加入sys.path中
'''
sys.path.append(BASE_DIR)
import test
'''
test module!
'''
2. 内置模块
2.1 sys
sys模块中包含pthon解释器相关的数据。
① 引用次数
sys.getrefcount():获取一个值的应用计数
''''
sys模块中,pthon解释器相关的数据
获取一个值的应用计数
'''
import sys
a = [1,2,3]
b=a
print(sys.getrefcount(a))
'''
3
'''
② 递归次数
sys.getrecursionlimit():获取python默认支持的递归数量
''''
sys模块中,pthon解释器相关的数据
python默认支持的递归数量
'''
import sys
print(sys.getrecursionlimit())
'''
1000
'''
③ 输出
sys.stdout.write():输出,print函数内部会调用它
''''
输入输出:print函数内部会调用
'''
import sys
# 不能是数字,只能是字符串。默认不换行,print函数内部会调用它。
sys.stdout.write('520')
sys.stdout.write('kiku')
'''
520kiku
'''
进度条的实现
# \n:换行
# \t:制表符
# \r:回到当前行的起始位置
print('thanlon', end='')
print('kiku')
print('thanlon\r', end='')
print('kiku')
'''
thanlonkiku
kiku
'''
# coding:utf-8
'''
使用\r做进度条
'''
import time
for i in range(1, 101):
msg = '%s%%\r' % i
print(msg, end='')
time.sleep(0.05)
'''
100%
'''
\r的应用:进度条的实现(读文件)
# coding:utf-8
'''
进度条
'''
import os
# 读取文件的大小(字节大小)
file_size = os.stat('video.mp4').st_size
# 一点一点读文件
read_size = 0
with open('video.mp4', mode='rb') as f1, open('tmp.mp4', mode='wb')as f2:
while read_size < file_size:
chunk = f1.read(1024) # 每次最多读取1024字节
f2.write(chunk)
read_size += len(chunk)
v = int(read_size / file_size * 100)
print('%s%%\r' % v, end='')

④ 获取用户的执行脚本的路径
sys.argv:获取用户的执行脚本的路径
# coding:utf-8
import sys
print(sys.argv)
'''
['E:/pycharmProjects/untitled/test.py']
'''
# coding:utf-8
'''
让用户执行脚本传入要删除的文件路径,在内部帮助用户将目录删除
'''
import sys
'''
获取用户执行的脚本时,传入参数
如:D:\Python37\python.exe E:/pycharmProjects/untitled/test.py D:/test(参数是“D:/test”)
sys.argv = ['E:/pycharmProjects/untitled/test.py', 'D:/test']
'''
# 获取参数
path = sys.argv[1] # path =D:/test
# 删除文件目录
import shutil
shutil.rmtree(path)
⑤ 模块的查找路径
sys.path:默认python去导入模块,会按照sys.path中的路径依次查找。
import sys
for i in sys.path:
print(i)
'''
'''
E:\pycharmProjects\practice # 执行py文件会向sys.path中添加一个路径,可忽略。D:\Python37\python.exe E:/pycharmProjects/practice/test.py
E:\pycharmProjects\practice # 把当前pycharm中project路径也添加到sys.path中,可忽略。
C:\Program Files\JetBrains\PyCharm 2019.1.3\helpers\pycharm_display
D:\Python37\python37.zip
D:\Python37\DLLs
D:\Python37\lib
D:\Python37
D:\Python37\lib\site-packages
D:\Python37\lib\site-packages\turtle-0.0.2-py3.7.egg
D:\Python37\lib\site-packages\pyyaml-5.1.1-py3.7-win-amd64.egg
C:\Program Files\JetBrains\PyCharm 2019.1.3\helpers\pycharm_matplotlib_backend # pycharm中添加的,忽略
'''
'''
注意内置模块,使用
D:\Python37\python37.zip
D:\Python37\DLLs
D:\Python37\lib
D:\Python37
D:\Python37\lib\site-packages
D:\Python37\lib\site-packages\turtle-0.0.2-py3.7.egg
D:\Python37\lib\site-packages\pyyaml-5.1.1-py3.7-win-amd64.egg
这几个模块,不要把自定义模块(自己写模块)写到这些文件中,python一旦卸载,这些模块也会清除。
如果非要向path中添加路径,可以向path中添加导入模块的路径:
import sys
sys.path.append(r'D:/')
print(sys.path)
2.2 os
① os模块作用
可以获取与操作系统之间的数据
② 文件是否存在
# coding:utf-8
import os
if os.path.exists('E:\pycharmProjects\practice\log.txt'):
print('yes!')
'''
yes!
'''
③ 获取文件的大小
os.stat(‘E:\pycharmProjects\practice\log.txt’).st_size
# coding:utf-8
import os
v = os.stat('E:\pycharmProjects\practice\log.txt').st_size # 字节
print(v) # 9
④ 获取文件的绝对路径
os.path.abspath(path)
# coding:utf-8
import os
path = 'log.txt'
v = os.path.abspath(path)
print(v)
'''
E:\pycharmProjects\practice\log.txt
'''
⑤ 获取文件或目录的上一级目录
os.path.dirname(path)
# coding:utf-8
import os
path = 'E:\pycharmProjects\practice\log.txt'
path2 = 'E:\pycharmProjects\practice\test'
v = os.path.dirname(path) # E:\pycharmProjects\practice
v2 = os.path.dirname(path2) # E:\pycharmProjects\practice
print(v)
print(v2)
'''
E:\pycharmProjects\practice
E:\pycharmProjects
'''
⑥ 路径的拼接
os.path.join(file_name, path)
# coding:utf-8
import os
path = 'E:\pycharmProjects\practice'
file_name = 'log.txt'
res1 = os.path.join(file_name, path) # 注意顺序
res2 = os.path.join(path, file_name)
res3 = os.path.join(path, 'test', file_name)
print(res1)
print(res2)
print(res3)
'''
E:\pycharmProjects\practice
E:\pycharmProjects\practice\log.txt
E:\pycharmProjects\practice\test\log.txt
'''
⑦ 获取一个目录下所有的文件[第一层](面试)
os.listdir(r’E:\pycharmProjects\practice\test’)
# coding:utf-8
import os
res = os.listdir(r'E:\pycharmProjects\practice\test')
print(res) # ['index.html', 'log.txt']
for item in res:
print(item)
'''
index.html
log.txt
'''
⑧ 获取一个目录下所有的文件[所有层](面试)
# coding:utf-8
import os
res = os.walk(r'E:\pycharmProjects\practice')
print(res) # 生成器
# coding:utf-8
import os
res = os.walk(r'E:\pycharmProjects\practice')
for item in res:
print(item)
'''
('E:\\pycharmProjects\\practice', ['.idea', 'test'], ['test.py'])
('E:\\pycharmProjects\\practice\\.idea', [], ['misc.xml', 'modules.xml', 'practice.iml', 'workspace.xml'])
('E:\\pycharmProjects\\practice\\test', [], ['index.html', 'log.txt'])
'''
# coding:utf-8
import os
res = os.walk(r'E:\pycharmProjects\practice')
for a, b, c in res:
'''
a:正在查看的目录
b:此目录下的文件夹
c:此目录下的文件
'''
print(a)
print(b)
print(c)
'''
E:\pycharmProjects\practice
['.idea', 'test']
['test.py']
E:\pycharmProjects\practice\.idea
[]
['misc.xml', 'modules.xml', 'practice.iml', 'workspace.xml']
E:\pycharmProjects\practice\test
[]
['index.html', 'log.txt']
'''
面试题:找到目录中的所有文件(重点)
# coding:utf-8
import os
res = os.walk(r'E:\pycharmProjects\practice')
for a, b, c in res:
'''
a:正在查看的目录
b:此目录下的文件夹
c:此目录下的文件
'''
# print(a)
# print(b)
# print(c)
'''
E:\pycharmProjects\practice
['.idea', 'test']
['test.py']
E:\pycharmProjects\practice\.idea
[]
['misc.xml', 'modules.xml', 'practice.iml', 'workspace.xml']
E:\pycharmProjects\practice\test
[]
['index.html', 'log.txt']
'''
for item in c:
path = os.path.join(a, item)
print(path)
'''
E:\pycharmProjects\practice\test.py
E:\pycharmProjects\practice\.idea\misc.xml
E:\pycharmProjects\practice\.idea\modules.xml
E:\pycharmProjects\practice\.idea\practice.iml
E:\pycharmProjects\practice\.idea\workspace.xml
E:\pycharmProjects\practice\test\index.html
E:\pycharmProjects\practice\test\log.txt
'''
⑨ 补充:字符串转义
v1 = 'E:\pycharmProjects\practice\\nxl'
v2 = r'E:\pycharmProjects\practice\nxl' # 推荐使用
2.3 json
① json简介
json是一个特殊的字符串,与python中的list/dict/str/int/bool很像
② 序列化与反序列化
序列化,将python的值转换为json格式的字符串:
import json
v = [1, 2, 3, 'thanlon', True, {'name': 'thanlon', 'age': 23}]
# 序列化,将python的值转换为json格式的字符串
v2 = json.dumps(v)
print(v2)
'''
[1, 2, 3, "thanlon", true, {"name": "thanlon", "age": 23}]
'''
反序列化,将json格式的字符串转换成python的数据类型:
import json
v = '["thanlon",23]'
# 反序列化,将json格式的字符串转换成python的数据类型
v2 = json.loads(v)
print(v2)
'''
['thanlon', 23]
'''
注意:不能序列化元组,会把元组变为列表
import json
v = ('thanlon', 23)
v2 = json.dumps(v)
print(type(v2), v2)
'''
["thanlon", 23]
'''
注意:不能序列化集合,会报错
import json
v = {'thanlon', 23}
# 反序列化,将json格式的字符串转换成python的数据类型
v2 = json.dumps(v)
'''
TypeError: Object of type set is not JSON serializable
'''
支持序列化位json字符串的数据类型:
来自encoder.py文件:
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
json字符串中需要构造成列表或字典(包裹其它内容)才可以被反序列化,传一个值也要构造成列表或字典:
import json
'''
list或dict包裹的内容才可以反序列化,只有字符串是不可以反序列化的
'''
v = 'thanlon'
v2 = json.loads(v)
print(v2)
'''
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
'''
③ dump与load(几乎不常用)
- dump:序列化后写入文件
# coding:utf-8
import json
v = [1, 2, 3]
f = open('test.txt', mode='w', encoding='utf-8')
val = json.dump(v, f)
print(val)
- load:读取文件数据并反序列化
# coding:utf-8
import json
f = open('test.txt', mode='r', encoding='utf-8')
val = json.load(f)
print(val)
'''[1, 2, 3]'''
④ json模块补充
序列化字典的时候,如果字典中有中文,在序列化为json格式字符串时需要保留中文,需要这样做:
# coding:utf-8
import json
v = {'k1': '奈何', '哈哈': 'v2'}
val = json.dumps(v) # 默认中文是unicode编码的
print(val)
'''
{"k1": "\u5948\u4f55", "\u54c8\u54c8": "v2"}
'''
val2 = json.dumps(v, ensure_ascii=False)
print(val2)
'''
{"k1": "奈何", "哈哈": "v2"}
'''
总结:字典或列表中如果有中文,序列化时想要保留中文显示,可以使ensure_ascii=False
2.4 pickle
① json与pickle
- json优缺点
优点:所有语言通用
缺点:只能序列化基本数据类型 list/dict/int - pickle优缺点
优点:python中所有东西都能被序列化(socket对象除外)
缺点:序列化的内容只有python语言能识别
② dumps/loads
dumps函数:用于将数据进行序列化,完成序列化后,会把数据转换成字节,是不可识别的。
loads函数:用于反序列化
示例:集合的序列化与反序列化:
# coding:utf-8
'''
集合的序列化与反序列化
'''
import pickle
v = {1, 2, 3, 4}
val = pickle.dumps(v)
print(val)
'''
b'\x80\x03cbuiltins\nset\nq\x00]q\x01(K\x01K\x02K\x03K\x04e\x85q\x02Rq\x03.'
'''
data = pickle.loads(val)
print(data)
'''
{1, 2, 3, 4}
'''
示例:函数的序列化与反序列化:
# coding:utf-8
'''
函数的序列化与反序列化
'''
import pickle
def foo():
print('foo')
v1 = pickle.dumps(foo)
print(v1)
data = pickle.loads(v1)
data()
'''
b'\x80\x03c__main__\nfoo\nq\x00.'
foo
'''
③ dump/load
dumps函数:对数据进行序列化,同时可以保存序列化的内容(序列化后写入文件)
loads函数:读取文件数据并反序列化
# coding:utf-8
'''
dump/load:
'''
import pickle
v = {1, 2, 3, 4}
f1 = open('test.txt', mode='wb')
val = pickle.dump(v, f1) # 写入文件的时候写入的是字节类型的数据
f1.close()
f2 = open('test.txt', mode='rb')
data = pickle.load(f2)
f2.close()
print(data)
'''
{1, 2, 3, 4}
'''
2.5 shutil
① 删除目录(常用)
os模块的删除可能会出问题,可能是权限的问题。文件夹中不能有文件,有文件就删除不了。 而shutil模块,强制删除(文件和目录一块被删除)。
# coding:utf-8
import shutil
# 删除目录
shutil.rmtree('test') # 不能删除文件
② 重命名目录和文件(常用)
# coding:utf-8
import shutil
# 重命名目录和文件
shutil.move('test', 'tmp')
shutil.move('test.txt', 'tmp.txt')
③ 压缩(常用)
# coding:utf-8
import shutil
# 压缩
shutil.make_archive('test', 'zip', 'test') # "zip", "tar", "gztar","bztar", or "xztar"
# shutil.make_archive('test', 'zip', 'E:\pycharmProjects\\untitled\\test')
④ 解压(常用)
# coding:utf-8
import shutil
# 解压到当前目录
shutil.unpack_archive('test.zip', format='zip') # 解压到当前目录
# 解压到指定目录,指定目录如果没有,可以创建
shutil.unpack_archive('test.zip', extract_dir='D:\\newdir', format='zip')
⑤ 将一个文件内容拷贝到另一个文件中
# coding:utf-8
import shutil
# 将一个文件内容拷贝到另一个文件中
shutil.copyfileobj(open('test.txt', 'r'), open('log.txt', 'w'))
⑥ 拷贝文件
# coding:utf-8
import shutil
# 拷贝文件
shutil.copyfile('test.txt','log.txt')
2.6 time
① time模块的基本使用
# coding:utf-8
import os, shutil
from datetime import datetime
ctime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(ctime) # 2019-08-01 16:59:42
② time模块相关
UTC/GMP:世界协调时间(UTF比GMP精度高)
本地时间:本地时区的时间
- time.time():时间戳(1070-1-1 00:00)
- time.sleep(10):等待的时间(秒)
- time.timezone:当前时区和格林尼治时间相差的秒数
③ time模块综合案例
# coding:utf-8
'''
1. 压缩test文件夹
2. 将压缩的文件放到tmp目录下(默认tmp目录不存在)
3. 将文件解压到D:\tmp文件夹下
'''
import os, shutil
from datetime import datetime
if not os.path.exists('tmp'):
os.mkdir('tmp')
ctime = datetime.now().strftime('%Y-%m-%d-%H-%M-%S') # ctime是字符串
path = os.path.join('tmp', ctime) # 字符串,tmp\2019-08-01-16-48-46
shutil.make_archive(os.path.join('tmp', ctime), 'zip', r'E:\pycharmProjects\untitled\test') # 将test压缩到tmp目录下
file_path = os.path.join('tmp', ctime) + '.zip'
shutil.unpack_archive(file_path, r'D:\tmp', 'zip') # 文件夹tmp没有自动创建
2.7 datetime
① 获取本地时间(重要)
from datetime import datetime
print(datetime.now()) # datatime类型
'''
2019-08-03 13:12:10.326124
'''
② 获取UTC时间(重要)
from datetime import datetime
print(datetime.utcnow())
'''
2019-08-03 05:15:04.251507
'''
③ 获得时区
from datetime import timezone, timedelta
tz = timezone(timedelta(hours=1)) # 获取时区,hours表示一小时间隔,表示东一区。西一区可以使用-1
print(tz)
'''
UTC+01:00
'''
④ 获取指定时区时间
from datetime import timezone, timedelta, datetime
tz = timezone(timedelta(hours=1)) # 获取时区
t = datetime.now(tz)
print(t)
'''
2019-08-03 06:27:31.913264+01:00
'''
⑤ datetime类型转换成字符串
from datetime import datetime
v1 = datetime.now()
print(v1, type(v1)) # 2019-08-03 13:39:09.383417 ⑥ 字符串转换成datetime
from datetime import datetime
v = datetime.strptime('2019-8-1', '%Y-%m-%d') # '2019-8-1'与'2019-08-01'
print(v, type(v))
'''
2019-08-01 00:00:00
'''
⑦ datetime类型时间的加减
from datetime import datetime, timedelta
# v = datetime.strptime('2019-8-1', '%Y-%m-%d') # '2019-8-1'与'2019-08-01'同没有写时间,使用00:00:00
time_str = datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 获取当前时间
v = datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S') #
val = v + timedelta(hours=24) # 增加20个小时,也可以减;不加参数,默认是增加的是天数
time_str2 = val.strftime('%Y-%m-%d %H:%M:%S')
print(v)
print(val)
print(time_str2, type(time_str2)) # 使用datetime类型去做加减,最后要把datetime类型转换成字符串
'''
2019-08-03 14:11:19
2019-08-04 10:11:19
'''
⑧ 时间戳和datetime相互转换
- 时间戳转换为datatime类型的时间
from datetime import datetime
import time
ctime = time.time()
print(ctime, type(ctime))
v = datetime.fromtimestamp(ctime)
print(v, type(v))
'''
1564813290.9766583
2019-08-03 14:21:30.976658
'''
- datetime类型转换为时间戳类型
from datetime import datetime
import time
v = datetime.now()
val = v.timestamp()
print(val, type(val))
'''
1564813408.263414
'''
⑨ time与datetime模块知识总结
总结:时间分为time和datetime,time中有一个时间戳类型时间,datetime中有datetime类型和字符串类型的时间。time可以与datetime相互转换,字符串一般用于页面显示以及文件的存储,如果想用随机值使用时间戳。datetime类型的时间可以做加减乘除运算。时间戳转换为datetime类型使用fromtimestamp方法,datetime类型可以转换为timestamp方法。datetime转换成字符串使用strftime方法,字符串转换为datetime类型使用strptime方法。datetime中时间的加减乘除使用timedelta。一般用时间戳和时间字符串多一些。
2.8 logging
# coding:utf-8
import logging
import traceback
# basicConfig函数的功能是:为日志系统做基础的配置
# print(logging.__dir__()) # 打印模块中的方法
'''
asctime:时间
name:用户
levelname:级别
module:运行的模块
message:相关信息
'''
logger = logging.basicConfig(
filename='log.txt',
format='%(asctime)s - %(name)s - %(levelname)s - %(module)s:%(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
level=30) # level>=30才会被写入日志文件,默认级别是30
# 级别大于basicConfig函数中设置的级别才可以被写入日志文件,内部都自带级别
# CRITICAL = 50
# FATAL = CRITICAL
# ERROR = 40
# WARNING = 30
# WARN = WARNING
# INFO = 20
# DEBUG = 10
# NOTSET = 0
# logging.debug('debug')
# logging.info('info')
# logging.warning('warning')
# logging.error('error')
# logging.critical('critical')
# logging.fatal('error') # fatal函数等价于critical函数
# logging.log(10, 'debug') # debug
# logging.log(20, 'info') # info
# logging.log(30, 'warning') # warning
# logging.log(40, 'error') # error
# logging.log(50, 'critical') # critical/fatal
def func():
a = 10
try:
b = a / 0
except Exception as e:
# print(e) # print函数内部调用str方法将对象转换成字符串打印出来
'''
只是将e的信息写入日志,这是不够的
'''
# logging.error(str(e))
'''
需要更加具体到错误的代码行数
'''
msg = traceback.format_exc()
logging.error(msg)
'''
log.txt文件:
2019-07-03 23:32:01 - root - ERROR - logTest:Traceback (most recent call last):
File "E:/pycharmProjects/day15/logTest.py", line 48, in func
b = a / 0
ZeroDivisionError: division by zero
'''
func()
2.9 md5加密
① 简单的加密
import hashlib
# 实例化对象
obj = hashlib.md5()
# 写入要加密的字节,python3中加密的必须是字节
obj.update('123456'.encode('utf-8'))
# 获取密文
ciphers = obj.hexdigest()
print(ciphers)
'''e10adc3949ba59abbe56e057f20f883e'''
如果撞库(将能想到的常用的密码加密,根据密文找明文),密码可能不安全。
② 加盐实现加密
使用加盐可以解决撞库问题,增强密码的安全性。
# 使用加盐解决撞库
import hashlib
# 实例化对象
obj = hashlib.md5(b'thanlon') # 加盐
# 写入要加密的字节,python3中加密的必须是字节
obj.update('123456'.encode('utf-8'))
# 获取密文
ciphers = obj.hexdigest()
print(ciphers)
'''1a8c227a607ed3c09a39f4b6a6df8869'''
③ MD5加密的应用(自定义MD5函数)
定义自己的MD5加密函数,方便应用到自己的项目中:
import hashlib
SALT = b'thanlon'
# 自定义MD5函数
def md5(pwd):
obj = hashlib.md5(SALT)
# pwd是字符串,需要将其转换成字节
obj.update(pwd.encode('utf-8'))
# 返回密文
return obj.hexdigest()
print(md5('123456'))
2.10 getpass
getpass模块可以让用户在终端输入密码不显示,注意只有在终端运行密码才会不显示。
import getpass
pwd = getpass.getpass('请输入密码:')
if pwd == '123456':
print('密码正确!')
2.11 csv
① csv概述
csv:逗号分隔值(comma-separated values),有时也称为字符分割值,以纯文本形式存储表格数据(数字和文本)。
创建csv文件:在Microsoft Excel中船舰表格,另存为csv格式的文件,

输入如下数据:
![]()
② csv文件的读取
import csv
with open('stuInfo.csv', 'r') as f:
data = csv.reader(f)
# print(data) # data is a object<_csv.reader object at 0x00000197FC4A4160>
# for data_item in data:
# print(data_item)
# ['1', 'thanlon', '10000']
# ['2', 'Maria', '20000']
for data_item in data:
print(data_item[0], data_item[1], data_item[2])
'''
1 thanlon 10000
2 Maria 20000
'''
③ csv文件的写入
import csv
stu = ['3', 'Maria', 10000]
with open('stuInfo.csv', 'a', newline='') as f: # 如果没有加newline=''写入一行后空行
csv_writer = csv.writer(f, dialect='excel')
csv_writer.writerow(stu)
with open('stuInfo.csv', 'r') as f:
data = csv.reader(f)
for data_item in data:
print(data_item[0], data_item[1], data_item[2])
'''
1 thanlon 10000
2 Maria 20000
3 Maria 10000
'''
2.12 timeit
timeit模块可以用来计算代码执行的时间。
① timeit函数
timeit模块的timeit函数其实返回的是timerit模块中Timer类的timeit方法的执行结果,timeit函数的源码:
def timeit(stmt="pass", setup="pass", timer=default_timer,
number=default_number, globals=None):
"""Convenience function to create Timer object and call timeit method."""
return Timer(stmt, setup, timer, globals).timeit(number)
参数:
- stmt:用来放需要进行计算时间的代码,可以接收字符串的表达式、单个变量、函数。
- setup:可以用来传stmt的环境,例如import和一些参数之类的。
- number:执行是的次数,默认是1000000
- 其它参数一般用不到,具体可查看文档
返回值:
- timeit函数返回的是float类型的数据。
② repeat函数
timeit模块的repeat函数其实返回的是timeit模块中Timer类repeat方法的执行结果,repeat函数的源码:
def repeat(stmt="pass", setup="pass", timer=default_timer,
repeat=default_repeat, number=default_number, globals=None):
"""Convenience function to create Timer object and call repeat method."""
return Timer(stmt, setup, timer, globals).repeat(repeat, number)
参数:repeat函数比timeit函数多一个repeat参数
- stmt:用来放需要进行计算时间的代码,可以接收字符串的表达式、单个变量、函数。
- setup:可以用来传stmt的环境,例如import和一些参数之类的。
- number:执行是的次数,默认是1000000
- repeat:重复整个测试的个数,默认是3
- 其它参数一般用不到,具体可查看文档
返回值:
- repeat函数返回的是列表类型的数据。
③ 测试列表推导式与for循环的执行时间
使用timeit函数:
import timeit
stmt_list = '''
lst=[]
for i in range(10000):
lst.append(i)
'''
if __name__ == '__main__':
print(timeit.timeit('[i for i in range(10000)]', number=10000))
print(timeit.timeit(stmt_list, number=10000))
'''
3.346147895
5.789892938
'''
使用repeat函数:
import timeit
stmt_list = '''
lst=[]
for i in range(10000):
lst.append(i)
'''
if __name__ == '__main__':
print(timeit.repeat('[i for i in range(10000)]', repeat=2, number=10000))
print(timeit.repeat(stmt_list, repeat=2, number=10000))
'''
[3.374952514, 3.4277178010000005]
[5.748379824000001, 5.8717959529999995]
'''
2.13 random
随机数是随机试验的结果,是计算机通过随即种子根据一定算法计算出来的,随机种子通常可以由系统时钟产生。下面是random库中基本方法:
① random()
产生一个0到1之间的随机浮点数:0<=n<1.0

② randint(a,b)
产生指定范围内的整数,a<=n<=b

② uniform(a,b)
产生一个指定范围内的随机浮点数,a可以大于b,a>b时生成b<=n<=a;b>a时生成a<=n<=b

④ randrange(a,b,step)
从按照指定,按指定基数(step)递增的集合中获取一个随机数

⑤ choice(sequence)
从序列中获取一个随机元素,sequence表示一个有序类型,泛指一系列类型,list、tuple字符串都属于sequence

⑥ shuffle(list)
将列表中的内容打乱

注意:不可以将suffle(list)赋值给另一list,输出这个lis,是没有意义的。原因是:suffle(list)只是修改list中内容的顺序

⑦ sample(sequence,k)
从指定序列中获取指定长度的片段,k是指定长度
⑧ 更多
可以通过dir(random)查看random库中所有方法,另外可以使用help函数可以获取操作方法的说明书,如:

2.14 csv
csv文件的读取:
import csv
with open('stuInfo.csv', 'r') as f:
data = csv.reader(f)
# print(data) # data is a object<_csv.reader object at 0x00000197FC4A4160>
for data_item in data:
print(data_item)
'''
['1', 'thanlon', '10000']
['2', 'Maria', '20000']
'''
for data_item in data:
print(data_item[0], data_item[1], data_item[2])
'''
1 thanlon 10000
2 Maria 20000
'''
csv文件的写入:
import csv
stu = ['3', 'Maria', 10000]
with open('stuInfo.csv', 'a', newline='') as f: # 如果没有加newline=''写入一行后空行
csv_writer = csv.writer(f, dialect='excel')
csv_writer.writerow(stu)
3. 第三方模块
3.1 第三方模块的安装
① 包管理工具pip安装
pip install 模块名
② 源码安装
- 下载源码包(压缩文件)
- 加压文件
- 打开cmd,进入文件目录,执行python setup.py build
- 再执行python setup.py install
3.2 jieba
① jieba模块简介
jieba是Python中一个重要的第三方分词函数库,能够将中文文本分割成中文词语的序列。jieba原理是将中文文本与分词词库对比,通过图结构和动态规划算法找出最大概率的词组。
② jieba模块的三种分词模式
- 精确模式:将句子精确地分开,适合文本分析。
import jieba
str = '宁浩出任第22届上海国际电影节亚洲新人奖评委会主席'
ls =jieba.lcut(str)
print(ls)
[‘宁浩’, ‘出任’, ‘第’, ‘22’, ‘届’, ‘上海’, ‘国际’, ‘电影节’, ‘亚洲’, ‘新人奖’, ‘评委会’, ‘主席’]
- 搜索引擎模式:在精确查找的基础上对长词再次切分,提高召回率,适合搜索引擎分词。
import jieba
str = '宁浩出任第22届上海国际电影节亚洲新人奖评委会主席'
ls =jieba.lcut_for_search(str)
print(ls)
[‘宁浩’, ‘出任’, ‘第’, ‘22’, ‘届’, ‘上海’, ‘国际’, ‘电影’, ‘电影节’, ‘亚洲’, ‘新人’, ‘新人奖’, ‘评委’, ‘委会’, ‘评委会’, ‘主席’]
- 全模式:把句子可以成词的语句都扫描出来,速度快但不能解决歧义。
import jieba
str = '宁浩出任第22届上海国际电影节亚洲新人奖评委会主席'
ls =jieba.lcut(str,cut_all=True)
print(ls)
[‘宁’, ‘浩’, ‘出任’, ‘第’, ‘22’, ‘届’, ‘上海’, ‘海国’, ‘国际’, ‘电影’, ‘电影节’, ‘亚洲’, ‘新人’, ‘新人奖’, ‘奖评’, ‘评委’, ‘评委会’, ‘委会’, ‘会主’, ‘主席’]
3.3 pyInstaller
① 模块概述
可以在Windows、Linux、Mac 0S等操作系统下将.py的Python源文件打包直接运行的可执行文件。
② 模块的优点
通过对Python源文件打包,使Python程序在可以没有安装Python环境中运行,可作为独立文件方便传递和管理。此外,公司通常是不开放自己源代码的,将源文件打包成看不到源代码的可执行文件,安全性得到增强。
③ 模块相关参数
-F或–onefile:在dist文件夹中只生成独立的打包文件
-h或–help:帮助信息
–clean:清理打包过程中的临时文件
-i <图标文件路径名.io>:指定打包程序使用的图标
-D或–onedir:默认值,生成dist目录
④ 模块的使用
$ pyinstaller -F test.py
执行完成后,源文件目录生成dist和build目录,build目录是PyInstaller存储临时文件的目录,可以完全删除。最终打包程序在dist内部与源文件同名的目录中。
3.4 virtualenv
virtualenv可用来帮助我们创建虚拟环境。
① 安装virtualenv(安装遇到问题可以在评论区留言)
thanlon@thanlon-vivobook:~$ pip install virtualenv
② 创建一个名字为env名字的虚拟环境
thanlon@vivobook:~$ virtualenv env --no-site-packages(不包括安装的其它第三方模块)
③ 激活虚拟环境
root@vivobook:/home/thanlon# source env/bin/activate
④ 退出虚拟环境
(env) root@vivobook:/home/thanlon/env# deactivate
⑤ 删除虚拟环境(删除这个env这个文件夹就可以)
root@vivobook:/home/thanlon# rm -r env
⑥ pycharm中使用virtualenv

3.5 multiprocessing
multiprocessing是一个跨平台的多进程模块,提供一个Process类来代表一个进程对象,下面是一个多进程示例:
# -*- coding: utf-8 -*-
from multiprocessing import Process
import time
def f(n):
time.sleep(1)
print(n * n)
def main():
for i in range(10):
p = Process(target=f, args=[i, ])
p.start()
# p.join()使用p.join()可阻塞进程,前面一个进程执行完,后面的进程才可以执行
if __name__ == '__main__':
main()
程序使用单进程写则需要执行10s以上的时间,而使用多进程启用10个进程并行执行,只需要用1秒多的时间。
Queue是多进程安全队列,可以使用Queue实现多进程之间的数据传递,下面是一个Queue相关的例子:
# coding:utf-8
from multiprocessing import Queue, Process
import time
def write(q):
lst = ['A', 'B', 'C', 'D']
for i in lst:
q.put(i)
print('Put %s to queue' % i)
time.sleep(0.5)
def read(q):
while True:
v = q.get(True)
print('get %s from queue' % v)
def main():
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
pw.start()
pr.start()
pr.join()
pr.terminate()
if __name__ == '__main__':
main()
Put A to queue
get A from queue
Put B to queue
get B from queue
Put C to queue
get C from queue
Put D to queue
get D from queue
3.6 wordcloud
wordcloud库是专门用来生成词云的Python第三方库,词云:以词语为单位,根据文本出现的概率设计不同的size,形成关键词词文或关键词渲染。wordcloud的核心类是wordcloud类,所有的功能都封装在wordcloud类中。wordcloud类在创建时有一系列可选参数,用于配置词云图片。wordcloud类中常用的方法有:generate(text)方法可以由字符串的内容生成词云,to_file(图片文件)方法可以将词云图保存为图片。下面看一个wordcloud的例子:
from wordcloud import WordCloud
text = 'I like python, I am learning python.' # 标点符号不参与
wd = WordCloud().generate(text)
wd.to_file('test.png') # 其它图片格式也是可以的
下面再看一个worlcloud与jieba库结合的例子:
import jieba
from wordcloud import WordCloud
text = '程序设计语言是计算机'
words = jieba.lcut(text)
print(words) # ['程序设计', '语言', '是', '计算机']
new_text = ' '.join(words)
print(new_text)
wc = WordCloud(font_path = None).generate(new_text)
wc.to_file('test.png')
wordcloud库相关的属性:
font_path:默认为None,指定字体文件的完整路径
width:生成图片的宽度,默认是400px
height:生成图片的高度,默认是200px
mask:词文形状,默认是None,默认是方型图
min_font_size:词云最小的字体字号,默认是4号
max_font_size:词云最小的字体字号,默认是None,根据高度自动调节
font_step:字体间隔,模式是1
max_words:词云中最大词数,默认是200
stop_words:被排除词列表,排除词不在词云中显示
background_color:图片背景颜色,默认是黑色