吴恩达机器学习 学习笔记 之 二 :代价函数和梯度下降算法
二、
2-1 Model Representation
我们学习的第一个算法是线性回归,接下来会讲什么样的模型更重要,监督学习的过程是什么样子。
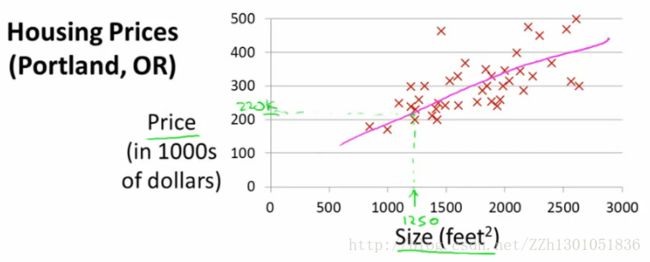
首先举一个需要做预测的例子:住房价格上涨,预测房价,我们拥有某一城市的住房价格数据。基于这些数据,绘制图形。
在已有房价数据集中,部分房子已售出,且我们知道这些房子的尺寸和售价。现在某人的房子是1250平方英尺,预测其可能的售价。
算法要做的是:
(1) 拟合模型
若采用直线拟合,可能售价$220,000。
这是一个监督学习的算法,因为每个样本都知道报价,即“正确答案”。。
这也是一个回归问题,因为我们预测连续的值,即价格。
定义一些符号;
x : 输入变量/特征(features)
y :输出变量/目标变量(target varibles)
(x,y):一个训练样例。
(x(i),y(i)):第i个训练样例。
监督学习的过程:
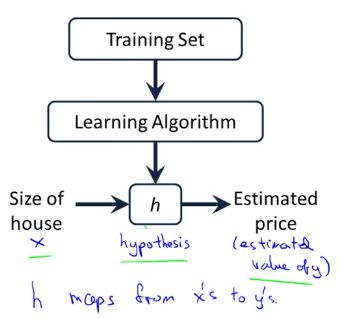
将训练数据集“喂给”学习算法,学习算法输出一个函数h,h代表假设。 h的任务是,输入房子的大小(x),输出房子的估价(y)。所以,h是一个函数,从x映射到y。为什么函数h被称为假设呢?或许这个名称对某些函数来讲并不是很合适,但这是机器学习中的标准术语,所以不需要纠结为什么这么称呼。
设计学习算法,下一步要做的是怎么表示假设h,后面的几节会讲述假设h的几种表示方法。例如在预测房价问题中该怎么表示h呢,一种可能的表示方法是:
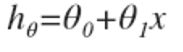
因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
下一节中讨论怎么实现该模型。
笔者的笔记可能有不够完整的地方,这里有一些很不错的文章,大家可以再浏览一遍,或许会有不一样的收获:
机器学习之单变量线性回归
斯坦福机器学习第二周线性回归、特征值标准、
2-2 Cost function —— 代价(或称损失)函数
这一节介绍代价函数,代价函数能帮我们找到数据的最佳拟合直线。
在线性回归中,用来进行预测的函数是:
其中,θ0 和 θ1 之类这些 θi ,称为模型参数,接下来要讲的就是如何选择这两个参数值。
使用不同的θi ,我们会得到不同的假设函数
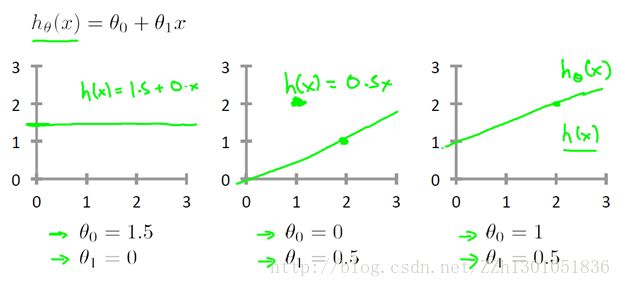
在线性回归中,我们有一个训练集,我们要做的就是得出 θ0 和 θ1 这两个参数的值,来让假设函数表示的直线尽量地与这些数据点很好的拟合。那么我们如何得出 θ0 和 θ1 的值,来使它很好地拟合数据的呢?
我们的想法是,输入 x 时,我们要确定参数θ0 和 θ1 的值,以使我们的预测值 h(x) ,最接近该样本(x)对应的 y 值。训练集中有一定数量的样本, x 表示某一所房子,我们也知道这所房子的实际价格。所以,我们要选择参数值,尽量使得在训练集中给出的 x 值,能准确地预测 y 的值。
在线性回归中,我们要解决的其实是最小化问题。在这里,即希望误差h(x) - y达到最小,此时(h(x) - y)的平方也达到了最小值。模型所预测的值与训练集中实际值之间的差距(下图中蓝线所指)就是建模误差(modeling error)。
我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。即:
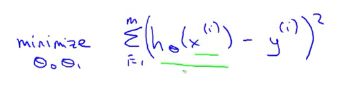
其中,用符号(x(i),y(i))代表第i个样本,我们需要对所有训练样本的建模误差平方进行求和。此时的输入是x(i),即第i个房子的面积。m是训练集的样本容量(有多少个样本,m就是多少)。
为了尽量减少平均误差,我们在前面乘上一个因子1/m,为了在数学上表达的更简单直白一些,再除以2,经过这些处理,得到的应是相同的θ0 和 θ1 。
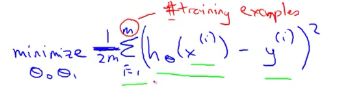
其中,htheta(x(i)) = theta0 + thetax(i)。

所以,问题就变成了,找到这样的θ0 和 θ1 ,使得训练集中预测值和真实值的差的平方和,的1/2m达到最小。这也就是该线性回归问题的目标函数了。
为了使上述函数更明确,按照惯例,定义一个代价函数,如下,
![]()
我们要做的就是求关于θ0 和 θ1 的J(θ0 , θ1 )的最小值,其中J(θ0 , θ1 )即代价函数(Cost Function)。代价函数也称为平方误差函数或平方误差代价函数。也还有其他的代价函数,但平方误差代价函数是处理回归问题时最常用的。
![]()
接下来,会详细讲解代价函数J的工作原理,以及使用它的目的。
综上,上面的函数及符号分别为:

2-3 Cost Function intuition1 — 代价函数
[本节概要]上节讲述了代价函数的数学定义,本节将给出一些代价函数的例子,来讲述代价函数是用来做什么的,以及为什么要使用它。
在上一节中,根据参数θ0 和 θ1 ,形成一个假设(Hypothesis)。选择不同的参数,我们得到不同的直线,从而得到不同的预测值,为了描述预测的准确程度,我们使用了假设函数(Cost Function)。

在本节中为了对代价函数进行可视化,我们使用一个简化的假设函数。

其中,假设函数(Htheta(x))和代价函数(J(theta1))是我们要格外注意的。假设函数可以用来预测房价,代价函数控制着直线的斜率。
下面对两种函数进行分析,左边是假设函数,训练集中有三个样例(1,1)、(2,2)(3,3)。以实例说明的话,X就表示房子的大小(Size)。
我们需要对θ1 取不同值,然后得到不同的平方误差和,当θ1 = 1时,有如下拟合直线和代价计算公式。
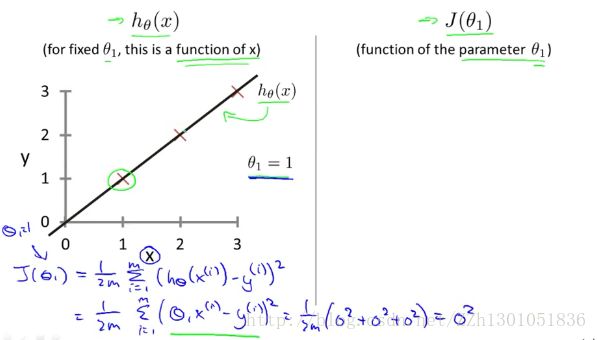
此时对应的代价函数J(1) = 0。故,在右侧,我们得到了一个点的坐标,其中横轴代表θ1 。
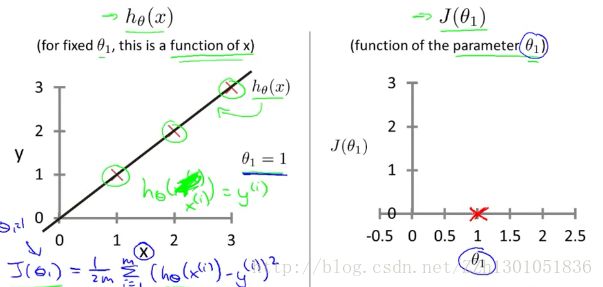
通过对θ1 取不同值,我们得到一系列代价函数的点,如下图:
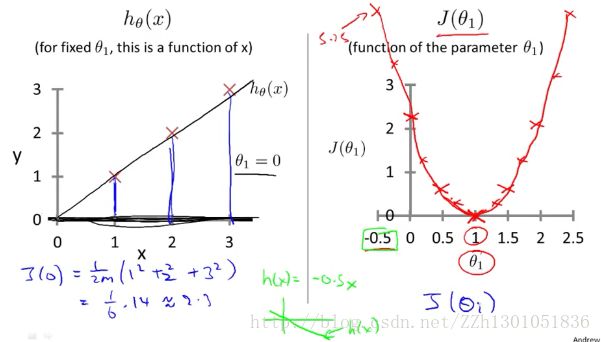
对于不同的θ1 ,对应着假设函数的不同值(左侧,一条不同的直线),对应着不同的J(θ1)的值。
我们的优化目标是,通过选择θ1 的值,尽可能的减小J(θ1)。在右侧,当θ1 = 1时,J(θ1)达到最小,此时我们找到了数据的最佳拟合直线hθ1 (x) = 1*x。这一例子说明了,为什么要使J(θ1)最小,来找拟合曲线。
2-4 Cost Funciton intuition2 —— 代价函数
[本节概要] 本节从更深层次上讲解代价函数做什么的。
下面是常用的公式:
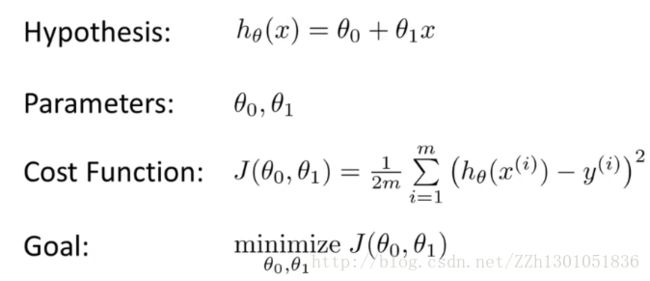
上节在对代价函数进行可视化时,只保留了一个参数θ1 ,本节将保留所有参数θ0 和θ1 。
下图左边是假设,右边是代价函数。假定设置θ0 = 50,θ1 = 0.06。
在上节中,只有一个参数,所以代价函数绘制完成后是一个“J(θ1 ) — θ1 ”二维曲线图,现在要表达两个参数与代价函数之间的关系,所以要建立一个3D曲面图。如下,注意θ0、θ1在横坐标轴上。(下图中这种情况,可以认为,J(θ0,θ1)的值最小时,(θ0,θ1)在(0,0)附近)
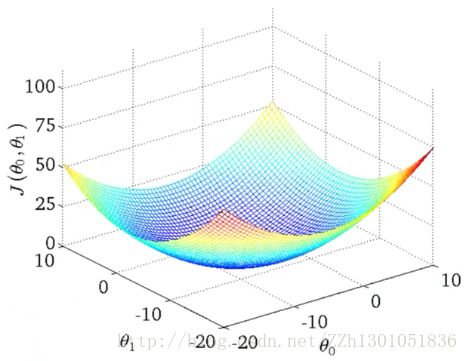
为了便于分析,下面不使用3D曲面图,而改用等高线图,如下面右图。轴坐标表示θ0 和θ1 ,椭圆形表示J(θ0 ,θ1)值相同的点,每一个椭圆都对应着一对θ0 ,θ1 。同心椭圆的中心点就是J(θ0 ,θ1)的最小值点,此时(θ0,θ1)大约在(0,0)附近。
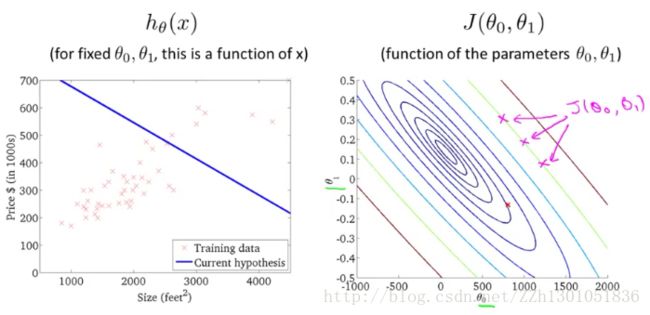
左边的拟合直线对应的代价函数,就是右边的大红色叉号所在的点。可以看出,该点离最小值点较远,说明拟合效果不佳。
换一条拟合直线,如下图。从左图可看出θ0 = 360,θ1 = 0。对应右边的椭圆曲线即红色叉号所在点。此时与最小值点又接近了一些。
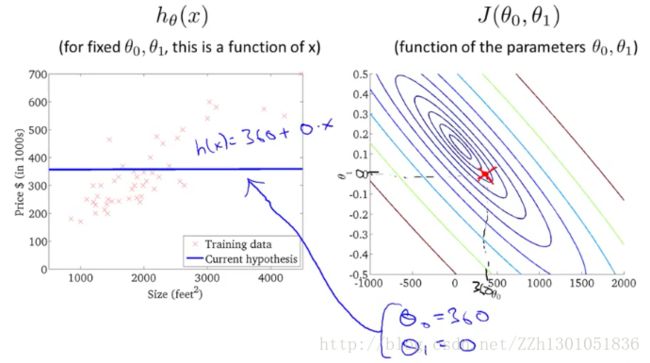
再换一种拟合函数,可以看出此时与最小值点已经十分接近了。平方误差和即所有点与假设函数距离的平方的和,如左图所示。
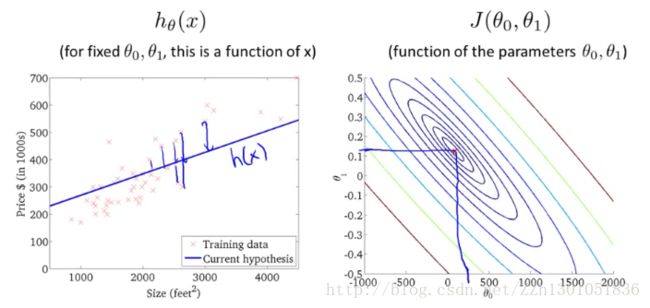
通过以上讲解,我们了解到代价函数J是如何拟合不同的假设函数的,当数据非常接近函数J的最小值时,假设函数到底能多好的拟合数据。
现在,我们真正迫切需要的是一个高效的算法,一个高效的软件,能自动寻找使J最小的θ0 和θ1 。因为当数据更复杂,参数更多时,我们甚至都不能绘制出图形。
后面将讲解寻找使J最小的θ0 和θ1 的值的算法。
2-5 Gradient Descent —— 梯度下降算法
本节介绍一种可以将代价函数最小化的算法——梯度下降算法。该算法被广泛地应用于机器学习的众多领域。
问题概述,对于代价函数J,可能有很多参数theta0~n,但为了简单起见,这里只讨论两个参数。

使用梯度下降算法的步骤:
(1)首先,随便给参数一个初始值,一般设置初始值为0。
在梯度下降算法中要做的是,不停地一点点改变θ0 和θ1 ,通过这种改变使J变小。直到我们找到了J的最小值,或许是局部最小值。
我们通过下面的图片,说明梯度下降算法是如何工作的。

首先希望大家把这幅图片想象成一座山,而你站在山上的某一点处。现在你要迈着小碎步一步一步地下山,并且希望能够尽可能快的下山,那你应该从哪个方向下山呢?当然是从最陡峭的地方下山,你找到了一个最陡峭的方向并迈出了一步,然后再重新找最陡峭的方向,你又迈出了一步,这样你就能以最快速度下山了。
而如果我们换一个起始点,按照相同的策略下山,我们可能会得到一个更快的路线(更优解,刚才的方法就是一个局部最优解了),如下图。
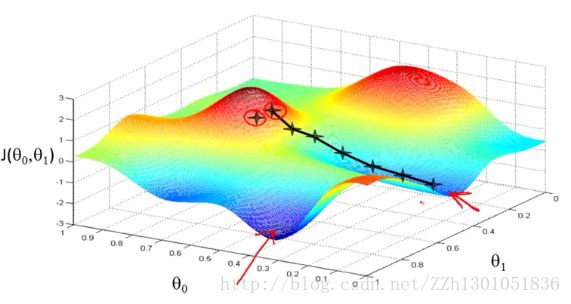
通过上面的例子,我们可以对梯度下降算法有一个初步的,形象的理解。
(2)反复更新θ0和θ1,以求得J的最小值
下面是梯度下降算法在数学上的定义,我们需要反复的更新参数θj 。其中的符号“:=”是一个赋值运算符;α是一个数字,表示学习速率,形象点说,它控制了我们下山时迈多大的步子,α值的设置会在后面讲解。当j=0和j=1时,更新θ0和θ1,值得注意的是,这里的更新是同时进行的。原理在左下方,使用临时变量temp0和temp1,保证了对θ0和θ1更新的同时性,右下方就是一个很明显的反例了。事实上,θ0和θ1更新的同时性也正是梯度下降算法的微妙之处。

下一节会讲解梯度下降算法的定义,以及算法公式中的偏微分项。
2-6 Gradient Descent Intuition —— 梯度下降算法
本节更深入的说明梯度下降算法做什么,以及梯度下降算法的更新过程有什么意义。
下面是梯度下降算法的数学定义,其中α的术语叫学习速率,它控制着以多大幅度更新参数θj。后面的是导数项。本节的目标就是说明这两部分有什么用,以及为什么有了这两部分后,更新过程才是有意义的。
我们举例来说明这两部分的作用。
首先解释导数项的意义,如下图。为了简便起见,我们这里只分析含一个参数(θ1)的代价函数J(θ1)。在两幅图中的曲线代表同一个代价函数。第一幅图中,我们假设取的初始值θ1在最小值点的右侧。那么J(θ1)在该点对θ1求得的导数是一个正数,θ1 = θ1 - α*正数,点会向最小值点移动。第二幅图与此相反,但原理相同。
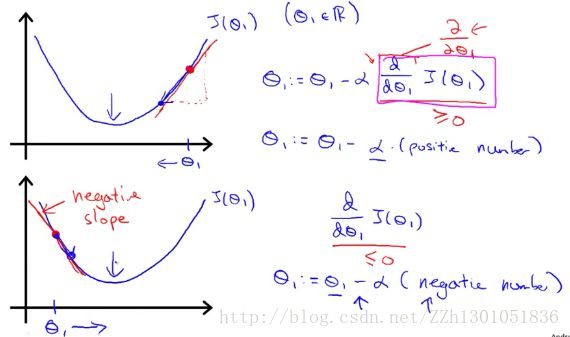
现在解释学习速率α的意义,如下图。第一幅图中,将学习速率取的小一些,那么将会像个baby一样很慢很慢得走向最低点。若是将学习速率取的太大,则有可能像第二幅图,步子迈得太大,跨过最低点,这样代价函数可能会发散。
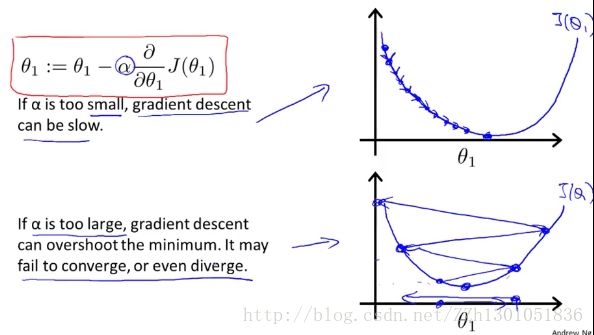
如果θ1取的初始值在(局部)最低点,那么接下来算法会怎么工作呢?
因为(局部)最低点处,导数部分为0,所以θ1 = θ1 - α*0,实际上θ1没有发生变化。
如下图,随着梯度下降法的不断运行,倒数部分会不断减小,从而使得“α*斜率”不断减小,θ1的变化幅度也就越来越小了。所以,没必要再减小α。
接下来,结合平方误差函数和代价函数,我们得出第一个算法——线性回归算法。
2-7 Gradient Descent For Linear Regression ——梯度下降的线性回归算法
在本节我们要将梯度下降函数和代价函数结合,并将其应用到线性回归算法。
下面是之前完成的工作,左边是梯度下降算法的数学表达式,右边是线性回归模型的线性假设和代价函数 。

我们将要做的是用梯度下降算法最小化平方差成本函数。
其中的偏导部分,化简后即:
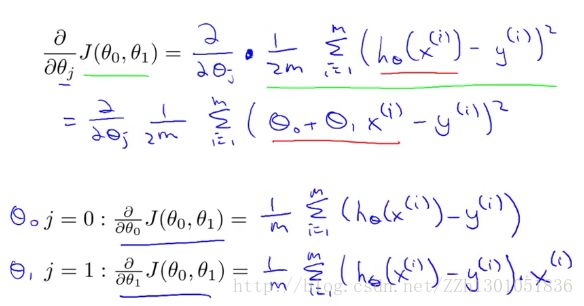
从而,梯度下降算法改写成如下这样:

该算法有时也称为批量梯度下降。”批量梯度下降”,指的是在梯度下降的每一步中,我们都用到了所有的训练样本,在梯度下降中,在计算微分求导项时,我们需要进行求和运算,所以,在每一个单独的梯度下降中,我们最终都要计算这样一个东西,这个项需要对所有m个训练样本求和。因此,批量梯度下降法这个名字说明了我们需要考虑所有这一"批"训练样本。
在高等线性代数中还有一种计算代价函数J最小值的数值解法,即正规方程(normal equations),后面还会介绍。但在数据量较大时,梯度下降法比正规方程法要更合适。
下面将讲述泛化的梯度下降算法,这将使梯度下降算法更强大。
2-8 What's next — 梯度下降扩展学习
有得算法可以直接解出θ0和θ1,而不必经过梯度下降这种需要多次迭代的算法。但其既有优点,也有缺点。
一个优点是,不需要设置学习速率α,因此可以更快地解决一些问题
上面问题中的特征(features)一般只有1个或2个,当有很多个时,我们可以使用线性代数的符号系统来标记。
比如用矩阵表示多维数据。