一份详细的Kylin执行样例——基于kylin2.5.0
在《Kylin2.5.0安装部署及样例sample.sh》一文中,我们搭建了kylin2.5.0版本的运行环境,并且简单演示了一下官方的Sample Cube的示例,这样从宏观上对kylin的运行流程有了一个整体的认识。那么,这篇文章我们将继续从创建一个完整的cube到执行sql语句,对其中的每一步都做一个详细的描述。本文的业务背景来自于蒋守壮老师的《基于Apache Kylin构建大数据分析平台》一书。
在进入正题之前,先简单介绍一下本例的业务背景:创建一个网站流量的Cube,用于统计常用的PV(Page View)和UV(Unique Visitor)等指标,包含一个事实表(web_access_fact_tab1),字段为访问日期、cookieid、regionid、cityid、siteid、OS、pv(2018-12-01|GB56THSJ1J7V2MDAB1|G03|G0301|Mac OS|2)【有需要的同学可以下方评论,拿事实表的数据】;两个维度表region_tb1,字段为regionid、regionname(G01|北京);city_tb1,字段为regionid、cityid、cityname(G01|G0101|朝阳区)。三张表组成一个星型模型,即一张事实表和多张维度表,通过主外键关联起来。顺便加一句,很多时候我们可能会涉及到多张事实表,而kylin又支持星型模型,因此需要现在Hive中进行预处理,来产生一张比较大的事实表。
###Start Your Shows ###
首先我们需要了解,kylin中多为分析Cube的建立主要包括以下步骤:
- 对Hive中事实表,以及多张维度表的处理;
- 在Kylin中建立新的Project;
- Kylin中同步数据源(Load DataSource);
- Kylin中建立数据模型;
- 建立Cube;
- Build Cube;
- 查询Cube。
一、在Hive中处理事实表、维度表
1、在Hive创建Database kylin_flat_db,创建成功后再创建我们需要的事实表结构,代码如下

hive> create table kylin_flat_db.web_access_fact_tb1
(
day date, cookid string, regionid string, cityid string,
siteid string, os string, pv bigint
) row format delimited
fields terminated by '|'
stored as textfile;![]()
2、使用 load data local inpath语句将我们提前准备好的kylin事实表数据源导入到实时表web_access_fact_tb1;
hive> load data local inpath '/usr/kylin/fact_data.txt'
into table web_access_fact_tb1;
3、创建region维度表和city维度表,建表语句见如下代码。
hive> create table kylin_flat_db.region_tb1
> ( regionid string, regionname string )
> row format delimited
> fields terminated by '|' stored as textfile;
hive> create table kylin_flat_db.city_tb1
> ( regionid string, cityid string, cityname string )
> row format delimited
> fields terminated by '|' stored as textfile;4、再使用加载语句,将本地两个文件内容加载到相应的维度表中。

二、在Kylin中建立项目(Project)
在Model页面点击 “+” 新建一个项目,输入project name ===》 myproject_pvuv
三、建立数据源,Load DataSource。
选择我们刚刚创建的项目后单击 Data Source ,如下图所示,有三个图标来选择加载数据的方式。1、第一个图标为:Load Hive Table,手动输入需要加载的Hive列表,表之间用逗号分隔,确保输入的是之前在Hive中已经创建的表。
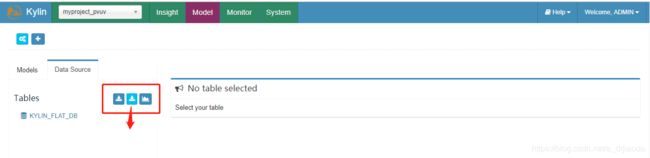
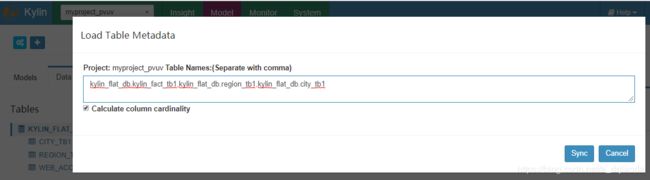
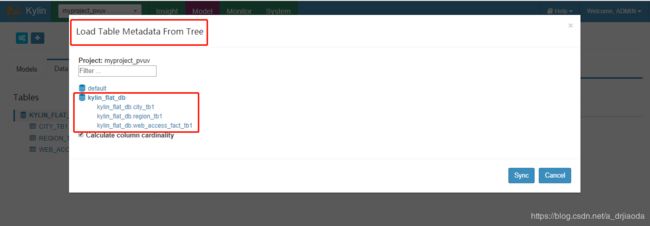
2、第二个图标是Load Hive Table From Tree,单击kylin_flat_db数据库后会列出该库下面所有的表,单击选中需要同步的表即可。
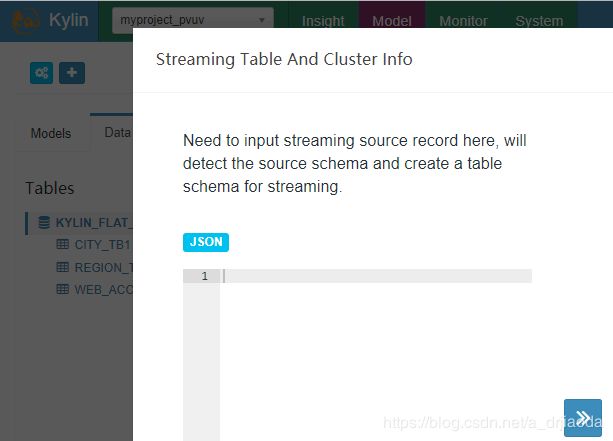
3、第三个图标:Add Streaming Table。添加实时数据流的表,格式必须是Json格式,在本版本的Kylin中有基于Kakfa定义的Streaming Table,从而完成准实时Cube的创建。
四、Kylin中建立数据模型(Model)
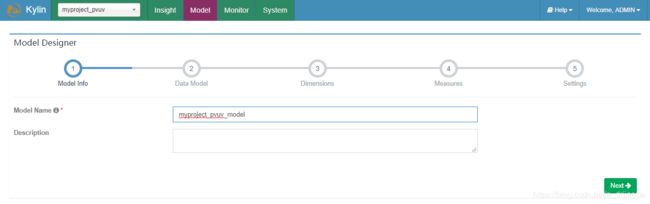
1、kylin中建立数据模型,选中New Model,在弹出如下的对话框里,输入Model名称myproject_pvuv_model,点击Next
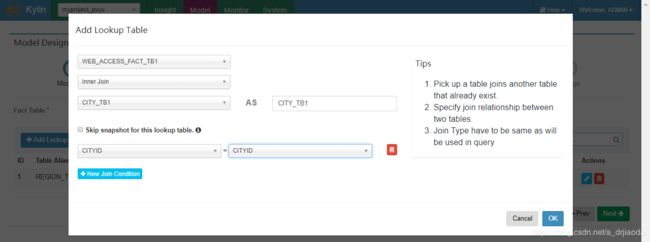
2、在Data Model里,主要就是用来选择事实表和维度表,并使用left join 或者 inner join 将其关联起来,点击Add Lookup table,可如下,选择相应的表及维度。注意:星型模型,只有一个事实表。
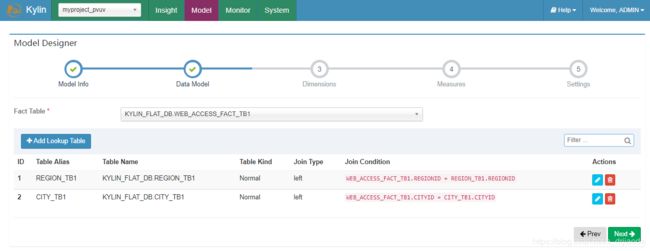
配置完成后,如下图所示:
3、Dimensions,主要是选择各个表的维度,这里我们选择能用到的维度

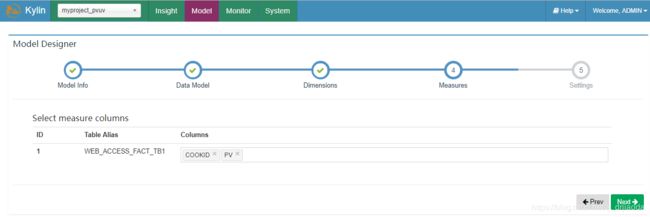
4、Measures,选择需要度量指标的字段,本例中使用cookid和PV
5、setting,设置Cube增量刷新的分区字段,字段类型可以为Date、String、Varchar等。如果分区字段为空,则每次默认为全量构建cube(不推荐此种做法)。另外,我们还可以从Hive源数据表中过滤数据,这里不行mysql需要指定where关键字,直接写过滤条件就可以,本例中为输出pv>0的数据。
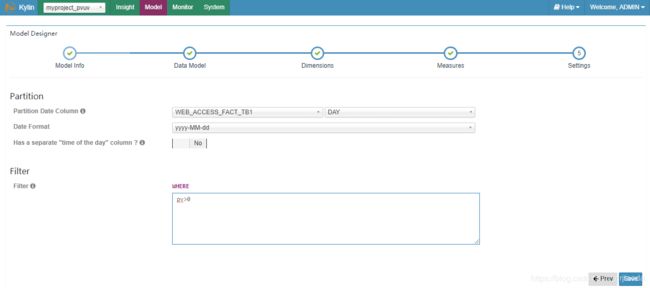
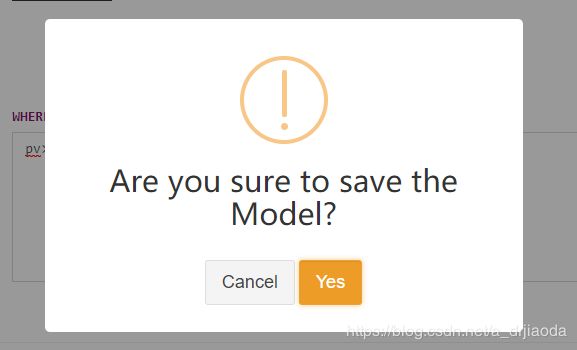
6、最后,我们保存本次创建的Model
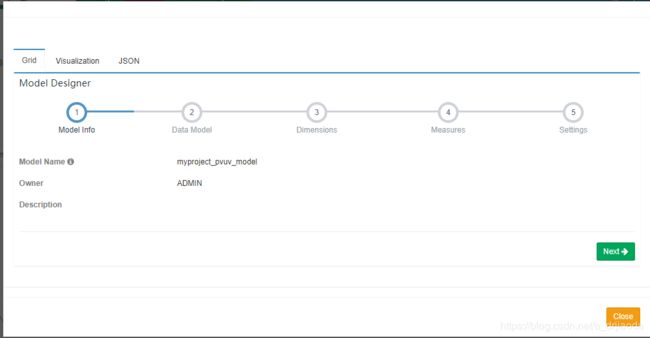
7、查看已经创建好的模型,这里有三种方式查看,分别为Grid(表格)、Visualization(可视化)、JSON(JSON格式)、如下图。
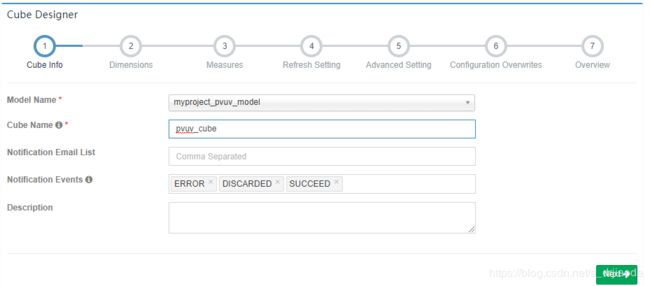
五、重点:建立cube
1、选择之前创建好的Model,填写Cube名称pvuv_cube,如果需要邮件提醒cube事件的相关信息,还能够设置邮箱列表以及发送的事件级别。
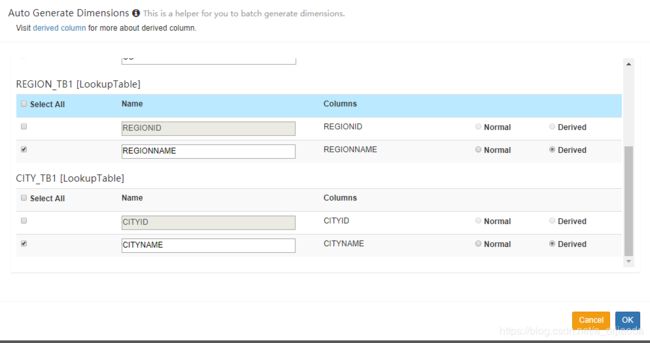
2、Dimensions,这里可以使用“add dimensions”手动添加,如下面所示,我们选择了需要展示的维度,并修改了Name。此外这里面需要提及到Type里面的两种类型normal和derived,norma是最常见的类型,与所有其他的dimension组合构成Cuboid,derived从有衍生维度的查找表获取维度,这里只是简单介绍,内容远远不止这些。
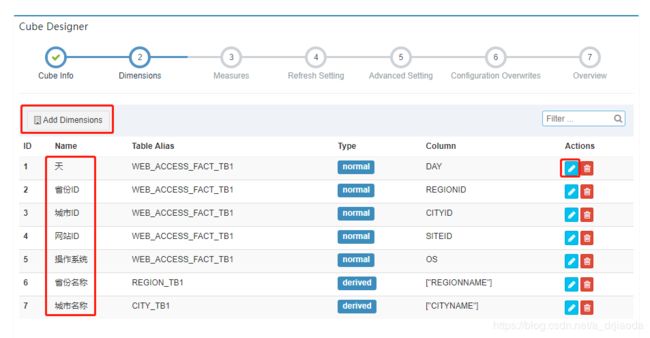
点击Actions的编辑图标,可以对Dimension的Name进行修改,比如将本来的英文名称改为中文显示。

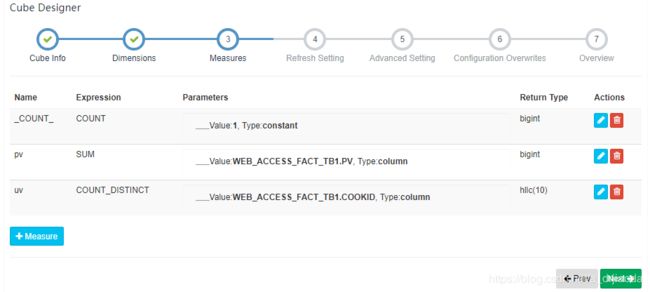
3、Measures为度量指标的设计。这里我们对pv进行sum汇总计算,对cookid进行count distinct去重过滤统计个数。
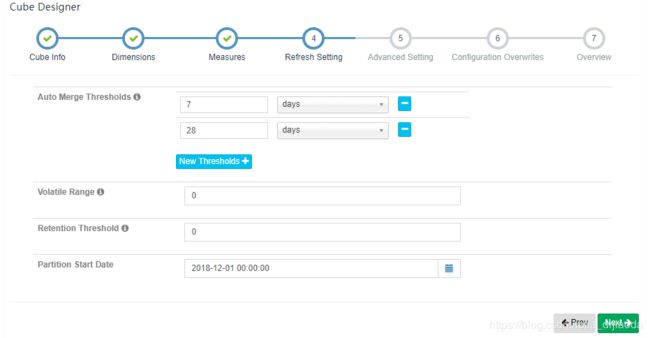
4、Refresh setting,即Cube刷新设置,这里主要用来设计增量Cube合并信息,默认每隔7天就进行merge增量的segments(每一个segment都会对应着一个物理的cube,做过增量刷新的应该会知道),每隔28天就merge前面7天合并segments。默认即可,如果有需要,也可在页面进行手动合并。这里的Partition Start Date:是Cube增量刷新的开始时间,这跟你业务数据产生第一天关联。
5、Advanced Setting,这是kylin的高级配置页面,首先是Aggravation Groups(聚合组),这部分没有截图,保持默认的内容不变即可,简单的介绍一下Aggravation Groups,这是一个将维度进行分组,已达到降低维度组合数目的手段。不同分组的维度之间组成的Cuboid数量会大大降低。那么在本例中维度组合从2的(m+n+k)最多能降低到2的m次方+2的n次方+2的k次方。维度组的设置就是为了让不出现在一个查询中的两个维度不计算Cuboid(可通过划分到两个不同的维度组中),这其实就相当于把一个cube的树结构划分成多个不同的树,可以在不降低查询性能的情况下减少Cuboid的计算量。
Hbase rowkey,下图的内容即是对Hbase Rowkey进行设计,默认Rowkey是由维度的值进行组合的,这里也是使用默认值。后面属性Encoding值为dict,就是Dictionary方式表示要为这个维度建立字典树。这在build cube的步骤中会用到。
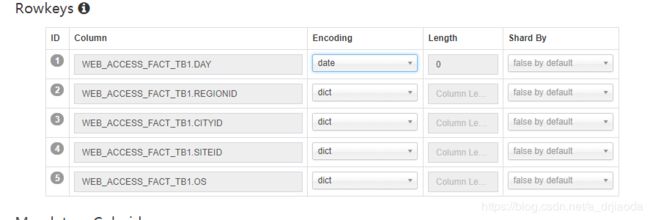
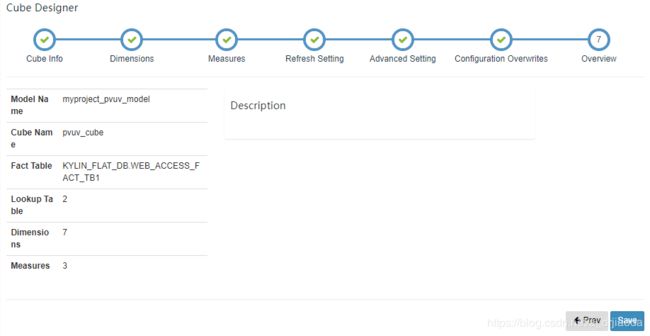
6、列出创建Cube的统计信息,如果没有问题,单机Save,并在弹出的页面点击Yes,即可完成整个Cube的创建。

六、Build Cube
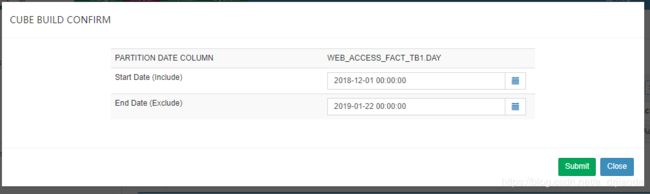
在我们的cube创建完成之后,就要开始Build了,这里我们选择增量构建方式,所谓的增量构建方式就是指从某个时间段开始到某个时间段结束,下次重新build 同一个cube时,会以上个结束时间点作为开始时间。
跳转到Monitor界面,可以查看到Build cube的详细过程,在界面的弹出窗口可以查看到构建cube的每个具体步骤,等到progress到达100%时,就代表此cube构建完成,Monitor中的Job状态显示为Finished,用户可以继续下一步操作。
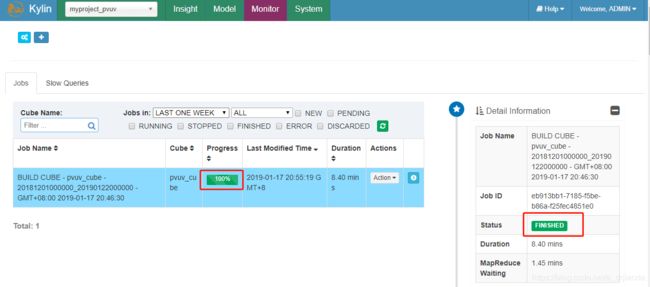
此时,回去Model可看到pvuv_cube的状态以及显示为Ready。这里面的Actions有很多操作,简单介绍一下。1 Drop,删除此cube(常规下不推荐操作);2 Edit,如果发现cube设计有问题,可以选择Edit修改;3 Build, 执行构建Cube操作,如果是增量构建,需要指定开始和结束时间;4 Refresh,对某个已经构建过的Cube Segment,重新从数据源抽取数据并构建,从而获得更新;5 Merge,对于增量Cube已经设置分区字段,这样Cube就可以进行多次Build,每一次Build就会生成一个segment并且对应一个物理的cube。这些segment的时间区间是连续并且不重合,merge就是将其合并,减少Cube的存储空间。
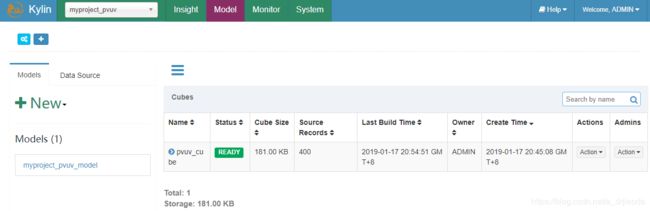
七、查询Cube
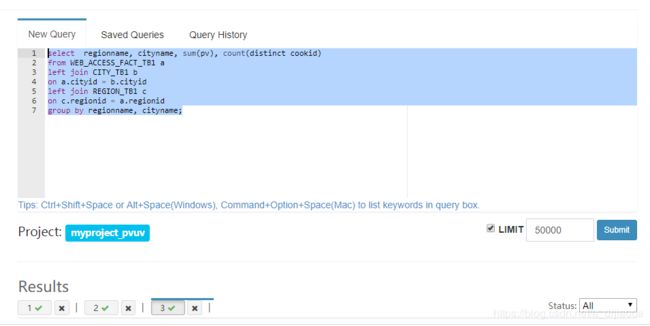
在Insight页面来验证Cube构建的结果是否正常,尝试执行下述SQL语句:
select regionname, cityname, sum(pv), count(distinct cookid)
from WEB_ACCESS_FACT_TB1 a
left join CITY_TB1 b
on a.cityid = b.cityid
left join REGION_TB1 c
on c.regionid = a.regionid
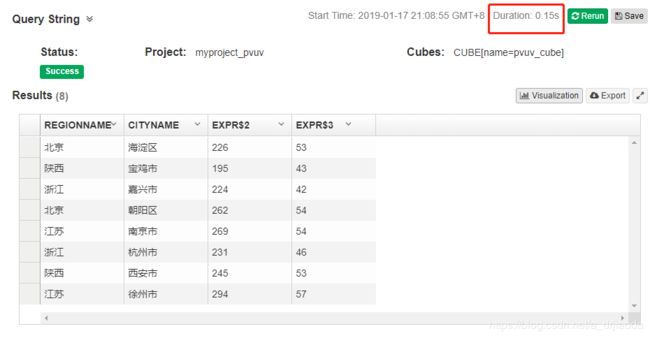
group by regionname, cityname;在kylin中执行效果如下图,其执行时间为0.15s
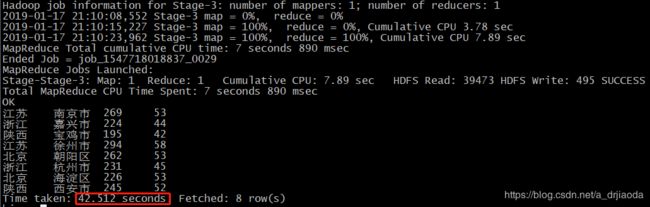
接下来,我们在hive里面执行相同SQL进行验证,可以很直观的看到hive花费了将近43s,夸张的比较一下,hive的花费的时间将近kylin的287倍。
此外,kylin还提供了一些简单的可视化,而且是非常简单
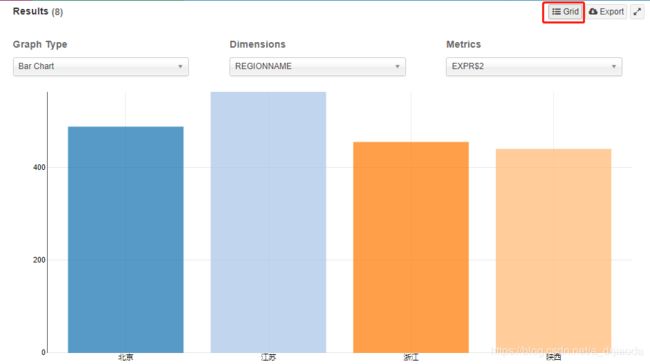
到此为止,整个Cube的设计、创建、构建、查询等步骤都有一一介绍完毕。