深度学习能够训练计算机来执行人类的任务,例如:识别语音,辨认图像或进行预测等。

不同于用定义好的方程处理数据的传统模式,深度学习设置好关于数据的基本参数,并训练计算机自己进行学习。
为何深度学习如今这么重要?
为了使应用程序能够理解用户的输入并同样以人类的形式做出反馈,研究人员对作为认知计算的基石之一的深度学习进行了大量的研究。到如今,深度学习技术已经极大的增强了计算机分类、辨识、发现与描述的能力,或者说增强了其理解的能力。
很多应用已经被用在处理非数字化的数据,例如:图像分类、语音识别、物品检测和内容描述。像 Siri 和 Cortana 的系统也要归功于基于深度机器学习的认知计算。
深度学习取得的进步得力于一些技术的发展。算法的改善提高了深度学习方法的性能,机器学习准确性的提高创造了巨大的商业价值。完美适用于文本翻译和图像分类应用的新型神经网络也已经得到实现。
尽管神经网络已经存在近50年的时间,但是直到上世纪90年代末,由于可用于训练的数据不足,一直无法得到精确的结论。革命性的转机出现在最近10年:
我们有了足够建立更多更深层神经网络所需的数据,包括来自物联网的流数据,来自社交媒体的文本数据,医疗记录和研究报告。
分布式云计算和 GPU 的发展给我们提供了训练深层算法所必须的计算能力。
与此同时,人机界面也得到了很大的进化。鼠标与键盘正在被手势、动作、触摸和自然语言所代替,认知计算迎来了新的发展契机。
发展的契机
深度学习算法的迭代性质导致它们的复杂性会随着层数加深而增加,网络也需要庞大的数据量来进行训练。自然,深度学习问题需要有庞大的计算能力进行支持。

传统的建模方法是很好理解的,它们的预测方法和业务规则也很容易说明。而深度学习却更像是一个黑箱方法。你可以通过用新数据训练它们来证明它们运行正常。但是由于它们非线性的本质,为什么会得到一个特定的结果却很难进行解释。这种特性可能会对深度学习技术的实际应用造成一些阻力,在高度管制的工业生产中更是如此。
另一方面,基于学习方法的动态特性,它们能够持续进行改进并适应基础信息模式的变化,这种能力能够在分析时引入更少的确定性,进行更动态行为的模拟。这一特性可以用在进行更个性化的用户分析中。
趁计算能力发展的契机,长久以来部署的神经网络应用的准确性与性能也得到了很大的提高。有更好的算法和计算能力支持,它们的深度也能够继续增加。
深度学习的应用
外界看来,深度学习也许仍处于计算机科学家和数据专家们正在对其能力进行测试的研究阶段,实际上,深度学习已经有一些实际的商业应用,随着研究的进行,更多的应用也将实现。目前主要的应用有:
语音识别:商业和学术界都在使用深度学习进行语音识别。Xbox,Skype,Google Now 和 Apple Siri,都已经在其系统中采用深度学习技术。
图像识别:图像识别的一个实际应用是自动图像说明和场景描述。这对于在一个拥挤地区有犯罪发生时,从旁观者提交的数千张照片中查明犯罪活动的执法调查至关重要。自动驾驶汽车同样能从中受益。
自然语言处理:神经网络作为深度学习的核心组成部分,很多年来一直被用来分析和处理书面文本。专业化的文本挖掘可以用于处理用户投诉,医疗记录或新闻报道。
推荐系统:Amazon 和 Netflix 已经公布了一个推荐系统的点子,它们能够根据历史记录知道你最可能感兴趣的物品。深度学习也可以用来提高跨平台音乐,服装推荐系统的性能。
深度学习是如何工作的?
深度学习将告诉电脑如何解决问题的传统分析模式转变为训练电脑自己解决问题。
传统模型建立的过程是使用手头的数据来设计特征并导出新的变量,然后选择一个分析模型,最后估计它的参数。因为结果的完整性和正确性基于模型的质量和特征,这样的预测系统并不容易推广到其他问题上。例如:如果你想要开发一个具有特征工程的欺诈模型,从一组变量开始,使用数据转换从这些变量中导出模型。你可能最终会得到模型依赖的30000个变量,接着就需要找出这些变量中哪些是有意义的,哪些没有,等等。如果增加更多的数据你又要将这些重新来过。而应用深度学习的新方法是使用适当的层次化特征替换模型的公式和规范,并根据层中的规律识别出数据的隐藏特征。
深度学习的范式转变是从特征工程到特征表示的转变。使用深度学习可以开发出概括性强,适应性好,能使用新数据持续进行完善的系统。比建立在确定性业务规则上的预测系统更具动态性。我们不再是去适应一个模型,而是去训练一个模型。
下面为大家介绍一个深度学习模型—卷积神经网络
卷积神经网络是模拟动物脑部视觉皮层而建立起来的,其特点是单个神经元只响应某个特定区域的刺激。它的主要结构包括卷积层,池化层,激活层,全连接层等。
1)卷积层

如图所示,卷积层中一个神经元能够关联输入层的一小块被称为接收场的区域,想象一下在卷积层用一个手电照向输入层,并在输入层上进行滑动,它所照亮的区域就是接收场。这把手电同样是由一组数据构成,被称作卷积核。
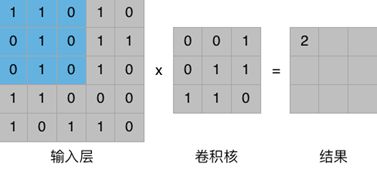
利用一个卷积核对输入层的信息进行过滤,将对应位置的像素值相乘再累加就可以得到一个卷积结果,将卷积核依次划过输入层的所有数据后,就完成了一次对原始数据的加工。用公式可以描述为:

2)权值共享
假设使用一幅1000*1000大小的图像作为网络的输入,此时输入层上有1000000个像素,如果网络的下一层也同样有1000000个神经元,采用全连接的方式时,每个神经元均与输入层的所有像素通过权值连接,此时网络中参数的数量是10^12,可以想到完成这些需要相当庞大的计算量。
那么,有没有办法减少这些计算量呢?
想想上面提过的感受野,如果我们让每个神经元只与输入层的10*10个像素连接,此时参数的数量减少到了100*1000000。现在,让我们的脑洞再大一点,如果所有的神经元都是用同一组权值会怎么样?当1000000个神经元共用一组权值的时候,参数的数量变成了100个!当然,使用一个卷积核只能提取到原数据一部分的特征,要提取更多的特征,我们把卷积核的数量提高到100个,此时参数的数量是100*100=10000个。可以看到参数已经较之前大大减少了!
3)池化层
池化层将输入数据划分为许多小的子区域,只提取每个子区域最大值的方法就称为最大值池化。池化层的意义在于提取出数据中的“显著特征”而忽略“细节特征”,以减少网络中的参数和计算量,并且能够控制过拟合。如图所示即是最大值池化。

4)激活层
激活层使用非线性激活函数:修正线性单元(Rectified Linear Units ReLU)
它的作用是使卷积计算结果中小于0的值等于0,其他的值保持不变。在不影响卷积层的接收场的同时增加了决策函数和整个网络的非线性属性。相较于其他激活函数
Tanh:
Sigmoid:
ReLU 不需要计算指数,能大幅提高神经网络的训练速度。
5)全连接层
全连接层一般放在网络的最后,对前一层得到的高阶特征进行分类。
原文地址:http://www.sas.com/en_id/insights/analytics/deep-learning.html#deepworks
本文作者:雷原嘉(点融黑帮),现就职于点融网工程部Fincore TechOps 团队,暴雪脑残粉一枚。