K均值聚类算法(Kmeans)讲解及源码实现
K均值聚类算法(Kmeans)讲解及源码实现
算法核心
K均值聚类的核心目标是将给定的数据集划分成K个簇,并给出每个数据对应的簇中心点。算法的具体步骤描述如下。
- 数据预处理,如归一化、离群点处理等。
- 随机选取K个簇中心,记为 μ 1 ( 0 ) , μ 2 ( 0 ) , . . . , μ k ( 0 ) \mu_1^{(0)},\mu_2^{(0)},...,\mu_k^{(0)} μ1(0),μ2(0),...,μk(0)。
- 定义代价函数: J ( c , μ ) = m i n μ m i n c Σ i = 1 M ∣ ∣ x i − μ c i ∣ ∣ 2 J(c,\mu)=min_{\mu}min_{c}\Sigma_{i=1}^M||x_i-\mu_{c_i}||^2 J(c,μ)=minμmincΣi=1M∣∣xi−μci∣∣2。
- 令 t = 0 , 1 , 2 , . . . t=0,1,2,... t=0,1,2,...为迭代步数,重复下面过程直到 J J J收敛
- 对于每一个样本 x i x_i xi,将其分配到距离最近的簇 c i ( t ) ← a r g m i n k ∣ ∣ x i − μ k ( t ) ∣ ∣ 2 c_i^{(t)}\leftarrow argmin_k ||x_i-\mu_k^{(t)}||^2 ci(t)←argmink∣∣xi−μk(t)∣∣2
- 对于每一个类簇 k k k,重新计算该类簇的中心 μ k ( t + 1 ) ← a r g m i n μ Σ i : x i ( t ) = k ∣ ∣ x i − μ ∣ ∣ 2 \mu_k^{(t+1)}\leftarrow argmin_{\mu}\Sigma_{i:x_i^{(t)}=k}||x_i-\mu||^2 μk(t+1)←argminμΣi:xi(t)=k∣∣xi−μ∣∣2
K K K均值算法在迭代时,假设当前损失函数 J J J没有达到最小值,那么首先固定簇中心 { μ k } \{\mu_k\} {μk},调整每个样例 x i x_i xi所属的类别 c i c_i ci来让 J J J函数减少;
然后固定 { c i } \{c_i\} {ci},调整簇中心 { μ k } \{\mu_k\} {μk}使 J J J减少。
这两个过程交替循环, J J J单调递减:当 J J J递减到最小值时, μ k {\mu_k} μk和 c i {c_i} ci也同时收敛。
源码实现(含可视化)
导入包
import numpy as np
import matplotlib.pyplot as plt
数据预处理
设置地图尺寸
# map 100*100
high = 100
width = 100
创建随机数据
每一条数据的格式为 ( x 坐 标 , y 坐 标 , 类 别 ) (x坐标,y坐标,类别) (x坐标,y坐标,类别),列表初始化为0,类别序数间隔1递增
data = np.random.rand(100, 2)
data = data * [high, width]
data = np.hstack((data, np.zeros([100, 1])))
定义簇数目
# count of classes
classes = 5
定义距离函数,此处我们使用欧氏距离
def distance(point1, center):
return np.sqrt((point1[0] - center[0]) ** 2 + (point1[1] - center[1]) ** 2)
定义从类别到颜色的映射函数,即
类 别 ∗ 255 / 总 类 别 数 类别*255/总类别数 类别∗255/总类别数
def color(i):
global classes
return i * 255. / classes
定义主函数
先将plt设置为连续作图模式
然后随机挑选簇中心点,并加入到中心点数组 c e n t e r s _ d a t a centers\_data centers_data中
if __name__ == '__main__':
plt.ion()
# select center randomly
centers = np.random.randint(0, 100, [classes])
centers_data = []
for i in range(classes):
data[i][2] = i
centers_data.append(data[i])
先画散点图,且暂停0.5秒以显示迭代中的聚类情况。
while True:
colors = [color(x) for x in data[:, 2]]
plt.scatter(data[:, 0], data[:, 1], c=colors)
plt.pause(0.5)
先后依次迭代更新每个点所对应的簇,和每个簇的中心点。
# caculate nearest center
for i in range(100):
distances = np.array([distance(data[i], center_data) for center_data in centers_data])
i_class = np.argmin(distances)
data[i][2] = i_class
# caculate new center
new_centers_data = np.zeros([classes, 2])
new_centers_count = np.zeros([classes])
for j in range(5):
for i in range(100):
if data[i][2] == j:
new_centers_count[j] += 1
new_centers_data[j] += data[i][0:2]
计算五个簇的中心点位置先后变化的最大值,其值小于1e-4(可自定义)时,跳出循环,停止迭代。
new_centers_data /= np.array([new_centers_count]).T
dist = np.max([distance(new_centers_data[i], centers_data[i]) for i in range(classes)])
print('max distance ', dist)
if dist < 1e-4:
break
在每次迭代的最后更新中心点数据
centers_data = new_centers_data
最后关闭连续作图模式,并展示最后的图画,打印结束。
plt.ioff()
plt.show()
print('kmeans completed.')
效果
命令行
max distance 28.36595846126929
max distance 7.136259328045152
max distance 3.533885366585787
max distance 2.153654229308223
max distance 0.0
kmeans completed.
可视化过程
第1次迭代

第2次迭代

第3次迭代
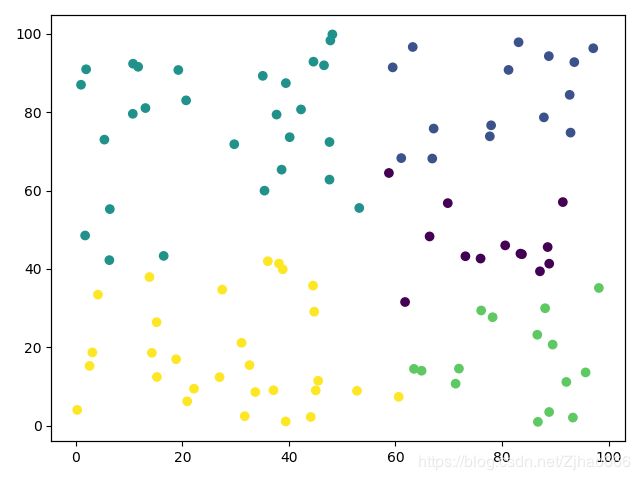
第4次迭代
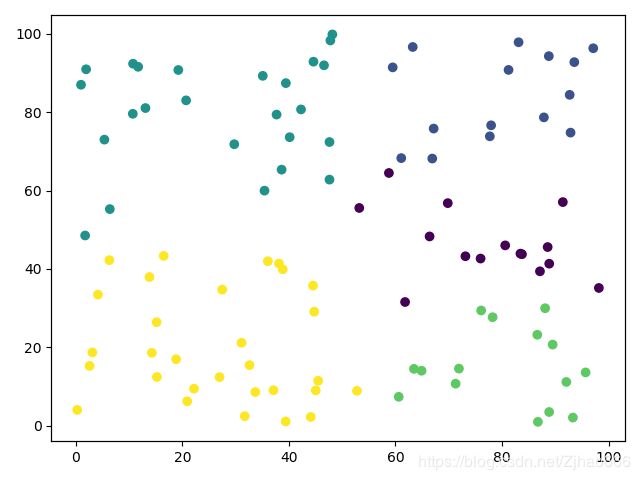
全部代码
import numpy as np
import matplotlib.pyplot as plt
# map 100*100
high = 100
width = 100
# create random data
data = np.random.rand(100, 2)
data = data * [high, width]
data = np.hstack((data, np.zeros([100, 1])))
# count of classes
classes = 5
def distance(point1, center):
return np.sqrt((point1[0] - center[0]) ** 2 + (point1[1] - center[1]) ** 2)
def color(i):
global classes
return i * 255. / classes
if __name__ == '__main__':
plt.ion()
# select center randomly
centers = np.random.randint(0, 100, [classes])
centers_data = []
for i in range(classes):
data[i][2] = i
centers_data.append(data[i])
while True:
colors = [color(x) for x in data[:, 2]]
plt.scatter(data[:, 0], data[:, 1], c=colors)
plt.pause(0.5)
# caculate nearest center
for i in range(100):
distances = np.array([distance(data[i], center_data) for center_data in centers_data])
i_class = np.argmin(distances)
data[i][2] = i_class
# caculate new center
new_centers_data = np.zeros([classes, 2])
new_centers_count = np.zeros([classes])
for j in range(5):
for i in range(100):
if data[i][2] == j:
new_centers_count[j] += 1
new_centers_data[j] += data[i][0:2]
new_centers_data /= np.array([new_centers_count]).T
dist = np.max([distance(new_centers_data[i], centers_data[i]) for i in range(classes)])
print('max distance ', dist)
if dist < 1e-4:
break
centers_data = new_centers_data
plt.ioff()
plt.show()
print('kmeans completed.')