马士兵老师JVM调优
JVM调优
目标:调整Java虚拟机的参数使得性能达到最优。
原则:无监控不调优。
Java内存结构
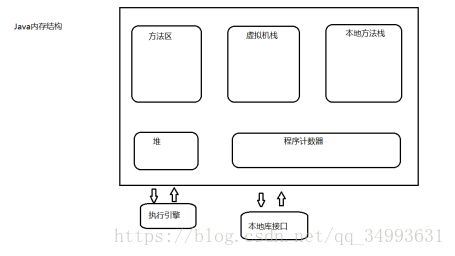
虚拟机栈:存放局部变量,每起一个方法都会在栈内存中起一个栈针。所有的局部变量都方法在这个栈针中。所有new出来的东西都放在堆里面。这里面的栈针也可以认为是某一个线程的,每起一个线程就会在栈内存里分配一个栈空间,在这个线程上没起一个方法就会起一个栈针。栈针中存放着局部变量。不同的栈针中的局部变量是不会冲突的。总结起来就是一个线程一个栈,一个栈针。
本地方法栈:Java访问C语言等其它语言所用到的栈,我们访问不了。调优不了。
堆:是最大的内存。
方法区:也称为永久区。这块区域存放着class加载相关的信息,也就是class文件将会加载到这块区域。静态变量,字符串常量常量池。执行引擎找下一步该执行谁也是到永久区找。
我们能够优化的地方只有堆,堆也是JVM内存最大的存储区域。
堆内存和方法区都是线程所共享的。
栈内存和本地方法栈,PC计数器,每个线程所独有的。
堆内存
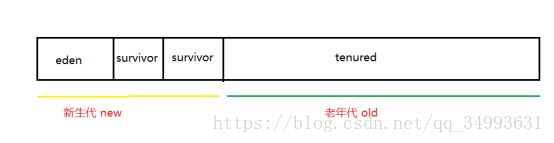
Eden伊甸园:
Survivor:幸存者
新生代比例经验值:8 :1 :1
Tenured:老年代
总体比例:1 : 2 或者是 3 :7
流程:当我们第一次new出一个对象来的时候特别大的对象会放在老年代,其它的普通对象直接放在新生代。每次的survivor之间进行copy的时候另一个survivor会被回收,也就是时时刻刻都有一个survivor为空。由于这个算法是基于内存的复制所以效率很高。

如果经历了很多次的GC都没有回收的话就会被放入老年代。
GC
什么是垃圾?
引用计数算法
没有引用指向的对象就是垃圾?不完全是,比如说环形垃圾互相引用的对象。
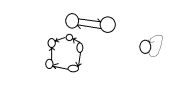
所以使用循环引用的方法去判断垃圾是不行的。
正向可达算法
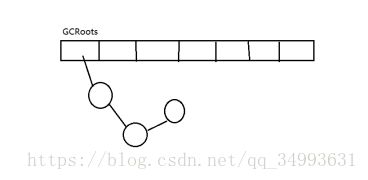
首先要得到在堆内存中一定不是垃圾的根对象,我们称之为GCRoots。顺着GCRoots的引用往下找顺藤摸瓜摸到的就是好瓜,摸不到的就是烂瓜(垃圾)。
垃圾收集算法
Mark-Sweep(标记清除算法)
算法本身只是标记而不是清除,被标记可用的内存区域会在新new对象的时候可以直接占用。缺点是内存的不连续。当来了一个大的对象的时候内存中会由于碎片化而装不下这时会进行fullGC(全回收),把离散的区域压缩到一片连续的区域这时才可以放下,这样的话效率就会略低。

Copying(拷贝)
Copy会把内存区域分为两个部分A、B而且肯定有一个区域为空(假设B区域为空)。在垃圾回收的时候首先会用正向可达算法将所有的存活对象找到。然后会把A中的所有存活对象拷贝到B区域并且压缩。最后回收A区中的垃圾。在洗一次GC之前,产生的新对象会被放到B区域来如此往复。它的效率非常之高。这个算法的缺点就是浪费内存,永远会浪费掉一半的内存。
为什么eden的区域比survivor大。就是因为在eden中的对象大多数会被回收所以存活下来的对象会比较少这时就比较适合使用拷贝算法(拷贝的量比较少)。

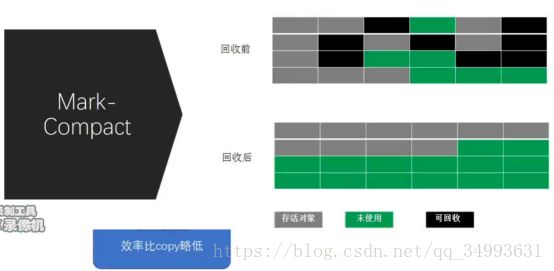
Mark-Compact(标记压缩)
首先将幸存的对象压缩到一端然后再进行GC这样的话也会得到连续的可用的空间。效率比copy略低。这个算法常常用于老年代,在新生代用的是copy的算法。
JVM使用分代算法
New
存活对象少,使用copying占用的内存空间也不大,效率也高。
Old
垃圾少,一般使用mark-compact标记压缩。
除此之外还有Mark-cleaning(标记清理)。
补充:
当堆内存的使用率超过70%的时候,GC才会启动回收。
发生在新生代的回收 --- minor gc 初代回收
发生在老生代的回收 --- full gc 完全回收
当new出来的对象比较小的时候回方到eden区域,如果new出来的对象比较大的时候那么就会放到tenured区去。
JVM参数
- 标准参数所有的JVM都应该支持。
-X非标准参数,每个JVM都应该实现。
-XX不稳定参数(扩展参数),下一个版本可能会取消。
JVM垃圾收集器
Serial Collector
XX + UseSerialGC 序列化垃圾收集器,一个单线程的收集器,实际中使用的并不多。
Parallel Collector
并发量大,但是在每次垃圾收集的时候回导致JVM停顿。
CMS
并发收集,分区处理。停顿时间短,在垃圾收集的时候,JVM还可以运行。
G1
不仅停顿时间短(这是一个平衡点)而且并发量大。
Java对象的分配
当new出一个对象来JVM会经历这样的几个分配过程。
栈上分配(这个很颠覆)
当new出一个小的对象来的时候那么会优先分配到栈(线程栈)上面去。JavaServer模式默认会开启栈优化。因为栈中的对象会在方法结束之后栈针就会销毁,因此它就根本无需垃圾回收(它本身就有垃圾回收的特质)。
无逃逸如果在方法的外面有一个引用指向了方法内部那么此时这个方法就逃逸了。
标量替换,将一成员变量拿出来当做普通的数据类型往栈上存。
无需调整
线程本地分配(TLAB Thread Local Allacation Buffer)
当栈上分配不了也就是栈空间满了会来到线程本地分配。每一个线程在执行的时候会给自己分配一块自己专用的内存,叫做线程本地内存。(一个?)线程本地内存默认占用eden内存的1%。如果每一个线程都要放入eden的同一块区域那么这个区域就要进行加锁,但是每个线程的数据都有自己的一块独立的区域那么就不需要加锁了,不加锁就提高了访问效率。
无需调整
老年代
当上述两种都分配不了那么就先看看自己是否是一个大对象,如果是就分配到老年代。
Eden
如果自己是一个不太大的对象就分配到eden区来。
垃圾回收效率的提高
使用TLAB会提升一截,使用逃逸分析和标量替换性能又能够提升一截。
在eclipse中的run configuration中配置:
-XX:DoEscapeAnalysis //不做逃逸分析 与栈上分配有关
-XX:-EliminateAllocations //不做标量提换 与栈上分配有关
-XX:UseTLAB// 不使用本地缓存
-XX:+PrintGC // 打印GC过程
在实际的环境中我们要权衡并发的数量和并发的深度的关系。


一个检测的实例
在实务上我们需要通过一些工具来判断在程序中造成内存溢出的原因,这里就介绍一个实例
代码如下:
-
package test; -
import java.util.ArrayList; -
import java.util.List; -
public class Test { -
public static void main(String[] args) { -
List -
for (int i = 0; i < 100000000; i++) { -
list.add(new byte[1024*1024]); -
} -
} -
}
参数如下(在Run Configuration的时候来在VMarguments中进行设置):
-
-XX:+HeapDumpOnOutOfMemoryError -
-XX:HeapDumpPath=C:\tmp\jvm.dump (生成堆内存相关的文件) -
-XX:+PrintGCDetails (打印GC的详细过程) -
-Xms10M (初始堆大小) -
-Xmx10M (最大堆大小)
最后会在c盘的tmp目录下面生成一个jvm.dump的文件。将jvm.dump导入到jdk文件夹下的bin目录中的jvisualvm.exe中。然后我们观测到了造成内存溢出的是由byte[]造成的,如下图所示。

Tomcat的优化配置
改动tomcat-->bin-->contalina.bat下面的的set JAVA_OPTS参数

使用Jmeter工具启动多个线程来对tomcat进行性能测试观察配置参数之前(也就是将set JAVA_OPTS中的配置注释掉)与解开注释前后每一秒并发数量的多少来判断性能的提升。
最后,在实务上我们不推荐手动使用gc()来垃圾回收,这样会破坏我们的设定回收策略。
最后,特地感谢马老师一个真正做教育的老师!
--------------------- 本文来自 主流7 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/qq_34993631/article/details/81673033?utm_source=copy