分布式任务调度-Elastic-Job
Java 定时任务框架对比
quartz 和 Elastic-Job
1.quartz:
quartz 的常见集群方案如下,通过在数据库中配置定时器信息, 以数据库悲观锁的方式达到同一个任务始终只有一个节点在运行。
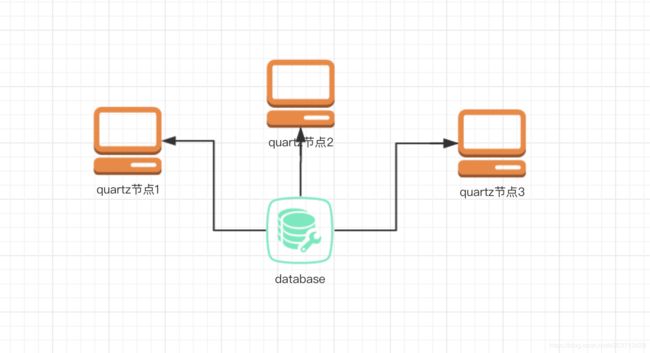
优点:
- 保证节点高可用 (HA), 如果某一个节点挂了, 其他节点可以顶上;
缺点:
- 同一个任务只能有一个节点运行,其他节点将不执行任务,性能低,资源浪费;
- 当碰到大量短任务时,各个节点频繁的竞争数据库锁,节点越多这种情况越严重。性能会很低下;
- quartz 的分布式仅解决了集群高可用的问题,并没有解决任务分片的问题,不能实现水平扩展;
问题:
- 问题一:调用API的的方式操作任务,不人性化;
- 问题二:需要持久化业务QuartzJobBean到底层数据表中,系统侵入性相当严重。
- 问题三:调度逻辑和QuartzJobBean耦合在同一个项目中,这将导致一个问题,在调度任务数量逐渐增多,同时调度任务逻辑逐渐加重的情况加,此时调度系统的性能将大大受限于业务;
- 问题四:quartz底层以“抢占式”获取DB锁并由抢占成功节点负责运行任务,会导致节点负载悬殊非常大。
2.Elastic-Job:
elastic-job 是由当当网基于quartz 二次开发之后的分布式调度解决方案 , 由两个相对独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成 。
Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务。
Elastic-Job-Cloud使用Mesos + Docker(TBD)的解决方案,额外提供资源治理、应用分发以及进程隔离等服务 亮点:
- 基于quartz 定时任务框架为基础的,因此具备quartz的大部分功能
- 使用zookeeper做协调,调度中心,更加轻量级
- 支持任务的分片(所谓分片就是分机器)
- 支持弹性扩容 , 可以水平扩展 , 当任务再次运行时,会检查当前的服务器数量,重新分片,分片结束之后才会继续执行任务
- 失效转移,容错处理,当一台调度服务器宕机或者跟zookeeper断开连接之后,会立即停止作业,然后再去寻找其他空闲的调度服务器,来运行剩余的任务
- 提供运维界面,可以管理作业和注册中心。
分片的好处:
Example:你们公司刚成立,只有几十万用户,需要做一个用户订单每日统计分析,你每天凌晨触发任务,只用一个小时就跑完了。过了一年你们的用户量暴增,3000万。你们的分析任务更加复杂了,这个时候跑批任务需要6个小时,等产品经理上班来要结果的时候你发现还没跑完,他被老板骂了一顿,然后回来怼你。
你虽然受气了心理很难受,但是确实是你的锅。于是在想你有这么多机器为啥非得在一台上跑呢,咋样才能将任务分解上多台机器上独立执行。
不足:
- 异构语言不支持
- 目前采用的无中心设计,难于支持多语言,后面需要考虑调度中心的可行性。
- 监控体系有待提高,目前只能通过注册中心做简单的存活和数据积压监控,未来需要做的监控部分有:
增加可监控维度,如作业运行时间等。
基于JMX的内部状态监控。
基于历史的全量数据监控,将所有监控数据通过flume等形式发到外部监控中心,提供实时分析功能。 - 不能支持多种注册中心。
- 需要增加任务工作流,如任务依赖,初始化任务,清理任务等。
- 失效转移功能的实时性有待提升。
- 缺少更多作业类型支持,如文件,MQ等类型作业的支持。
非官方总结:
quartz:
- 高可用方案依赖于数据库;
- 任务是在quartz集群上触发调用,http接口方式;
- 高频任务会对数据库有一定的压力,另外抢占式获取数据库独占锁的方式会导致负载不均;
- 需要在quartz任务管理平台手动配置任务触发脚本,还需要写对应的接口,个人感觉很麻烦。
Elastic-Job:
- 轻量级,非独立部署,以jar包形式集成于个人服务之中;
- 需要依赖zk,作为节点注册中心;
- 可以配置任务分片,即指定分片策略将某个任务的某一部分运行与某一台机器,提高机器利用效率;
- 支持水平扩容;
- 失效补偿机制,如果任务执行中途宕机,可以在有效节点上补偿该任务,补偿机制默认关闭,需手动开启;
- 目前只支持Java语言,最后提交日期是2017年。
Elastic-Job-Lite使用
1 分布式调度
Elastic-Job-Lite并无作业调度中心节点,而是基于部署作业框架的程序在到达相应时间点时各自触发调度。
注册中心仅用于作业注册和监控信息存储。而主作业节点仅用于处理分片和清理等功能。
2 作业高可用
Elastic-Job-Lite提供最安全的方式执行作业。将分片总数设置为1,并使用多于1台的服务器执行作业,作业将会以1主n从的方式执行。
一旦执行作业的服务器崩溃,等待执行的服务器将会在下次作业启动时替补执行。开启失效转移功能效果更好,可以保证在本次作业执行时崩溃,备机立即启动替补执行。
3 最大限度利用资源
Elastic-Job-Lite也提供最灵活的方式,最大限度的提高执行作业的吞吐量。将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项。
例如:3台服务器,分成10片,则分片项分配结果为服务器A=0,1,2;服务器B=3,4,5;服务器C=6,7,8,9。 如果服务器C崩溃,则分片项分配结果为服务器A=0,1,2,3,4;服务器B=5,6,7,8,9。在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量。注册中心仅用于作业注册和监控信息存储。而主作业节点仅用于处理分片和清理等功能。
4.整体架构图
图片来自于官网:
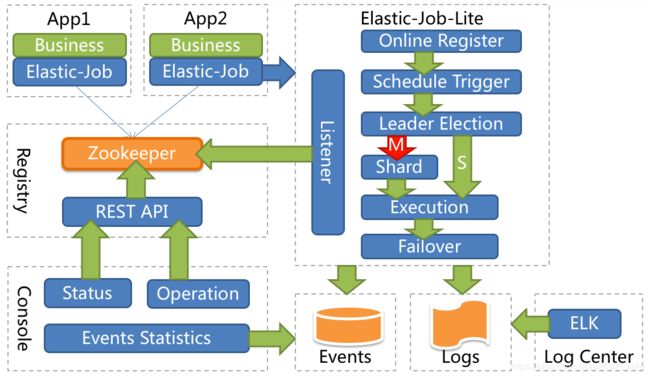
5.实现原理
弹性分布式实现:
- 第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务。
- 某作业服务器上线时会自动将服务器信息注册到注册中心,下线时会自动更新服务器状态。
- 主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
- 定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
- 通过上一项说明可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
- 每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
- 实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
注册中心数据结构
注册中心在定义的命名空间下,创建作业名称节点,用于区分不同作业,所以作业一旦创建则不能修改作业名称,如果修改名称将视为新的作业。作业名称节点下又包含4个数据子节点,分别是config, instances, sharding, servers和leader。
-
config节点
作业配置信息,以JSON格式存储 -
instances节点
作业运行实例信息,子节点是当前作业运行实例的主键。作业运行实例主键由作业运行服务器的IP地址和PID构成。作业运行实例主键均为临时节点,当作业实例上线时注册,下线时自动清理。注册中心监控这些节点的变化来协调分布式作业的分片以及高可用。 可在作业运行实例节点写入TRIGGER表示该实例立即执行一次。 -
sharding节点
作业分片信息,子节点是分片项序号,从零开始,至分片总数减一。分片项序号的子节点存储详细信息。每个分片项下的子节点用于控制和记录分片运行状态。节点详细信息说明查看文档。 -
servers节点
作业服务器信息,子节点是作业服务器的IP地址。可在IP地址节点写入DISABLED表示该服务器禁用。 在新的cloud native架构下,servers节点大幅弱化,仅包含控制服务器是否可以禁用这一功能。为了更加纯粹的实现job核心,servers功能未来可能删除,控制服务器是否禁用的能力应该下放至自动化部署系统。 -
leader节点
作业服务器主节点信息,分为election,sharding和failover三个子节点。分别用于主节点选举,分片和失效转移处理。leader节点是内部使用的节点,如果对作业框架原理不感兴趣,可不关注此节点。子节点可查看文档。
6. 监控平台
在github地址https://github.com/elasticjob/elastic-job-lite,下载源码。
clone 然后编译:
mvn clean install -Dmaven.test.skip=true
解压该压缩包,进入bin目录下启动控制台:
浏览器查看:
提供两种账户,管理员及访客,管理员拥有全部操作权限,访客仅拥有察看权限。默认管理员用户名和密码是root/root,访客用户名和密码是guest/guest,可通过conf\auth.properties修改管理员及访客用户名及密码。
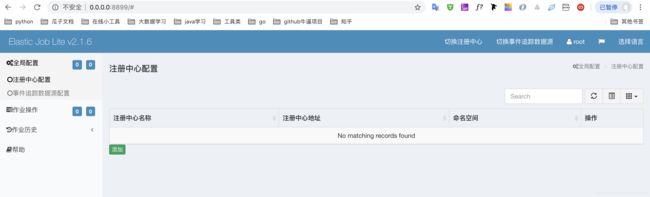
elastic-job的运维平台设计理念
- 运维平台和elastic-job-lite并无直接关系,是通过读取作业注册中心数据展现作业状态,或更新注册中心数据修改全局配置。
- 控制台只能控制作业本身是否运行,但不能控制作业进程的启动,因为控制台和作业本身服务器是完全分离的,控制台并不能控制作业服务器。
所以运维平台配置zookeeper的信息才是关键,只有连通了zookeeper才能对定时任务进行操作,操作步骤:
左边菜单点击【全局配置】选中【注册中心配置】,然后出现一个已配置列表,在列表的分页显示下方有个【添加】按钮进行添加:
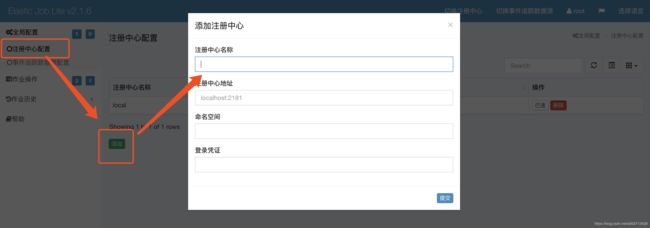
添加字段说明:
注册中心名称:自定义,用于当前列表显示,便于区分
注册中心地址: zookeeper的地址,需要连接哪个就填写哪个 【IP:端口】
命名空间: 任务创建ZookeeperRegistryCenter的时候填写namespace,要对应上,才能看到对应下的任务
登录凭证: 可不填,默认zookeeper不需要填写,除非设置了zookeeper相关信息
作业操作

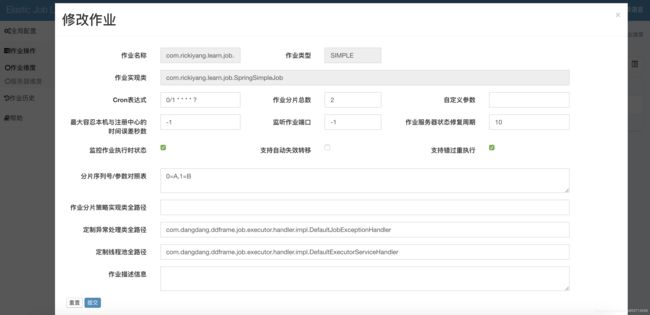
修改操作:
作业维度:
查看当前挂在zookeeper的命名空间下的所有任务,提供删除,编辑,触发,失效等一系列功能
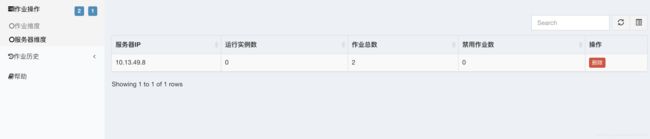
服务器维度:
查看当前连着zookeeper的服务器,提供删除,失效,终止等一些列功能。
7. 结合Springboot使用Elastic-job
见github:https://github.com/rickiyang/springboot-learn/tree/master/elastic-job
8. 分片策略说明
AverageAllocationJobShardingStrategy
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.AverageAllocationJobShardingStrategy
策略说明:
基于平均分配算法的分片策略,也是默认的分片策略。
如果分片不能整除,则不能整除的多余分片将依次追加到序号小的服务器。如:
如果有3台服务器,分成9片,则每台服务器分到的分片是:1=[0,1,2], 2=[3,4,5], 3=[6,7,8]
如果有3台服务器,分成8片,则每台服务器分到的分片是:1=[0,1,6], 2=[2,3,7], 3=[4,5]
如果有3台服务器,分成10片,则每台服务器分到的分片是:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]
9.事件追踪
Elastic-Job提供了事件追踪功能,可通过事件订阅的方式处理调度过程的重要事件,用于查询、统计和监控。Elastic-Job目前提供了基于关系型数据库两种事件订阅方式记录事件。
Elastic-Job-Lite在配置中提供了JobEventConfiguration,目前支持数据库方式配置。
事件追踪的event_trace_rdb_url属性对应库自动创建JOB_EXECUTION_LOG和JOB_STATUS_TRACE_LOG两张表以及若干索引。
JOB_EXECUTION_LOG字段含义:
| 字段名称 | 字段类型 | 是否必填 | 描述 |
|---|---|---|---|
| id | VARCHAR(40) | 是 | 主键 |
| job_name | VARCHAR(100) | 是 | 作业名称 |
| task_id | VARCHAR(1000) | 是 | 任务名称,每次作业运行生成新任务 |
| hostname | VARCHAR(255) | 是 | 主机名称 |
| ip | VARCHAR(50) | 是 | 主机IP |
| sharding_item | INT | 是 | 分片项 |
| execution_source | VARCHAR(20) | 是 | 作业执行来源。可选值为NORMAL_TRIGGER, MISFIRE, FAILOVER |
| failure_cause | VARCHAR(2000) | 否 | 执行失败原因 |
| is_success | BIT | 是 | 是否执行成功 |
| start_time | TIMESTAMP | 是 | 作业开始执行时间 |
| complete_time | TIMESTAMP | 否 | 作业结束执行时间 |
JOB_EXECUTION_LOG记录每次作业的执行历史。分为两个步骤:
- 作业开始执行时向数据库插入数据,除failure_cause和complete_time外的其他字段均不为空。
- 作业完成执行时向数据库更新数据,更新is_success, complete_time和failure_cause(如果作业执行失败)。
JOB_STATUS_TRACE_LOG字段含义:
| 字段名称 | 字段类型 | 是否必填 | 描述 |
|---|---|---|---|
| id | VARCHAR(40) | 是 | 主键 |
| job_name | VARCHAR(100) | 是 | 作业名称 |
| original_task_id | VARCHAR(1000) | 是 | 原任务名称 |
| task_id | VARCHAR(1000) | 是 | 任务名称 |
| slave_id | VARCHAR(1000) | 是 | 执行作业服务器的名称,Lite版本为服务器的IP地址,Cloud版本为Mesos执行机主键 |
| source | VARCHAR(50) | 是 | 任务执行源,可选值为CLOUD_SCHEDULER, CLOUD_EXECUTOR, LITE_EXECUTOR |
| execution_type | VARCHAR(20) | 是 | 任务执行类型,可选值为NORMAL_TRIGGER, MISFIRE, FAILOVER |
| sharding_item | VARCHAR(255) | 是 | 分片项集合,多个分片项以逗号分隔 |
| state | VARCHAR(20) | 是 | 任务执行状态,可选值为TASK_STAGING, TASK_RUNNING, TASK_FINISHED, TASK_KILLED, TASK_LOST, TASK_FAILED, TASK_ERROR |
| message | VARCHAR(2000) | 是 | 相关信息 |
| creation_time | TIMESTAMP | 是 | 记录创建时间 |
JOB_STATUS_TRACE_LOG记录作业状态变更痕迹表。可通过每次作业运行的task_id查询作业状态变化的生命周期和运行轨迹。