python秘技之函数式编程
函数用法和底层分析
- 前言
- 一、函数的基本概念
- 二、python函数分类
- 三、python函数定义与调用
- 1. 函数定义关键点:
- 1. 关键字:def
- 2. 参数列表
- 3. return 返回值
- 4. 先定义再调用
- 四、全局变量和局部变量
- 1、全局变量
- 2、局部变量
- 五、函数参数的传递(重点)
- 1. 传递可变对象的引用
- 2. 传递不可变对象的引用
- 六、深拷贝与浅拷贝(非常重点)
- 1. 浅拷贝:
- 2. 深拷贝:
- 3. 深浅拷贝总结
- 七、函数参数的几种类型
- 1. 位置参数
- 2. 默认值参数
- 3. 关键字参数
- 4. 不定长参数
- 5. 函数参数类型总结
- 八、递归函数
- 1. 什么是递归函数?
- 2. 递归特点:
- <1>自己调用自己
- <2>要有函数出口
- 3. 递归实例
- 1、 用递归实现1-100的累加和
- 2 、计算阶乘 n! = 1 * 2 * 3 * ... * n
- 九、匿名函数
- 1. 应用场景
- 2. lambda语法
- 3. 体验lambda
- 4. lambda参数问题
- 1. lambda之无参数
- 2. lambda之一个参数
- 3. lambda之默认参数
- 4. lambda之可变参数 : *args
- 5. lambda之可变参数 :**kwargs
- 5. lambda的应用
- 1. 带判断的.lambda
- 2. 列表数据按字典key的值排序
- 十、LEGB规则
- 十一、学习体会
- 加油!!!
- 你可以的!你总是这样相信着自己!
前言
函数是可重用的程序代码块。函数的作用,不仅可以实现代码的复用,更能实现代码的 一致性。一致性指的是,只要修改函数的代码,则所有调用该函数的地方都能得到体现。 在编写函数时,函数体中的代码写法和python基础没什么区别,只是对代码实现了封 装,并增加了函数调用、传递参数、返回计算结果等内容。
一、函数的基本概念
- 一个程序由一个个任务组成;函数就是代表一个任务或者一个功能。
- 函数是代码复用的通用机制
二、python函数分类
- 内置函数
我们前面使用的 str()、list()、len()等这些都是内置函数,我们可以拿来直接使用。 - 标准库函数
我们可以通过 import 语句导入库,然后使用其中定义的函数 。 - 第三方库函数
Python 社区也提供了很多高质量的库。下载安装这些库后,也是通过 import 语句导 入,然后可以使用这些第三方库的函数。 - 用户自定义函数
用户自己定义的函数,显然也是开发中适应用户自身需求定义的函数。今天我们学习的 就是如何自定义函数。
三、python函数定义与调用
def 函数名 ([参数列表]) :
'''文档字符串'''
函数体/若干语句
pass # 占位符 没想好写什么就写个pass,IDE不会报错误
1. 函数定义关键点:
1. 关键字:def
(1) Python 执行 def 时,会创建一个函数对象,并绑定到函数名变量上。
2. 参数列表
(1) 圆括号内是形式参数列表,有多个参数则使用逗号隔开
(2) 形式参数不需要声明类型,也不需要指定函数返回值类型
(3) 无参数,也必须保留空的圆括号
(4) 实参列表必须与形参列表一一对应
3. return 返回值
(1) 如果函数体中包含 return 语句,则结束函数执行并返回值;
(2) 如果函数体中不包含 return 语句,则返回 None 值。
4. 先定义再调用
(1) 内置函数对象会自动创建
(2) 标准库和第三方库函数,通过 import 导入模块时,会执行模块中的 def 语句
四、全局变量和局部变量
1、全局变量
- 在函数和类定义之外声明的变量。作用域为定义的模块,从定义位置开始直到模块 结束。
- 全局变量降低了函数的通用性和可读性。应尽量避免全局变量的使用。
- 全局变量一般做常量使用。
- 函数内要改变全局变量的值,使用 global 声明一下
2、局部变量
- 在函数体中(包含形式参数)声明的变量。
- 局部变量的引用比全局变量快,优先考虑使用。
- 如果局部变量和全局变量同名,则在函数内隐藏全局变量,只使用同名的局部变量
五、函数参数的传递(重点)
函数的参数传递本质上就是:从实参到形参的赋值操作。
Python 中“一切皆对象”, 所有的赋值操作都是“引用的赋值”。所以,Python 中参数的传递都是“引用传递”,不是“值传递”。
- 对“可变对象”进行“写操作”,直接作用于原对象本身。
- 对“不可变对象”进行“写操作”,会产生一个新的“对象空间”,并用新的值填充这块空间。(起到其他语言的“值传递”效果,但不是“值传递”)
可变对象有: 字典、列表、集合、自定义的对象等
不可变对象有: 数字、字符串、元组、function 等
1. 传递可变对象的引用
传递参数是可变对象(例如:列表、字典、自定义的其他可变对象等),实际传递的还是对象的引用,这算是个难点吧,其实也就是个细节问题,会经常在各种面试题里看到。
在函数体中不创建新的对象拷贝,而是可以直接修改所传递的对象。
举个栗子:
l = [10, 20]
def func(m):
print("m:", id(m)) # l 和 m 是同一个对象
m.append(30) # 由于 m 是可变对象,不创建对象拷贝,直接修改这个对象
func(l)
print("l:", id(l))
print(f'l : {l}')
结果:
m: 2149956976328
l: 2149956976328
l : [10, 20, 30]
定义一个列表,在函数里面修改它,会发现调用函数之后列表的内容也会修改。
2. 传递不可变对象的引用
传递参数是不可变对象(例如:int、float、字符串、元组、布尔值),实际传递的还是对象的引用。
在”赋值操作”时,由于不可变对象无法修改,系统会新创建一个对象。。
举个栗子:
a = 100
def func(n):
print(f"n's id: {id(n)}") # 传递进来的是 a 对象的地址
n += 200 # 由于 a 是不可变对象,因此创建新的对象 n
print(f"n's id: {id(n)}") # n已经变成了新的对象
print(f'n : {n}')
func(a)
print(f'a : {a}')
print(f'a : {id(a)}')
结果:
n's id: 1752725632
n's id: 2346697530128
n : 300
a : 100
a : 1752725632
结果很明显:
显然,通过 id 值我们可以看到 n 和 a 一开始是同一个对象。给 n 赋值后,n 是新的对象。
六、深拷贝与浅拷贝(非常重点)
关于深浅拷贝似乎永远是一个绕不过去的知识点,考试会考,面试会问,说不清楚就凉凉。今天把它好好整理一下,我尽量写得通俗点,我也怕自己会忘。
1. 浅拷贝:
不拷贝子对象的内容,只是拷贝子对象的引用。
直接上代码,借助python中copy模块测试一下浅拷贝:
import copy
def testCopy():
'''测试浅拷贝'''
a = [10, 20, [5, 6]]
b = copy.copy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("浅拷贝......")
print("a", a)
print("b", b)
testCopy()
结果:
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
浅拷贝......
a [10, 20, [5, 6, 7]]
b [10, 20, [5, 6, 7], 30]
画个示意图在这说明一下:

这个b其实就是拷贝了a的一个引用,列表b进行append的时候实际上是在他自己的基础上增加的也就是这个样子(见下图),但是他在对内部列表append的时候,实际上是修改了a所引用的内容,故打印结果的时候是上述那个样子的。
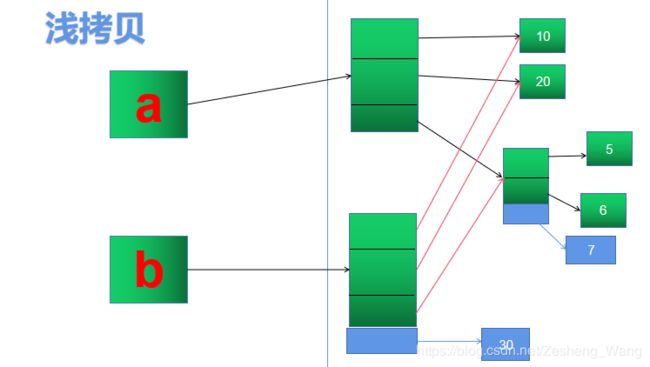
2. 深拷贝:
子对象的内存也全部拷贝一份,对子对象的修改不会影响源对象
import copy
def testDeepCopy():
'''测试深拷贝'''
a = [10, 20, [5, 6]]
b = copy.deepcopy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("深拷贝......")
print("a", a)
print("b", b)
testDeepCopy()
结果:
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
深拷贝......
a [10, 20, [5, 6]]
b [10, 20, [5, 6, 7], 30]
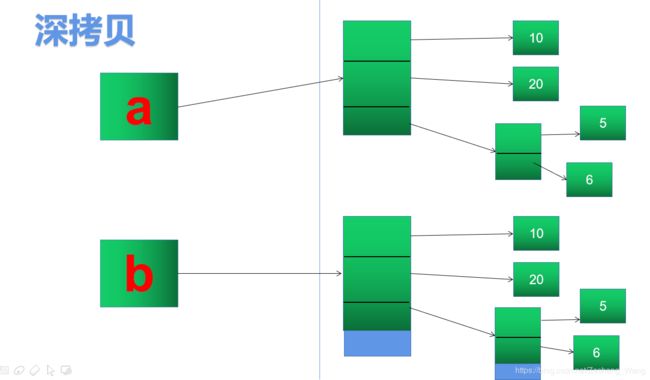
3. 深浅拷贝总结
深浅拷贝其实不是太难, 通过上面两个图可以看得出来。浅拷贝就是拿过来一部分,深拷贝就是把所有的全复制一份。有点像克隆人,浅拷贝就是指克隆自己。深拷贝就是把自己、老婆、父母全克隆一遍组成一个新的家庭。可以多写一些代码练习一下,这样印象会比较深刻。
七、函数参数的几种类型
1. 位置参数
函数调用时,实参默认按位置顺序传递,需要个数和形参匹配。按位置传递的参数,称为: “位置参数”。
def user_info(name, age, gender):
print(f'your\'s name is {name}, age is'
f' {age}, gender is {gender}')
user_info('tom', 20, 'male')
user_info('male', 20, 'tom') # 错误传递的后果
结果:
your's name is tom, age is 20, gender is male
your's name is male, age is 20, gender is tom
没什么好说的,别传错了就行。
2. 默认值参数
我们可以为某些参数设置默认值,这样这些参数在传递时就是可选的。称为“默认值参数”。 默认值参数放到位置参数后面。
def f1(a,b,c=10,d=20):
#默认值参数必须位于普通位置参数后面
print(a,b,c,d)
f1(8,9)
f1(8,9,19)
f1(8,9,19,29)
结果:
8 9 10 20
8 9 19 20
8 9 19 29
3. 关键字参数
user_info(age=20, gender='female', name='Wang')
结果:
user_info(age=20, gender='female', name='Wang')
4. 不定长参数
- *param(一个星号),将多个参数收集到一个“元组”对象中。
def user_infomation(*args):
print(args)
user_infomation('TOM')
user_infomation('TOM', 18) # 接受任一参数,返回一个元组
结果:
('TOM',)
('TOM', 18)
- **param(两个星号),将多个参数收集到一个“字典”对象中。
def user_infomation1(**kwargs):
print(kwargs)
user_infomation1(name='TOM', age=20) # 返回一个字典
结果:
{'name': 'TOM', 'age': 20}
5. 函数参数类型总结
总结就是参数的类型很多,实际使用过程中也会碰到各种各样的问题,包括它的顺序,关键字以及是否获取的是可变类型的参数等等。初学的时候会有点乱,多写多练,总会掌握的比较扎实的。
八、递归函数
1. 什么是递归函数?
如果一个函数在内部不调用其它的函数,而是自己本身的话,这个函数就是递归函数。
2. 递归特点:
<1>自己调用自己
<2>要有函数出口
3. 递归实例
1、 用递归实现1-100的累加和
(事实上用循环会更简单,仅作递归的了解)
# 1-100的和
def sum_numbers(num):
# 如果是1,直接返回1 --函数出口
if num == 1:
return 1
# 如果不是1,重复执行累加并返回结果
return num + sum_numbers(num - 1)
num = int(input('please input a num:'))
sum_result = sum_numbers(num)
print(sum_result)
结果显示:

事实上,关于递归,另外一个例子似乎更加典型
2 、计算阶乘 n! = 1 * 2 * 3 * … * n
# 使用递归来完成阶乘
def cal_num(num):
if num >= 1:
result = num * cal_num(num - 1)
else:
result = 1
return result
ret = cal_num(3)
print(f'递归计算阶乘结果:{ret}')
简单梳理一下:

写一些基础代码似乎并不会经常用到递归,不过学到了就记忆一下吧。
九、匿名函数
1. 应用场景
用lambda关键词能创建小型匿名函数。这种函数得名于省略了用def声明函数的标准步骤。(简化代码量,节约内存空间)
2. lambda语法
语法还是比较简单:
lambda 参数列表 : 表达式
lambda [arg1 [,arg2,.....argn]]:expression
3. 体验lambda
# 计算 a + b
# func
def add(a, b):
return a + b
print(add(1, 2))
# lambda
sum = lambda a, b: a + b
print(sum(1, 2))
4. lambda参数问题
1. lambda之无参数
# 无参数
fn1 = lambda: 100
print(fn1()) # 100
2. lambda之一个参数
# 一个参数
fn1 = lambda a: a
print(fn1('hello world')) # hello world
3. lambda之默认参数
# 默认参数
fn1 = lambda a, b, c=100: a + b + c
print(fn1(10, 20)) # 130
4. lambda之可变参数 : *args
# 可变参数:*args
fn1 = lambda *args: args
print(fn1(10, 20, 30)) # (10, 20, 30)
# 这里的可变参数传入到lambda之后,返回值为元组
5. lambda之可变参数 :**kwargs
# 可变参数:**kwargs
fn1 = lambda **kwargs: kwargs
print(fn1(name='python', age=20)) # {'name': 'python', 'age': 20}
# 这里的可变参数传入到lambda之后,返回值为字典
注:以lambda关键字创建的匿名函数关于参数问题其实和普通函数区别并不大,熟练使用即可。
5. lambda的应用
1. 带判断的.lambda
# 带判断的lambda,比较两个数字,选出较大的一个
fn1 = lambda a, b: a if a > b else b
print(fn1(1000, 500)) # 1000
2. 列表数据按字典key的值排序
# 列表数据按字典key的值排序
students = [
{'name': 'TOM', 'age': 20},
{'name': 'ROSE', 'age': 19},
{'name': 'JACK', 'age': 22}
]
# 按name值升序排列
students.sort(key=lambda x: x['name'])
print(students)
lambda的用处很大,必要的时候不要忘记使用。
十、LEGB规则
Python 在查找“名称”时,是按照 LEGB 规则查找的:
Local–>Enclosed–>Global–>Built in
- Local 指的就是函数或者类的方法内部
- Enclosed 指的是嵌套函数(一个函数包裹另一个函数,闭包)
- Global 指的是模块中的全局变量
- Built in 指的是 Python 为自己保留的特殊名称。
如果某个 name 映射在局部(local)命名空间中没有找到,接下来就会在闭包作用域 (enclosed)进行搜索,如果闭包作用域也没有找到,Python 就会到全局(global)命名空 间中进行查找,最后会在内建(built-in)命名空间搜索 (如果一个名称在所有命名空间 中都没有找到,就会产生一个 NameError)。
十一、学习体会
python的函数部分已经开始有一点点复杂了,需要记忆的知识明显增加,部分概念不好理解。先有一个印象,用到的时候能够回来找一找就可以了。还是要多练习,编程技术永远是通过代码量来练出来的。