Neutral Graph Collaborative Filtering——论文提炼
目录
- Abstract
- KEYWORDS
- 1 INTRODUCTION
- 2 METHODOLOGY
- 2.1 Embedding Layer
- 2.2 Embedding Propagation Layers
- 2.2.1 First-order Propagation
- 2.2.2 High-order Propagation
- 2.3 Model Prediction
- 2.4 Optimization
- 2.4.1 Model Size
- 2.4.2 Message and Node Dropout
- 2.5 Discussions
- 2.5.1 NGCF Generalizes SVD++
- 2.5.2 Time Complexity Analysis
- 3 RELATEDWORK
- 3.1 Model-based CF Methods
- 3.2 Graph-Based CF Methods
- 3.3 Graph Convolutional Networks
- 4 EXPERIMENTS
- 4.1 Dataset Description
- 4.2 Experimental Settings
- 4.2.1 Evaluation Metrics
- 4.2.2 Baselines
- 4.2.3 Parameter Settings.
- 4.3 PerformanceComparison(RQ1)
- 4.3.1 Overall Comparison.
- 4.3.2 Performance Comparison w.r.t. Interaction Sparsity Levels.
- 4.4 Study of NGCF(RQ2)
- 4.4.1 Effect of Layer Numbers.
- 4.4.2 Effect of Embedding Propagation Layer and LayerAggregation Mechanism.
- 4.4.3 Effect of Dropout.
- 4.5 Effect of High-order Connectivity(RQ3)
- 5 CONCLUSION AND FUTURE WORK
Abstract
1.对user和item的向量表示(如embedding)是现代推荐系统的核心。
2.从矩阵分解到最近出现的基于深度学习的方法,现在的工作通常是通过描述user(item)的现有特征映射来获得embedding,缺点是:user-item中潜在的交互collaborative signal没有嵌入,因此,这种embedding不能捕获协同过滤效果。
3.本文建议将user-item整合到二部图(定义)结构中去,提出NGCF算法,该算法在图上传播embedding,这导致了表示模型的高阶连接性(high-order connectivity)。
4.将本模型在三个公开的基准数据集上做了实验,跟其他模型进行了对比,如MF、HOP-Rec和Collaborative Memory Network(CMN),进一步分析证明了 embedding propagation 的重要性。
5.实验代码:https://github.com/ xiangwang1223/neural_graph_collaborative_filtering.
KEYWORDS
Collaborative Filtering,Recommendation,High-order Connectivity, Embedding Propagation,Graph Neural Network
1 INTRODUCTION
1.推荐系统被广泛应用,它的核心是基于历史交互预测一个用户是否会选择某item,CF通过假设行为相似的用户会对同一item表现出相似的偏好来解决这个问题,为了实现这个假设,通常通过参数化user和item来重建历史交互,并且基于参数去预测用户的偏好。
2.两个关键因素:
(1)embedding,将user和item转化成向量化表示;
(2)interaction modeling ,重建基于embedding的历史交互。
例:MF用内积直接嵌入;collaborative deep learning从item的边信息中整合深度学习到的representations(embedding function );neural collaborative filtering 用非线性神经网络(interaction function);translation-basedCF用Euclidean distance metric(interaction function)。
3.上述模型都不能为CF产生好的embedding,关键是embedding function 缺乏对collaborative signal的显式的编码,这种signal是在user-item之间潜在的交互,它可以反映users(or items)间的行为相似度,大部分现存方法建立embedding function仅仅使用表面特征而不考虑user-item间的交互,所以是低效的。
4.这种方式是有效且操作困难的,当信息规模较大时更难提取有效的collaborative signal,针对这个问题,本文提出利用high-order connectivity,可以很方便的在交互图结构上编码collaborative signal。
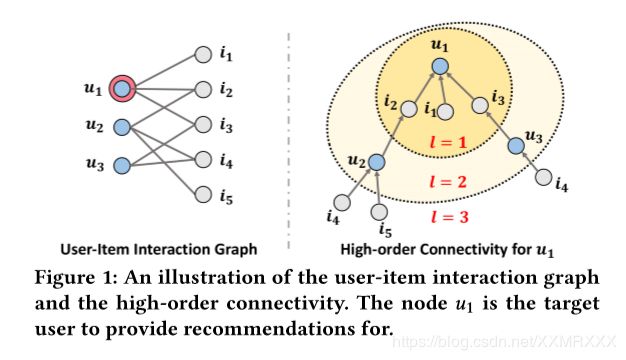
5.图 1 展示了一个 user-item 的二部图及 u1 的高阶连接性。u1 的高阶连接性表示 u1 通过长度大于 1 的路径连接到的节点。例如,u1 通过长度 l=2 的路径连接到 u2 和 u3,这代表 u1 的 2 阶连接性;u1 通过长度 l=3 的路径连接到 i4,i5,这代表 u1 的 3 阶连接性。需要注意的是,虽然 i4 和 i5 都是 u1 的 3 阶邻居,但是 i4 可以通过更多的路径连接到 u1,所以 i4 与 u1 的相似度更高。
6.本文设计了一个embedding propagation层,这层通过聚合有交互的items(or users)
的embedding来更新一个user(or item)的embedding。通过堆叠多个嵌入传播层,我们可以增强embedding在高阶连接性中去捕获交互信号的能力。
7.HOP-Rec考虑了high-order connectivity,但是它仅仅提出去enrich 训练数据,其预测模型仍为MF,通过优化具有高接连通行的损失进行训练,我们提出了将高阶连通性整合到预测模型中,该技术优于HOP-Rec。
(1)强调了在基于模型的CF方法的嵌入函数中显式的利用collaborative signal的重要性;
(2)提出NGCF,在embedding propagation层中以高阶连通性的形式显式的编码collaborative signal;
(3)实验研究证明模型的可行性和有效性。
2 METHODOLOGY
1.NGCF模型主要包含三个部分:
(1)Embedding Layer:将 user 和 item 的 ID 映射为向量初始化表示;
(2)Embedding Propagation Layers:联合高阶连通性来更新embedding
(3)Prediction:聚合来自传播层的更新embedding,输出预测结果
模型架构图见 Figure 2。
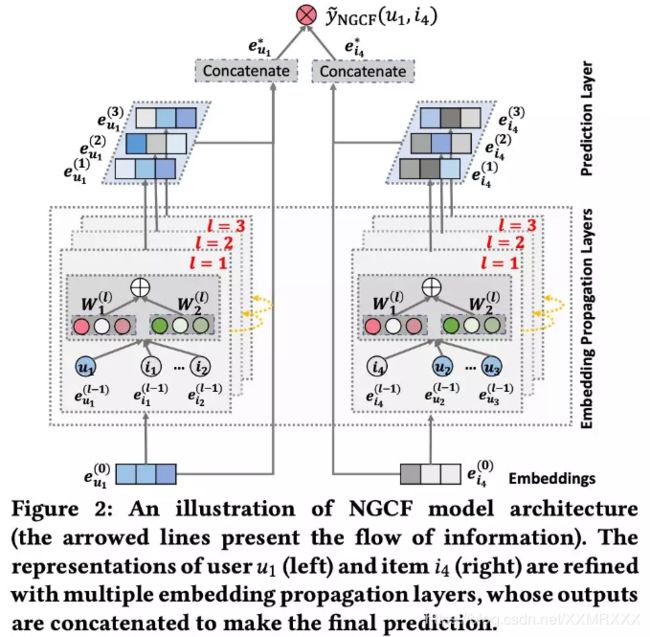 2.最后,讨论NGCF的时间复杂度和与现存方法的联系。
2.最后,讨论NGCF的时间复杂度和与现存方法的联系。
2.1 Embedding Layer
1.主流模型中,描述一个user u 用一个 embedding 向量 e u ∈ R d e_u \in R^d eu∈Rd,这可以看作建立一个参数矩阵作为一个嵌入查找表:

2.embedding表作为user embedding 和 item embedding的初始化状态,以端到端的方式进行优化 。
3.传统推荐模型,像MF和神经网络协同过滤把ID嵌入直接被喂到交互层去完成预测,相反在NGCF模型中,我们通过把embedding传到user-item交互图中去更新它们,由于embedding更新中显式的注入了collaborative signal而使embedding变得更加高效。
2.2 Embedding Propagation Layers
1.为了捕获图结构上的CF signal和细化user和item的embedding,我们建立了基于GNN的消息-传递结构。
2.我们首先设计了单层传播,然后将其推广到多层连续传播。
2.2.1 First-order Propagation
1.交互item对一个用户偏好提供直接证据,类似的,用户消费一个item可以看成是item的特征,用于度量两个item之间的协同相似性。
2.构建有关联的user和item的嵌入传播流程,主要包括两个步骤:消息构建和消息聚合
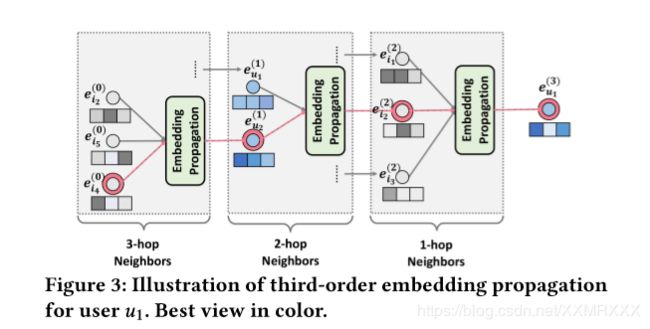
Message Construction:对于有关联的user-item对,我们定义从i到u的消息为:
![]()
m u ← i m_{u \leftarrow i} mu←i是消息embedding, f ( ⋅ ) f(·) f(⋅)是消息编码函数, e i e_i ei和 e u e_u eu作为输入,利用系数 p u i p_{ui} pui控制边 ( u , i ) (u,i) (u,i)上每次传播的衰减因子。
f ( ⋅ ) f(·) f(⋅)的实现:
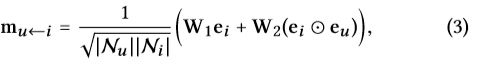
3. W 1 , W 2 W_1 , W_2 W1,W2是 d ′ ∗ d d^{'}*d d′∗d维的权值矩阵,去提取有用信息进行传播, d ′ d^{'} d′是变化大小,传统图卷积神经网络只考虑 e i e_i ei的作用,本文中我们通过 e i ⊙ e u e_i\odot e_u ei⊙eu把 e i e_i ei和 e u e_u eu之间的交互编码到传递的信息中,这使得消息依赖于 e i e_i ei和 e u e_u eu之间的关联性,传递更多来自相似items的消息。
4. 令 p u i p_{ui} pui作为正则化系数 1 ∣ N u ∣ ∣ N i ∣ \frac{1}{\sqrt{|N_u||N_i|}} ∣Nu∣∣Ni∣1, N u N_u Nu和 N i N_i Ni表示user u 和 item i的第一跳的邻居。从表示学习观点看, p u i p_{ui} pui表示历史item对用户偏好的贡献程度,从消息传递的观点看, p u i p_{ui} pui被看成是一个折扣因子,表示消息在传播过程中的衰退。
Message Aggregation:
1.聚合从u的邻居传来的信息去更新u的表示,聚合函数为:

e u ( 1 ) e_u^{(1)} eu(1)表示用户u在经过第一嵌入传播层之后的表示,除了邻居的传入外,还考虑了u的自连接: m u ← u = W 1 e u m_{u\leftarrow u = W_1e_u} mu←u=W1eu,它包含了信息的原始特征,对于 e i ( 1 ) e_i^{(1)} ei(1)类似.
2.嵌入传播层的优点在于:显式的利用一阶连接性去联系用户和商品的表示。
2.2.2 High-order Propagation
1.一阶连接性可以使得表示进一步准确,可以通过堆叠嵌入传播层去扩展高阶连接性信息,高阶连接性对于编码协同信号去估计用户和商品间的关联性来说是很重要的。
2.通过堆叠l个嵌入传播层一个用户能够收到它的l跳邻居传来的消息,如图二所示,在第l步,用户u的递归表示为:
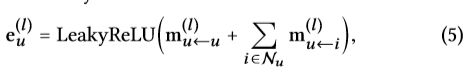
被传递的消息定义如下:
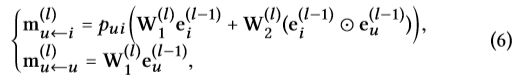
W 1 ( l ) , W 2 ( l ) , ∈ R d l ∗ d l − 1 W_1^{(l)},W_2^{(l)},\in R^{d_l*d_{l-1}} W1(l),W2(l),∈Rdl∗dl−1是训练的变换矩阵, d l d_l dl是变换大小。
3.如图三所示,协同信号例如 u 1 ← i 2 ← u 2 ← i 4 u_1\leftarrow i_2\leftarrow u_2\leftarrow i_4 u1←i2←u2←i4可以被嵌入传播过程捕捉,来自 i 4 i_4 i4的消息被显式的编码在 e u 1 ( 3 ) e_{u_1}^{(3)} eu1(3)中。
4.Propagation Rule in Matrix Form分层传播的矩阵形式:

其中 E ( l ) ∈ R ( N + M ) ∗ d l E^{(l)}\in R^{(N+M)*d_l} E(l)∈R(N+M)∗dl是用户和商品在l步嵌入传播之后的表示, I I I表示单位阵, L L L表示user-item图的拉普拉斯矩阵,其形式为:
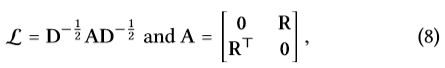
其中 R ∈ R N ∗ M R \in R^{N*M} R∈RN∗M是用户商品交互矩阵, A A A是邻接矩阵, D D D是对角度矩阵,其中 D t t = ∣ N t ∣ D_{tt}=|N_t| Dtt=∣Nt∣,矩阵化可以使得所有用户和商品进行高效表示,可以不必节点采样。
2.3 Model Prediction
1.在经过L层传播之后,我们包含了多层表示:{ e u ( 1 ) , e u ( 2 ) , . . . , e u ( L ) e_u^{(1)},e_u^{(2)},...,e_u^{(L)} eu(1),eu(2),...,eu(L)},我们级联他们区组成一个user的最终嵌入,对item来说类似:
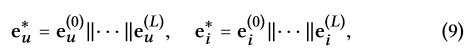
||是级联操作,可以丰富初始化embedding,也可以通过调整L来控制传播的范围,除了级联,其他聚合方式也可,例如权重均值,最大池化,LSTM等,级联相对简单,它不用添加参数,在GNN中比较高效,设计层聚合机制。
2.最后用内积去预估用户对目标item的偏好程度:
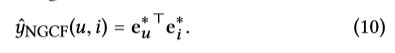
我们强调嵌入函数学习,因此交互函数仅仅使用内积,还有基于神经网络的交互函数,留作后续思考。
2.4 Optimization
1.采用BRP损失进行优化,这在推荐系统中比较常见,它考虑可观察的和不可观察的user-item交互的相对顺序,BRP认为可观察的交互可以更好地反映用户偏好,相比于不可观察的交互应该给予更高的预测值,目标函数如下:

O = { ( u , i , j ) ∣ ( u , i ) ∈ R + , ( u , j ) ∈ R − } O = \{(u,i,j)|(u,i)\in R^+,(u,j)\in R^-\} O={(u,i,j)∣(u,i)∈R+,(u,j)∈R−}表示训练数据对, R + R^+ R+表示可观察的交互, R − R^- R−表示不可观察的交互, Θ = { E , { W 1 ( l ) , W 2 ( l ) } l = 1 L } Θ=\{E,\{W_1^{(l)},W_2^{(l)}\}_{l=1}^L\} Θ={E,{W1(l),W2(l)}l=1L}表示训练模型参数, λ \lambda λ控制正则项防止过拟合,采用mini-batch Adam对预测模型进行优化并更新参数。
2.4.1 Model Size
1.虽然NGCF在每一个传播层包含一个嵌入矩阵 E ( l ) E^{(l)} E(l),但是它仅仅引进了很少的参数(两个 d l ∗ d l − 1 d_l*d_{l-1} dl∗dl−1维的权重矩阵),这些嵌入矩阵起源于 E ( 0 ) E^{(0)} E(0),基于user-item图结构和权重矩阵进行变换。
2.比起MF,NGCF的参数仅仅多出 2 L d l d l − 1 2Ld_ld_{l-1} 2Ldldl−1个,比起users和items的数目几乎可以忽略不计。
2.4.2 Message and Node Dropout
1.深度学习虽然表示能力强大,但是经常过拟合,丢弃可以有效防止神经网络中的过拟合,我们提出了NGCF的两种丢弃策略:
(1)消息丢弃:以概率 p 1 p_1 p1随机丢弃产出的消息,
(2)节点丢弃:随即阻止一个特殊节点并丢弃他的全部输出消息,对于第 l l l个传播层,我们从拉普拉斯矩阵中随机丢弃 ( M + N ) p 2 (M+N)p_2 (M+N)p2个节点, p 2 p_2 p2是丢弃比率。
2.丢弃仅被用在训练阶段,禁止在测试阶段丢弃。
2.5 Discussions
首先真是NGCF怎么概括SVD++,然后分析了NGCF的时间复杂度。
2.5.1 NGCF Generalizes SVD++
1.SVD++可以被看作没有高阶连接层的NGCF,即设置L为1,在传播层不使用变换矩阵和非线性函数, e u ( 1 ) e_u^{(1)} eu(1)和 e i ( 1 ) e_i^{(1)} ei(1)即user和item的最终表示,这个简化模型又称NGCF-SVD:
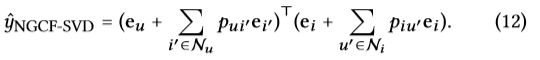
通过设置 p u i ′ p_{ui^{'}} pui′和 p u ′ i p_{u^{'}i} pu′i分别等于 1 ∣ N u ∣ \frac{1}{\sqrt |N_u|} ∣Nu∣1和0,可以恢复SVD++模型,另一种广泛使用的基于item的CF模型,FISM,也可以被看成一种特殊的NGCF,其 p u i ′ p_{ui^{'}} pui′被设置为0.
2.5.2 Time Complexity Analysis
略
3 RELATEDWORK
模型对比。
3.1 Model-based CF Methods
1.现代推荐系统通过向量化表示和重建基于模型参数的user-item交互数据来参数化用户和商品。例如MF,使用每个用户和商品的ID作为嵌入向量并且通过它们间的内积去预测交互。
2.为了增强嵌入函数,大量工作专注于整合边信息。
3.虽然内积可以表示相近的用户和商品之间的可观察的交互,但是他的线性性质使得它不能充分的去刻画复杂的非线性的关系。
4.针对真个问题,最近使用深度学习方法去增强交互函数,以使得它能够捕获非线性特征交互。
5.例如,neural CF models比如NeuMF使用非线性神经网络作为交互函数,同时,translation-based CF models比如LRML,用欧几里得距离矩阵代替了模型中的交互项。
6.尽管取得伟大成功,但是我们认为嵌入函数不足以为CF产出最优嵌入,因为CF信号仅仅被显式捕获。
7.嵌入函数将可描述性特征(ID和属性)转化为向量,交互函数作为向量的相似性度量。理想状态下,当user-item交互被完整重构时,可以捕获行为相似性的传递性属性。然而,这种传递效果不能被显式编码,因此不能保证在迁入空间中简介响亮的用户和商品是相近的。
8.不能显式的编码CF信号,就很难获得能达到理想状态的embedding。
3.2 Graph-Based CF Methods
1.利用user-item交互图去推测用户偏好,早期工作中,ItemRank and BiRank,使用标签传播去捕获CF效果,标签即为他的交互商品,并且在图上传播标签。
2.由于推荐系统的评分是基于历史item和目标item之间的结构相似度获得的,这些方法也属于基于邻居的方法,由于缺乏模型参数来优化目标函数,这些方法理论上不如基于模型的CF方法。
3.HOP-Rec将基于图的方法和基于嵌入的方法相结合,他首先使用随机游走去丰富一个用户和其多跳连接的item之间的交互,然后使用BRP在已经丰富的交互数据上去训练MF,对比发现HOP-Rec 优于MF,证明了整合关联性信息对于在捕获CF效果中获得较好的嵌入是有效的。
4.HOP-Rec没有充分使用高阶连接性,,仅仅利用了丰富的训练数据,而不是直接改进模型的嵌入函数,HOP-Rec很大程度上依赖于随机游走,这需要仔细的条有工作,比如设置适当的衰减因子。
3.3 Graph Convolutional Networks
1.通过在user-item交互图上设计一个图卷积操作,使得NGCF能够有效的利用高阶连接性的CF信号,这里我们讨论现存的也使用图卷积操作的推荐方法。
2.GC-MC在user-item图上使用图卷积操作,然而它仅对用户和商品的直接连接性使用一个卷积层,因此他不能表示高阶连接性的协同信号。
3.PinSage是一种工业解决方案,它在item-item图上使用多个图卷积层来做Pinterest imagine 推荐。CF效果在商品级别上被捕获,而不是跟用户行为协同。
4.SpectralCF提出谱卷积操作在谱域发现了在用户和商品间的所有可能的连接性,通过对图的邻接矩阵进行特征分解,可以发现user-item对之间的关联,但是特征分解计算量较大,非常耗时且不适合大规模推荐场景。
4 EXPERIMENTS
1.我们在三个数据集上做实验去评估我们的方法,特别是嵌入传播层,我们主要是为了回答下面的问题:
(1)与目前最先进的CF方法相比,NGCF的性能如何?
(2)不同的超参数设置(如层深度,嵌入传播层,层聚合机制,消息退出和节点退出),如何影响NGCF?
(3)如何利用高阶连接性进行表示?
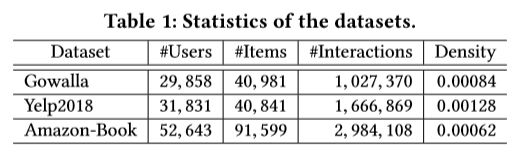
4.1 Dataset Description
1.概括统计三个数据集在表一
2.随机挑选80%作为训练集,剩下20%为测试集,在训练集中挑选10%作为交叉验证集去优化超参数。
3.对每个观察到的user-item交互,把它作为一个正例,通过消极抽样策略去把该交互和一个用户之前没有使用过的消极item进行配对。
4.2 Experimental Settings
4.2.1 Evaluation Metrics
1.对于每个测试集中的user,我们吧该用户没有交互过的item都当做消极item,然后每个方法输出用户对所有item的喜好分数,出了训练集中使用的积极的item,为了评估K阶推荐和偏好的排序有效性,使用两个评估协议recall@K andndcg@K,默认K=20.
4.2.2 Baselines
为了显示有效性,我们将NGCF与下面的方法对比:
MF这是贝叶斯个性化排序BRP损失优化后的矩阵分解,利用user-item的直接交互作为交互函数的目标值。
NeuMF 最先进的神经网络CF模型,在用户和商品嵌入的每个元素上和级联上使用多个隐藏层,并去捕获他们的非线性特征交互,我们采用了立案层平面结构,并且每个隐藏层的维数保持不变。
CMN 最先进的基于记忆的模型,用户表示通过记忆层组合了邻居用户的记忆片,一阶连接被用于查找与相同商品交互的相似用户。
HOP-Rec 最先进的基于图的模型,高阶邻居源于随机游走被用作丰富user-item的交互数据
PinSage 是在item-item图上使用GraphSAGE ,本文中我们在user-item交互图上使用PinSage,使用两个图卷积层,隐藏层维度被设置成等于嵌入大小。
GC-MC应用GCN编码去省城用户和商品的表示,仅考虑一阶邻居,因此只有一个图卷积层,隐藏层维度被设置成等于嵌入大小。
SpectralCF使用矩阵分解,导致时间复杂度过高,不选择它进行比较。
4.2.3 Parameter Settings.

4.3 PerformanceComparison(RQ1)
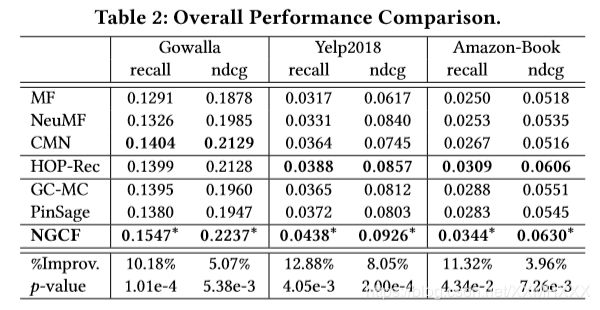
4.3.1 Overall Comparison.
1.MF表现最差,表明仅仅通过内积不能充分捕获用户和商品的复杂联系。NeuMF比MF表现略好,表明了在用户和商品嵌入间的非线性特征交互的重要性,然而上述两种模型都没有考略嵌入学习过程的连接性。
2.GC-MC证明,整合一阶邻居可以提高表示学习能力。
3.CMN优于GC-MC,这可能归功于神经网络的注意力机制,它可以指定每个邻居用户的注意力权重,而不是使用相等的或启发式权重。
4.PinSage略微低于CMN,在嵌入函数中引入高阶连通性。利用高阶邻居来丰富训练数据,而CMN只考虑相似的用户。
5.NGCF性能最佳。通过叠加多个嵌入传播层,显式的探索高阶连接性,而CMN和GC-MC只用一阶邻居来指导表示学习。
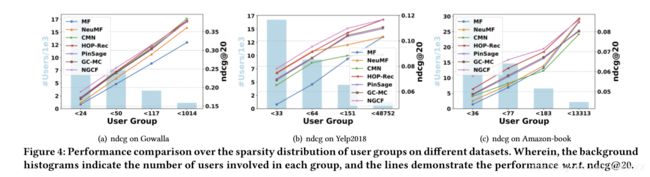
4.3.2 Performance Comparison w.r.t. Interaction Sparsity Levels.
稀疏性问题通常限制了推荐系统的表达能力。
根据不同稀疏程度分组实验结果如下:
4.4 Study of NGCF(RQ2)
研究嵌入传播层对NGCF的影响,探索层数影响,研究拉普拉斯矩阵,分析节点退出和消息退出比率等因素。
4.4.1 Effect of Layer Numbers.
改变模型深度={1,2,3,4},实验结果如下:
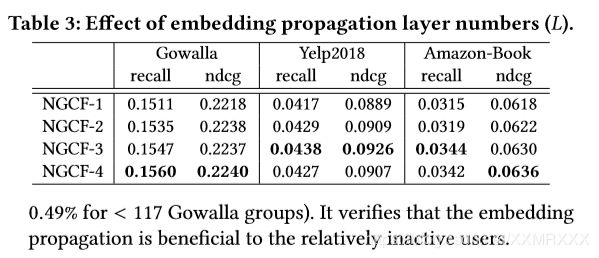
NGCF-2和NGCF-3在各方面都比NGCF-1优秀,因为NGCF-1只考虑一阶邻域,当NGCF-3进一步叠加传播层时,出现了过拟合现象,应用太深的架构导致引入噪声。
4.4.2 Effect of Embedding Propagation Layer and LayerAggregation Mechanism.
4.4.3 Effect of Dropout.
使用节点退出和消息退出来防止过拟合。节点退出的性能较好。

4.5 Effect of High-order Connectivity(RQ3)

5 CONCLUSION AND FUTURE WORK
将注意力机制引入,在嵌入传播过程中来学习变化权重。