基于JSoup的网络爬虫爬取小说内容
网上的一些小说是可以直接看的,不需要登陆与购买,现在我们需要做的就是把这些小说的内容下载到本地。
首先,准备工作:
下载JSoup的jar包,并且创建一个新的工程。

接下来在浏览器上找到需要下载的小说:
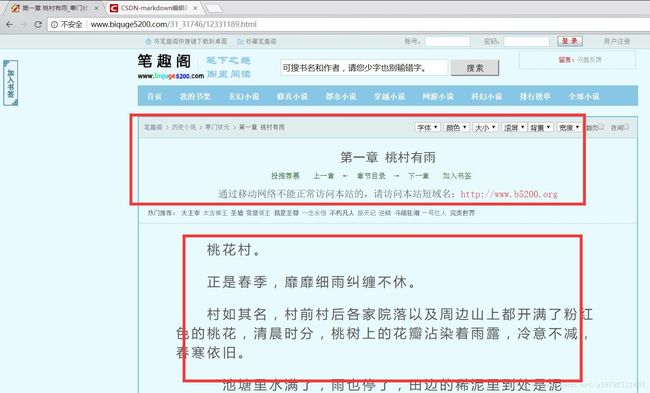
这是有正文的界面,然后复制链接,作为爬取的初始链接
代码如下:
/**
* 获取链接的document对象
* @param url
* @return document
*/
public static Document getDoc(String url)
{
boolean flag = false;
Document document = null;
do{
try {
document = Jsoup
.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.64 Safari/537.31")
.timeout(5000)
.get();
flag = false;
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
flag = true;
}
}while(flag);
return document;
}在主函数中进行调用:
String url = "http://www.biquge5200.com/31_31746/12331189.html";
Document document = getDoc(url);然后进行获取此链接的document对象,并使用toString方法输出:

在上面的图片中可以看到,title就是本章的题目。
然后找到本章的正文:

在id等于content的div中是正文,所以在获取到正文后,进行提取:
String title = document.title();
String text = document.select("#content").text();
System.out.println(title);
System.out.println(text);
//System.out.println(document.toString());效果如下:
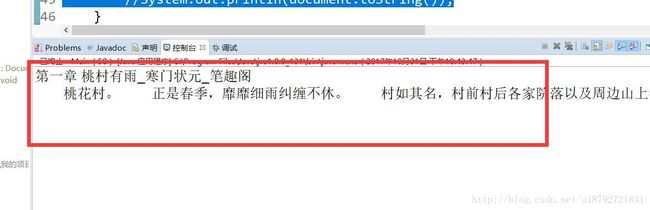
发现格式有问题,这个不用管,在最后存储到文件中会进行正确的转化,而且手机或者一些文本阅读软件有自动排版功能,所以格式不用考虑。
接下来,我们需要找到下一章的链接:
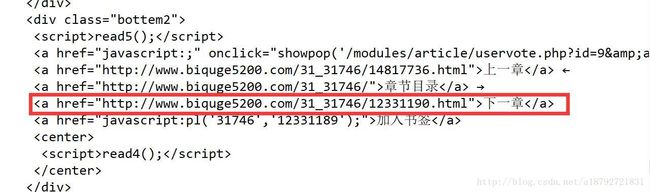
发现是class为bottem2的div块:
首先我们得到这个div块:
主函数添加:
Elements nextdiv = document.select(".bottem2");
System.out.println(nextdiv.toString());效果如下:
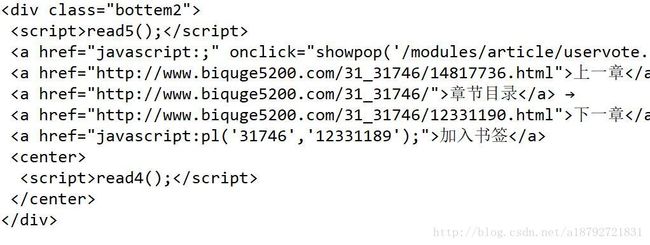
接下来我们需要获取下一章的地址:
发现下一章和右箭头之间的就是链接,不能先获取所有的a标签然后去第4个,容易出错。
首先,使用String的split方法截取下一章之前的内容:
主函数:
String nextdivstr = nextdiv.toString();
String[] nexturl = nextdivstr.split("下一章");调试发现:
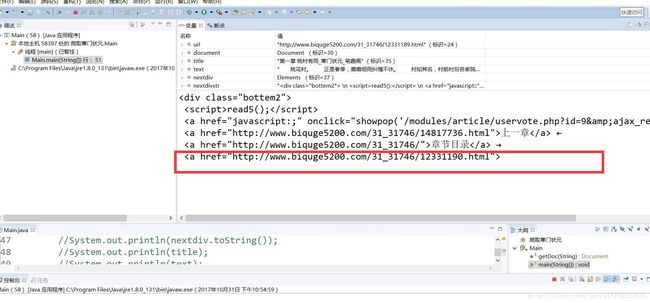
整个字符串在下一章被分为两段,我们只需要之前的那一段,所以只取第一个元素:
然后右箭头的unicode编码为2192:
nextdivstr = nexturl[0];
nexturl = nextdivstr.split("\u2192");调试后发现:
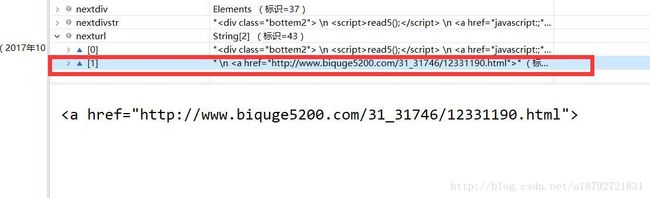
在第二个元素是我们需要的:
next = nexturl[1];
System.out.println(next);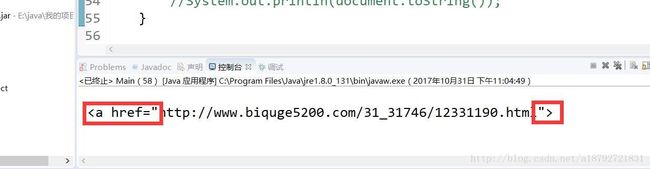
然后发现红框中的内容不需要,所以我们需要去掉:
next = next.substring(12,next.length() - 2);效果如下:
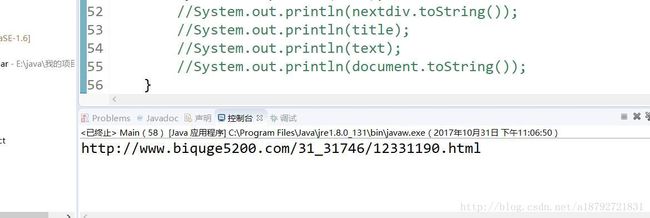
接下来就是使用循环进行爬取了:
我们查看目录发现这个小说共有1739章:
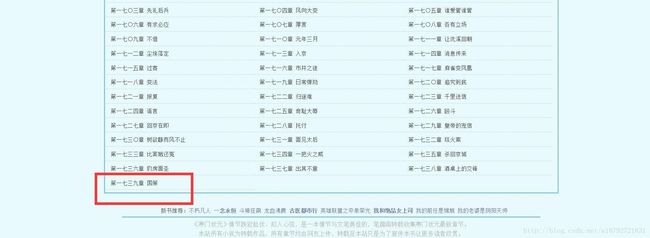
所以我们把数量限定在1739章上:
public static void main(String[] args) {
String url = "http://www.biquge5200.com/31_31746/12331189.html";
int i = 0;
while (i < 1739) {
Document document = getDoc(url);
String title = document.title();
String text = document.select("#content").text();
Elements nextdiv = document.select(".bottem2");
String next = nextdiv.toString();
String[] nexturl = next.split("下一章");
next = nexturl[0];
nexturl = next.split("\u2192");
next = nexturl[1];
next = next.substring(12, next.length() - 2);
i++;
}
}这样就获取到了所有的章节,然后就是保存在本地了:
首先在某个路径下创建一个txt文件:
File file = new File("E:\\寒门状元.txt");然后创建一个文件写入对象:
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter(file);
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}然后每获取到一章,就写入一章:
try {
fileWriter.write(title);
fileWriter.write(text);
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}最后,每一次写入后刷新缓冲:
try {
fileWriter.flush();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}当所有的章节全部获取完成后,关闭文件写入对象:
try {
fileWriter.close();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}这样就算完成了,但是我们不知道进度,所以,添加输出提示:
System.out.println("第"+(i+1)+"完成,共1739章");所有的到这里就完了:
测试一下:
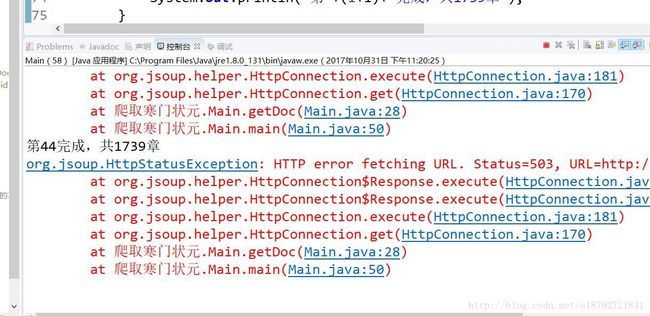
发现因为爬取太快,所以出现503错误(我自己猜测),但是不影响程序的运行:
还能继续爬取,如果觉得错误信息烦人,就把获取链接的错误提示注释,就没有了。

总结一下,网络爬虫的难点主要有两个:
1.获得链接的内容。
在这里容易出错的地方是获取链接容易出现403,404,502,503等一些错误。
这种错误出现了,网上随便一搜,解决方法还是挺多的。
2.就是如何获得下一个链接。
这是让自己的爬虫动起来的关键所在,有些页面可以利用JQuery的选择器表达式直接获取,比如attr方法获取到a标签的href这个属性,等等,但是容易出错。
所以这个方法看起来很笨,但是是一个通用的方法。理解上比较容易,对于没有前端知识的人比较适用。把前端知识转化为从字符串中提取字符串的问题。