深入理解 Java 乱码问题
前言
这段时间在看 TCP/IP 网络通信这块,好奇我的电脑和局域网中电脑怎样通信,又怎样外网通信,Mysql 相关的博客延期执行了。
好久没写博客了,就把以前的博客整理一下,发布到自己的网站上去。
乱码问题说难不难,一句话解决,编码和解码采用相同的 charset (字符集)。
如果深究,需要了解的东西挺多的:
- Java 中字符串和 Unicode 的关系
- Unicode 和 UTF-8、GBK 的关系
- 原码,反码,补码(因为 java 采用补码存储)
Java 中字符串
在 java 中定义字符串
@Test
public void run1() {
String a = "a";
System.out.println(a);
String b = "\u261d";
System.out.println(b);// ☝
String ding = "\u4E00";
System.out.println(ding);// 一
}java 中字符串与 Unicode 有什么关系呢?
public class Str {
public static void main(String[] args) {
char char1 = '一';
String str1 = "丁万";
System.out.println(char1);
System.out.println(str1);
}
}编译之后的 class 文件,采用了 Uincode 字符集。
比如你源码 java 文件为 utf-8,编译之后采用 Uincode 字符集。
源码文件为 GBK,编译之后采用 Uincode 字符集。
从下图展示结果可以推出上述结论。
在线进制转换
一 对应 Uincode 码点为 4E00,十进制为:19968
丁 对应 Uincode 码点为 4E01
万 对应 Uincode 码点为 4E07
idea 自带的插件 ByteCodeViewer 和安装的插件 jclasslib。在导航栏 View 下可以看到。
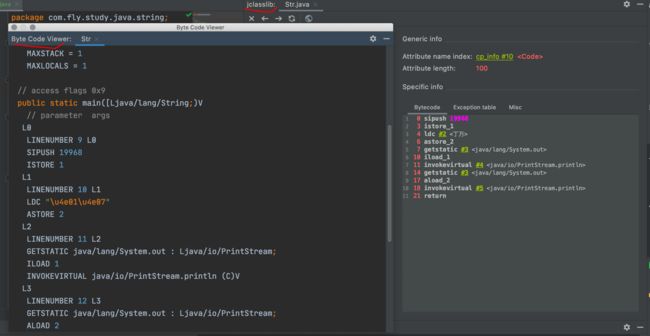
java 内存中的字符串采用的是 unicode 字符集,也就是内编码。不管怎么编码解码,最后的字符串都会用 unicode 字符集
public class Str {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "字符串编译之后为 unicode 字符集";
final String charsetName = "UTF-8";
// 使用 UTF-8 编码为字节
final byte[] bytes = str.getBytes(charsetName);
// 解码为字符串,编码和解码采用同样的编码规则 UTF-8
final String x = new String(bytes, charsetName);
// 打印 23383,字的 16 进制码点为 5B57 转为十进制为 23383
System.out.println(x.codePointAt(0));
System.out.println(x);
final String gbk = "GBK";
// 使用 GBK 编码为字节
final byte[] gbks = str.getBytes(gbk);
// 解码为字符串,编码和解码采用同样的编码规则 GBK
final String x1 = new String(gbks, gbk);
// 打印 23383,字的 16 进制码点为 5B57 转为十进制为 23383
System.out.println(x1.codePointAt(0));
System.out.println(x1);
}
}java 乱码思考题
来个例子体验下怎样解决乱码问题,这个算是模拟乱码解决的场景了
@Test
public void run100() throws UnsupportedEncodingException {
String str = "张攀钦";
final byte[] gbks = str.getBytes("GBK");
final String s = new String(gbks, "UTF-8");
// 以上代码不允许修改
// 你有办法将 s 变为不乱码吗
}以上内容你了解了,基本不用往下看了,下面是我验证我对 Uincode 字符集和 UTF-8 、GBK 理解 。
Unicode 和 UTF-8 的关系
Uincode 编码表
Uincode 是一个字符集。它规定了我们使用到的字或符号的码点(code point)。码点使用 16 进制保存。

Uincode 字符集规定 一 的码点为 4E00。
Uincode 字符集规定 丁 的码点为 4E01。
计算机呢只能识别二进制的 0 和 1。而 UTF-8 指的是编码规则,定义了 码点 怎么保存成二进制。
| 十进制 | Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|---|
| 0-127 | 0000 0000-0000 007F | 0xxxxxxx |
| 128-2047 | 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 2048-65535 | 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 65536-1114111 | 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
上述表格简单描述了Unicode 按 UTF-8 编码的格式。
- 首先将 16 进制的码点,通过进制转换 为十进制
- 然后使用十进制的数字查找上述表格处于哪个范围中,得出编码规则。
- 然后将码点转换为 2 进制,从低位到高位替换 x 即可得到字二进制的原码
- 将二进制的原码转换为补码存储。
Java基础-原码反码补码
代码验证猜想
以 赵 为例子讲解,赵 的码点为:8D75
赵 的 16 进制的码点转换为 10 进制:36213
36213 处于 2048-65535 ,得出对应的 UTF-8 编码格式为:1110xxxx 10xxxxxx 10xxxxxx
赵的 16 进制码点 8D75 转换为二进制 1000 110101 110101
将 1000 110101 110101 二进制填充在 1110xxxx 10xxxxxx 10xxxxxx 中的 x 中,不足的补 0.
补充完为:11101000 10110101 10110101。
对三个字节分别求补码为:
原码:11101000 10110101 10110101
补码:10011000 11001011 11001011
每个字节的第一位表示是正数还是负数。 1 表示负数,0 表示正数。
补码对应 java 中的字节数组为:{-24,-75,-75}
@Test
public void run454() throws UnsupportedEncodingException {
String str ="赵";
final byte[] bytes = str.getBytes("UTF-8");
StringBuilder stringBuilder =new StringBuilder();
for (byte aByte : bytes) {
stringBuilder.append(aByte).append(",");
}
System.out.println(stringBuilder.toString());
}为了再次确认我的逻辑是否正确,我再使用 且 字验证
且 的码点: 4E14
16 进制的码点转换为 10 进制:19988
19988 处于 2048-65535 ,得出对应的 UTF-8 编码格式为:1110xxxx 10xxxxxx 10xxxxxx
16 进制的码点转换成二进制:100111000010100。
将 100 111000 010100 填入对应的编码格式 1110xxxx 10xxxxxx 10xxxxxx 的 x,没有填充的 x 用 0 替换。
原码:11100100 10111000 10010100
补码:10011100 11001000 11101100
补码对应的字节数组为:{-28,-72,-108}
@Test
public void run43() throws UnsupportedEncodingException {
// {-28,-72,-108}
String str ="且";
final byte[] bytes = str.getBytes("UTF-8");
StringBuilder stringBuilder =new StringBuilder();
for (byte aByte : bytes) {
stringBuilder.append(aByte).append(",");
}
System.out.println(stringBuilder.toString());
}Uinocde 与 GBK 转码
GBK 编码表
赵的 GBK 码点为:D5D4
十六进制码点转换为二进制:11010101 11010100 源码:11010101 11010100 补码:10101011 10101100
补码对应的字节数组为:{-43,-44}
@Test
public void run454() throws UnsupportedEncodingException {
String str ="赵";
final byte[] bytes = str.getBytes("GBK");
StringBuilder stringBuilder =new StringBuilder();
for (byte aByte : bytes) {
stringBuilder.append(aByte).append(",");
}
// -43,-44
System.out.println(stringBuilder.toString());
}上述思考题见解
@Test
public void run100() throws UnsupportedEncodingException {
String str = "张攀钦";
final byte[] gbks = str.getBytes("GBK");
final String s = new String(gbks, "UTF-8");
// 以上代码不允许修改
// 你有办法将 s 变为不乱码吗
}可能你会这样想
@Test
public void run100() throws UnsupportedEncodingException {
String str = "张攀钦";
final byte[] gbks = str.getBytes("GBK");
final String s = new String(gbks, "UTF-8");
// 以上代码不允许修改
// 你有办法将 s 变为不乱码吗
final byte[] error_s = s.getBytes("UTF-8");
// 打印依然是乱码
System.out.println(new String(error_s,"GBK"));
}编码:字符串到字节。
解码:字节到字符串。
当我们读取文件的时候实际读取的是字节。然后根据文件的编码格式,将字节解码成字符串。乱码问题容易出现的地方就是这里。
不要妄想在 java 中将一个乱码的字符串变量变成一个非乱码的。这个思路是错误的。应该从乱码之前的字节着手处理。
这里的 s 实际上就是乱码的字符串了,你怎么改变它都回不到 str。
因为 s 和 str 的字节压根不是一个东西了。
@Test
public void run100() throws UnsupportedEncodingException {
String str = "张攀钦";
final byte[] gbks = str.getBytes("GBK");
final String s = new String(gbks, "UTF-8");
System.out.println(s);
}解决乱码问题的思路,是先确定在哪里开始的乱码,这里开始向上查代码,看哪里解码采用了错误的编码规则。
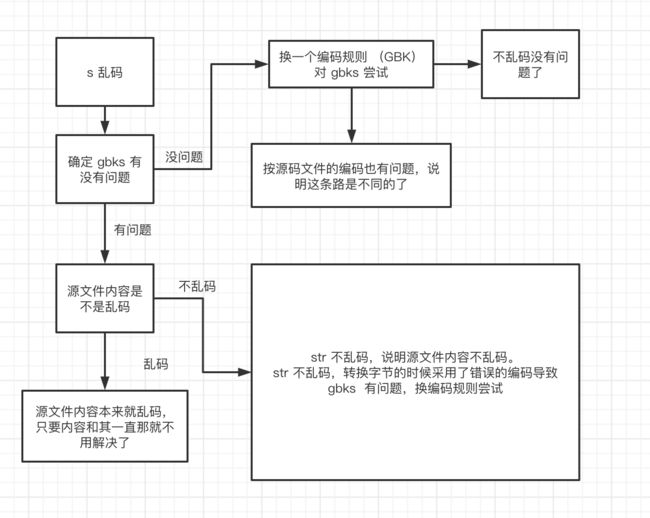
上述场景实际是对不乱码的 gbks 采用了错误的解码规则,我们只要换一下解码规则就行了。
@Test
public void run100() throws UnsupportedEncodingException {
String str = "张攀钦";
final byte[] gbks = str.getBytes("GBK");
final String s = new String(gbks, "GBK");
System.out.println(s);
}本文由 张攀钦的博客 http://www.mflyyou.cn/ 创作。 可自由转载、引用,但需署名作者且注明文章出处。
如转载至微信公众号,请在文末添加作者公众号二维码。微信公众号名称:Mflyyou