自然语言处理——文本相似度
文本相似度简述
- 前言
- 文本相似度算法
- 基于关键词匹配
- N-Gram相似度
- Jaccard相似度
- 基于向量空间
- Word2vec
- TF-IDF
- 向量空间与相似度计算
- 基于深度学习
- 卷积神经网络(CNN)
前言
在自然语言处理的学习和研究中,有好多问题涉及到如何检测两个文本的相似度问题,尤其是在度量句子或者短语之间的相似度。测算度量文本相似度的方法大体有三种:基于关键词匹配的传统方法、基于向量空间的方法和利用深度学习进行文本相似度检测的方法。随着近些年深度学习学科的发展,文本相似度的方法逐渐从基于关键词匹配的传统方法转变为深度学习,且结合向量空间和深度学习进行文本相似度检测。
文本相似度算法
基于关键词匹配
基于关键词匹配方法具有代表性的有:N-gram 相似度与Jaccard 相似度
N-Gram相似度
使用N-Gram相似度进行文本相似度匹配是一种模糊匹配方式,关键在于通过两个长的很像的句子之间的差异来度量相似度。
N-Gram相似度计算具体指假设有一个字符串,那么字符串的N-Gram表示为按照长度N切分这个字符串原句得到词段(词段即原句中所有长度为N的子串)。设想如果有两个字符串,然后分别求它们的N-Gram,那么就可以从它们的共有子串的数量这个角度去定义两个字符串间的N-Gram距离。通过N-Gram距离来判断这两个句子的相似程度。即: S i m i l a r i t y = ∣ G N ( S ) ∣ + ∣ G N ( T ) ∣ − 2 × ∣ G N ( S ) ∩ G N ( T ) ∣ Similarity=|G_N(S)| + |G_N(T)|-2 × |G_N(S)\cap G_N(T)| Similarity=∣GN(S)∣+∣GN(T)∣−2×∣GN(S)∩GN(T)∣ 其中, G N ( S ) G_N(S) GN(S)和 G N ( T ) G_N(T) GN(T) 分别表示字符串S和T的N-Gram集合,当 S i m i l a r i t y Similarity Similarity 值越低时,两字符串越相似。
N-Gram忽略了两个字符串长度差异可能导致的问题。比如字符串 girl 和 girlfriend,二者所拥有的公共子串数量显然与 girl 和其自身所拥有的公共子串数量相等,但是并不能据此认为 girl 和girlfriend 是两个等同的匹配。
Jaccard相似度
jaccard index又称为jaccard similarity coefficient。主要用于比较有限样本集之间的相似性和差异性。
原理:计算两个句子之间词集合的交集和并集的比值。该值越大,表示两个句子越相似,在涉及大规模并行运算的时候,该方法在效率上有一定的优势,公式如下: J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ = ∣ A ∩ B ∣ ∣ A ∣ + ∣ B ∣ − ∣ A ∩ B ∣ 0 ⩽ J ( A , B ) ⩽ 1 J(A,B)=\frac{|A\cap B|}{|A\cup B|}=\frac{|A\cap B|}{|A|+|B|-|A\cap B|} \quad\quad 0\leqslant J(A,B) \leqslant 1 J(A,B)=∣A∪B∣∣A∩B∣=∣A∣+∣B∣−∣A∩B∣∣A∩B∣0⩽J(A,B)⩽1 jaccard值越大说明相似度越高
Jaccard不相似度:与jaccard 系数相关的指标是jaccard距离用于描述不相似度,公式如下: d j ( A , B ) = 1 − J ( A , B ) = ∣ A ∪ B ∣ − ∣ A ∩ B ∣ ∣ A ∪ B ∣ = A Δ B ∣ A ∪ B ∣ d_j(A,B)=1-J(A,B)=\frac{|A\cup B|-|A\cap B|}{|A\cup B|}=\frac{A\Delta B}{|A\cup B|} dj(A,B)=1−J(A,B)=∣A∪B∣∣A∪B∣−∣A∩B∣=∣A∪B∣AΔB
jaccard相似度的缺点是只适用于二元数据集合。
基于向量空间
Word2vec
word2vec核心思想是认为词的意思可以从它频繁出现的上下文信息中体现。分为两种结构,一种是Skip-gram,利用中心词预测窗口内的上下文;另一种是CBOW,利用窗口内的上下文预测中心词。
以CBOW为例,CBOW是一种基于窗口的语言模型。一个窗口指的是句子中的一个固定长度的片段,窗口中间的词语称为中心词,窗口其他词语称为中心词的上下文。CBOW模型通过三层神经网络接受上下文的特征向量,预测中心词是什么。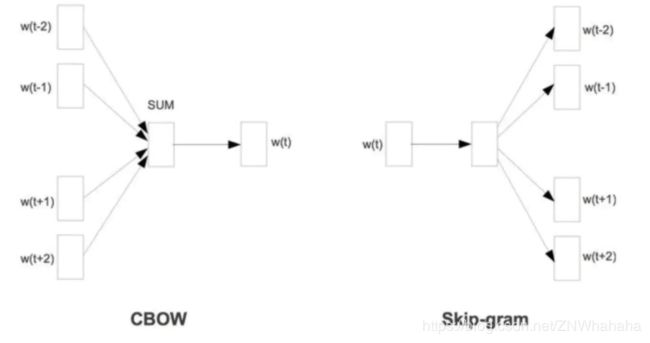
TF-IDF
TF-IDF的核心思想是:在一篇文章中,某个词语的重要性与该词语在这篇文章中出现的次数成正相关,同时与整个语料库中出现该词语的文章数成负相关.
TF(term frequency):词频,某一个给定的词语在该文件中出现的频率,表示一个词语与该文章的相关性。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。
IDF(inverse document frequency):逆向文件词频,表示一个词语出现的普遍程度。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到。
一篇文章中某个词语的重要程度,可以标记为词频和逆向文件词频的乘积. t f i d f = t f ∗ i d f tfidf=tf∗idf tfidf=tf∗idf 通过计算出文档中每个词的TF-IDF值,然后结合相似度计算方法(一般采用余弦相似度)就可以计算两个文档的相似度。
向量空间与相似度计算
假设有两个对象 X , Y X,Y X,Y,这两个对象都包括N维特征 X = ( x 1 , x 2 , . . . , x n ) X=(x_1,x_2, ... ,x_n) X=(x1,x2,...,xn), Y = ( y 1 , y 2 , . . . , y n ) Y=(y_1,y_2, ... ,y_n) Y=(y1,y2,...,yn),常用的计算 X X X和 Y Y Y相似性的方法有:欧氏距离、曼哈顿距离、余弦相似度等。
欧氏距离:最常用的距离计算公式,以多维空间各个点的绝对距离做衡量。适用于数据稠密且连续的情况。拿两个文档所有的词(不重复)在A文档的词频作为x,在B文档的作为y进行计算。 d = ∑ t = 1 n ( x i − y i ) 2 d=\sqrt{\sum_{t=1}^n(x_i-y_i)^2} d=t=1∑n(xi−yi)2 例如:A=你是个坏人、B=小明是个坏人 ,词频分别为A={1 0 1 1} 、B={0 1 1 1}。则距离为 2 ≈ 1.414 \sqrt 2 \approx 1.414 2≈1.414,再通过 1 ÷ ( 1 + 欧 几 里 德 距 离 ) 1 ÷ (1 + 欧几里德距离) 1÷(1+欧几里德距离)得到相似度。
曼哈顿距离:使用在几何度量空间的几何学用语,用以标明两个点上在标准坐标系上的绝对轴距总和。与欧氏距离有点像,即: d = ∑ i = 1 n ∣ x i − y i ∣ d=\sum_{i=1}^n|x_i-y_i| d=i=1∑n∣xi−yi∣ 同理 x n x_n xn和 y n y_n yn分别代表两个文档所有的词(不重复)在 A A A和 B B B的词频。
余弦相似度:余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。 cos θ = ∑ i = 1 n x i × y i ∑ i = 1 n x i 2 ∑ i = 1 n y i 2 \cos \theta = \frac{\sum_{i=1}^nx_i×y_i}{\sqrt{\sum_{i=1}^nx_i^2\sum_{i=1}^ny_i^2}} cosθ=∑i=1nxi2∑i=1nyi2∑i=1nxi×yi 例如:判断两句话
A=你是个坏人 B=小明是个坏人
(1)进行分词
A=你 / 是 / 个 / 坏人 B=小明 / 是 / 个 / 坏人
(2) 列出所有的词
{ 你 小明 是 个 坏人 }
(3)计算词频(出现次数)
A={1 0 1 1} (每个数字对应上面的字) B={0 1 1 1}
(4)后把词频带入公式
cos θ = 0.667 \cos\theta=0.667 cosθ=0.667
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫余弦相似度。
基于深度学习
卷积神经网络(CNN)
CNN通过设计卷积神经网络,结合不同规格的卷积神经网络的差异性度量句子的相似程度。
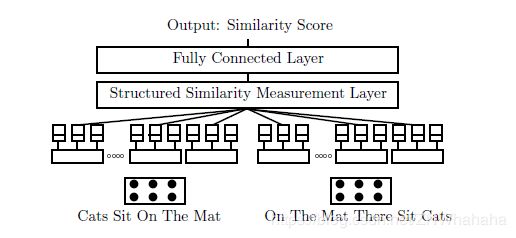
文章参考以下博客及书籍:
Vico_Men_浅析文本相似度
lbky_文本相似度
何晗_《自然语言处理入门》