pytorch 从头开始faster-rcnn(四):rpn
具体参数可以查看:https://www.cnblogs.com/wangyong/p/8513563.html
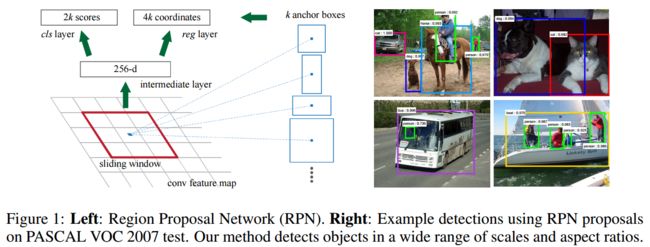
RPN流程:
1.每一张图片生成固定数量的锚节点,锚节点个数是最后一次特征图大小,比如说最后一层特征大小为(37,50),所以有37*50个锚节点.锚节点之间的步长为16像素点,这是因为vgg16有4次maxpool,所有图像缩小了16倍,所以步长为16像素。每一个锚节点又生成9个区域图,所以生成的锚节点区域图就有9*37*50个.
2.如图1左,通过卷积特征生成2*锚节点个数(通道数)scores和4**锚节点个数(通道数)坐标;这里坐标是相对对应锚节点的偏差量。
这个预测值将与真值标签计算损失;这里真值标签的制作为真值标签与锚节点重叠度最大的作为真值,计算偏差量,与预测值获得的偏差量进行计算。
由于锚节点框数量太多,所以是又进行筛选进行计算的:
① 去除掉超过1000*600这原图的边界的anchor box
② 如果anchor box与ground truth的IoU值最大,标记为正样本,label=1
③ 如果anchor box与ground truth的IoU>0.7,标记为正样本,label=1
④ 如果anchor box与ground truth的IoU<0.3,标记为负样本,label=0
剩下的既不是正样本也不是负样本,不用于最终训练,label=-1
用于计算二分类的交叉熵损失的个数为256个;其中正负样本的比例为1:1。如果正样本不足128,则多用一些负样本以满足有256个Proposal可以用于训练,反之亦然;如果都多就用随机筛选;
用于计算回归损失的为① 去除掉超过1000*600这原图的边界的anchor box 与其iou最大的真值标签,计算偏差后进行回归;
3.在将预测的值加上锚节点值使得检测框回复到原图坐标值B_loc,这样可以使得预测值回到原图对应检测框;
4.这些预测值B_loc先进行删除预测超出阈值大小的检测框;
再取预测score最大的6000个检测框;
最后通过nms获得最终数量的检测框;
最终获得的检测框将用于ROI层真值标签的生成,以及进行筛选3:1的正负样本放入ROI层进行训练;
def forward(self, x, img_size, scale=1.):
n, _, hh, ww = x.shape
# print self.anchor_base
# print self.anchor_base.shape
# 所有特征图上9种锚点的坐标
anchor = _enumerate_shifted_anchor(
np.array(self.anchor_base),
self.feat_stride, hh, ww)
# print anchor
# print anchor.shape
n_anchor = anchor.shape[0] // (hh * ww)
h = F.relu(self.conv1(x))
rpn_locs = self.loc(h)
# UNNOTE: check whether need contiguous
# A: Yes
rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4)
rpn_scores = self.score(h)
rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous()
rpn_softmax_scores = F.softmax(
rpn_scores.view(n, hh, ww, n_anchor, 2), dim=4)
rpn_fg_scores = rpn_softmax_scores[:, :, :, :, 1].contiguous()
rpn_fg_scores = rpn_fg_scores.view(n, -1)
rpn_scores = rpn_scores.view(n, -1, 2)
# 经过nms(极大值抑制)获得的roi
rois = list()
roi_indices = list()
for i in range(n):
roi = self.proposal_layer(
rpn_locs[i].cpu().data.numpy(),
rpn_fg_scores[i].cpu().data.numpy(),
anchor, img_size,
scale=scale)
batch_index = i * np.ones((len(roi),), dtype=np.int32)
rois.append(roi)
roi_indices.append(batch_index)
# 将list转为numpy格式,这个作者有毒,一直用奇葩的方式转格式
rois = np.concatenate(rois, axis=0)
roi_indices = np.concatenate(roi_indices, axis=0)
return rpn_locs, rpn_scores, rois, roi_indices, anchor
def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32]):
py = base_size / 2.
px = base_size / 2.
anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4),
dtype=np.float32)
for i in six.moves.range(len(ratios)):
for j in six.moves.range(len(anchor_scales)):
h = base_size * anchor_scales[j] * np.sqrt(ratios[i])
w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i])
index = i * len(anchor_scales) + j
anchor_base[index, 0] = py - h / 2.
anchor_base[index, 1] = px - w / 2.
anchor_base[index, 2] = py + h / 2.
anchor_base[index, 3] = px + w / 2.
return anchor_base
生成了9个锚点坐标。
def _enumerate_shifted_anchor_torch(anchor_base, feat_stride, height, width):
# 将所有的锚点坐标存储并且将数组转为torch.cudatensor
# Enumerate all shifted anchors:
#
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
# return (K*A, 4)
# !TODO: add support for torch.CudaTensor
# xp = cuda.get_array_module(anchor_base)
import torch as t
shift_y = t.arange(0, height * feat_stride, feat_stride)
shift_x = t.arange(0, width * feat_stride, feat_stride)
shift_x, shift_y = xp.meshgrid(shift_x, shift_y)
shift = xp.stack((shift_y.ravel(), shift_x.ravel(),
shift_y.ravel(), shift_x.ravel()), axis=1)
A = anchor_base.shape[0]
K = shift.shape[0]
anchor = anchor_base.reshape((1, A, 4)) + \
shift.reshape((1, K, 4)).transpose((1, 0, 2))
anchor = anchor.reshape((K * A, 4)).astype(np.float32)
return anchor生成所有特征区域图每个坐标的9个锚节点窗口。