【阅读笔记】Training Deep Neural Networks in Generations: A More Tolerant Teacher Educates Better Students
Training Deep Neural Networks in Generations:A More Tolerant Teacher Educates Better Students是CVPR2018的一篇文章,在知识蒸馏方向对于教师模型和学生模型的学习效果进行了进一步的探讨,在阅读本文之前,需要考虑两个问题,
(1)为什么教师和学生网络之间的学习会有效?
注:在知识蒸馏方向需要探索的一个关键问题,让教师模型生成的soft logits可以尽可能地与匹配于学生模型,使得训练效果更好,一个重要的目标是对于同一任务,任意网络X可以从任意网络Y中获取有用的暗知识,进而引起测试效果的提升。
(2)为什么较低的教师模型准确率反而带来更高的学生模型的效果提升?
本文的主要贡献是:
(1)提出了一个新的视角来解释为什么知识蒸馏的优化原因。
(2)提出了一种量化其影响的评价方法。
(3)设计了一个高效的“宽容教师”框架,取得了优异的性能。
古语云:“青出于蓝而胜于蓝”
1.Introduce:
(1)硬标签会导致模型产生过拟合的现象。
注:从信息学的角度来说,即通过信息熵的计算soft logits相比于hard label确实是一个熵增的过程。
(2)相同网络架构的相互学习会超出彼此本身的训练性能极限。
注:再生神经网络(Born-Again Network)中提出的内容,有人说这篇文章的创新度不够,其实从根本来说是从不同的初始训练误差中逐渐逼近的过程,类似的方法可以为相关工作提供一些新思路,但实用价值不高,毕竟不会无限次的循环训练网络。
(3)本文主要从教师模型的严格性进行了讨论,并引入了训练教师模型的训练周期,尽管一定程度上减少了教师模型的测试精度,但给学生以更高的泛化学习的宽容度,并在实验后发现学生模型的学习效果达到了更好的程度。
注:2018年的后期知识蒸馏文章更多是希望将教师模型所提供的暗知识可以更好的传达给学生模型,在网络内部如多loss结合的方法,特征图注意力匹配的方法,黑箱模型学习的方法,拆分卷积的方法,引入GAN网络的方法等等,都是比较好的思路,但在推广和使用方面,我们更应该注意到算例损耗,训练效果之间的平衡,这也是阻碍知识蒸馏推广的阻力之一。
2.Related Work:
2.1 Deep Learning and Neural Networks
这里简单介绍了知识迁移对于对象检测、语义分割、边缘检测等内容都有比较重要的应用意义。
2.2. Training Very Deep Networks in Generations
这里指出对于处理图像相似性的问题,知识蒸馏是一个很好的方法,并在段落末尾介绍了使用各种监督,使用多名教师模型提供给学生模型更好的指导,在中间神经反应中添加监督,并允许两个网络互相帮助优化的等等方法。
3.Our Approach
3.1. TeacherStudent Optimization
这里引用是最常用的交叉熵的计算方法:
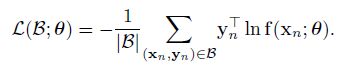
但是作者在这里想说明的是教师模型提供的软标签对学生模型的指导作用,故对原标签进行了优化,方法有点类似于Label smoothing Regularization(LSR)方法,在硬标签和软标签之间添加了权重值,这里基本和Hinton15年的处理方法相同:
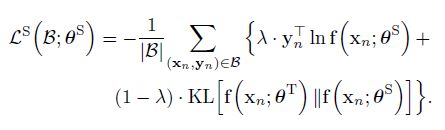
3.2. Preserving Secondary Information: An Important Factor in TeacherStudent Optimization
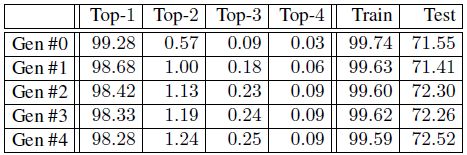
文章在第二节对于第二信度的标签予以的讨论,发现通过训练虽然第一标签的概率降低了,但是增加了模型的泛化能力,使得模型对于测试概率有了1%的效果提升:
本节得到的理论结论是:深层网络能够自动地为每个图像学习语义相似的类。将其命名为次要信息,与有监督数据提供的主要信息相对应。通过获取这些与图像相关的信息,学生网络可以避免对不必要的严格分布进行拟合,从而更好地泛化。
3.3. Towards HighQuality Secondary Information
通过3.2节的测试,已经确定了第二置信度软标签对于数据泛化能力的影响,本节主要讨论的是如何高效的使用这些二技标签,并指出常用的方法有label smoothing regularization (LSR) and confidence penalty (CP)两种方法,它们都是在原有的交叉熵函数上引出了一些添加项,同时也都有两个缺点:不管这些类在视觉上是否与训练样本相似,它们都有助于在所有类中分布信心分数。
作为第三种选择,本文提出了一个更合理的方法。没有计算所有类的额外损失,而是挑选了几个具有最高置信度分数的类,并假设这些类在语义上更可能与输入图像相似。设置了一个固定的整数K,代表每个图像语义上合理的类的数量,包括主类。然后,我们计算初级类与其他得分最高的K- 1类之间的差距:

本文将此方法命名为top score difference (TSD)。
在文中还分别计算了每个超类内部和不同超类之间的两个统计量

并在ResNet上进行了效果测试:
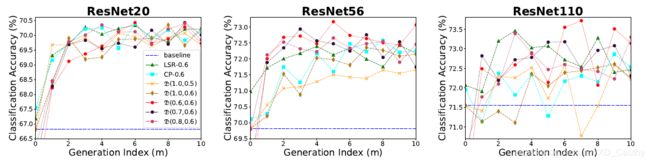

文中还在后面在CIFAR-100和ILSVRC2012数据集上进行了测试,性能提升3%到8%不等。