Flume的基本使用介绍
一、Flume概述
Flume是一个分布式的、高可靠的、可用的一个服务,用于收集、聚合、移动大量数据。它有简单、灵活的结构基于数据流,具有健壮性和容错性,它能够使用简单的、可扩展的数据模型用于在线实时分析应用。结构图如下:
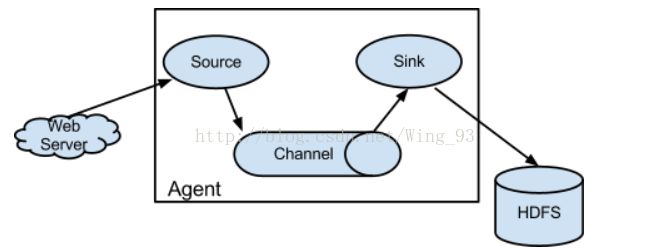
webserver(源端) ===> flume ===> hdfs(目的地),一个Flume对应一个agent,agent里包含Source、channel、sink,所以只需要配置agent,就可以完成各项配置,也增强了Flume的管理性。
设计目标为:可靠性、扩展性、管理性。
二、Flume的架构和核心组件
2.1 三个核心组件
1.source(输入)
source相当于数据的输入,source的种类很多中,像Avro source、exec source、JMS source等,你也可以自定义source,这根据你不同的需要去官网查看对应的配置。
2.channel(收集)
主要用于数据的收集,相当于一个缓存池一样,可以指定大小,先把数据积攒起来,再一起处理。种类有memory channel、File channel、 kafka channel、 file channel等,也可以自定义。
3.sink(输出)
主要用于将收集好的数据对目的地进行输出,主要有HDFS sink,HIVE sink,Logger sink,Avro sink, Hbase sink等,也可以自定义sink。
2.2 Flume的设置方式
Flume可以进行串联和并联,很高的扩展性,下面来介绍几种Flume的设置方式。
1.串联:
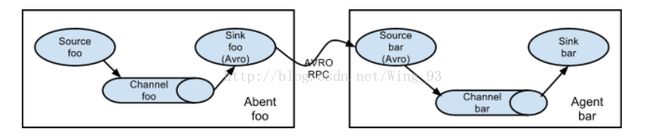
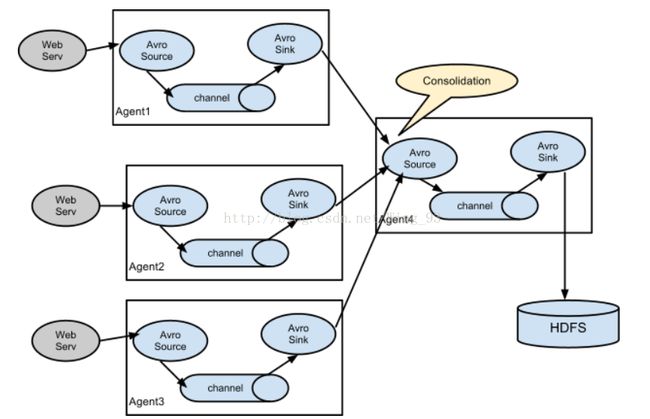
2.整合使用(Consolidation),多个agent合并输出到某个agent:
3.多路复用流(multiplexing the flow),一个agent多个sink输出:

三、Flume安装与部署
3.1 Flume安装前置条件
1. Java内存环境1.7 及 以上
2.要有足够内存
3. 足够的磁盘空间
4. 有目录的权限
3.2 安装JDK
下载,解压到~/app,再将java配置系统环境变量中: ~/.bash_profile,设置如下:
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
export PATH=$JAVA_HOME/bin:$PATH
配置好后,source下让其配置生效,最后检测: java -version。
3.3 安装FLUME
下载,解压到~/app,再将java配置系统环境变量中: ~/.bash_profile
export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
配置好后,source下让其配置生效,其中主要的是flume-env.sh的配置:
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
最后检测: flume-ng version。
3.4 使用
使用Flume的关键就是写配置文件
A) 配置Source
B) 配置Channel
C) 配置Sink
D) 把以上三个组件串起来
接下来我就用三个Demo来进行展示。
四、Flume实战Demo
4-1 从指定网络端口采集数据输出到控制台
在Flume的conf目录下生成一个配置文件,内容如下
a1: agent名称
r1: source的名称
k1: sink的名称
c1: channel的名称
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop000
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example.conf \
-Dflume.root.logger=INFO,console测试结果如下:

其中要注意的是:
Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
Event是FLume数据传输的基本单元
Event = 可选的header + byte array
4.2 监控一个文件实时采集新增的数据输出到控制台
Agent选型:exec source + memory channel + logger sink,选择exec source就是运行unix指定的命令行来处理不断的数据,以此来生产数据。本demo就是实时监控data.log日志内的内容。
配置文件如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/data.log
a1.sources.r1.shell = /bin/sh -c
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-logger.conf \
-Dflume.root.logger=INFO,console
4.3 将A服务器上的日志实时采集到B服务器上
技术选型:
exec source + memory channel + avro sink
avro source + memory channel + logger sink
流程图:
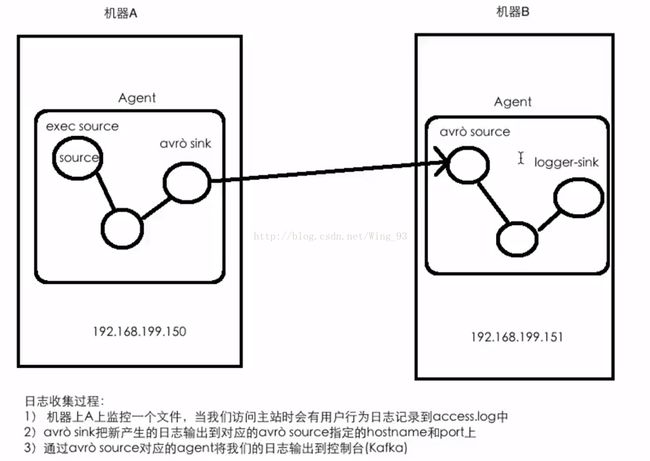
注意跨节点的数据一般都采用到的是avro 类型。
配置文件exec-memory-avro.conf:
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -F /home/hadoop/data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop000
exec-memory-avro.sinks.avro-sink.port = 44444
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop000
avro-memory-logger.sources.avro-source.port = 44444
avro-memory-logger.sinks.logger-sink.type = logger
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
先启动avro-memory-logger,命令如下:
flume-ng agent \
--name avro-memory-logger \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/avro-memory-logger.conf \
-Dflume.root.logger=INFO,console
flume-ng agent \
--name exec-memory-avro \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-avro.conf \
-Dflume.root.logger=INFO,console