如果你这么去理解HashMap就会发现它真的很简单
Java中的HashMap相信大家都不陌生,也是大家编程时最常用的数据结构之一,各种面试题更是恨不得掘地三尺的去问HashMap、HashTable、ConcurrentHashMap,无论面试题多么刁钻的问,只要我们真正的掌握了它的设计思想,便可以不变应万变,hold住所有的面试题了。
本文主要包含以下内容,力求深入浅出一步一步彻底明白HashMap的设计思想:
- 数组的优势
- 数组是特殊的键值对
- Hash函数
- Hash冲突
- 此时再看HashMap源码
数组的优势

整型数组
上图是一个含有8个元素的整型数组,数组下标从0到7,
如果我们要获取第四个元素的值,直接a[3]就可以了,时间复杂度为O(1),
如果我们要将第四个元素的值替换为36,直接a[3]=36就可以了,时间复杂度也是O(1),
也就是说基于下标的随机访问和赋值数组元素的时间复杂度都是O(1),无论这个数组是多大(在内存充足的条件下),这是数组的优势之一。
数组不够,我们还需要键值对
通过上面的简单描述,我们可以知道数组可以通过“下标”来获取数组中的指定元素,但是这个下标只能是正整数,且从0开始。
但是如果我们想通过一个浮点数、一个字符串、一个对象来获取对应的元素呢?也就是所谓的键值对,是不是数组就满足不了了?
我们可以把数组看做是一种特殊的键值对,key就是数组的下标,value就是下标对应的元素:

键值对
所以我们要求KV数据结构里面的key是一个对象,而不仅仅只能是数组中的一个下标。因此我们需要创造出一种数据结构,他至少需要具有以下的特性:
- O(1)复杂度的访问任何一个key对应的值
- 这个key可以支持整型、浮点、字符串、对象等任何类型的数据
第一个特性要求我们需要一个像数组下标一样的整型数字来快速访问数组。
第二个特性要求我们的下标不限制只能是整型。
显然我们需要对key做一些特殊处理,这个时候Hash函数就上场了。
Hash函数
哈希函数的作用就是通过哈希算法把任意类型的key转换成固定类型、固定长度的散列值,也就是我们所期望的数组下标(整型)。
因此哈希函数需要具有如下的特征:
- 相同的内容经过哈希算法计算后输出结果一致;
- 不同的内容经过哈希算法计算后输出不同的结果,但也可能会出现相同的输出值(即哈希碰撞);
因此,一个优秀的哈希算法是不同的内容经过哈希计算后输出的结果具有分布均匀的特点,也就是低碰撞率。
同时,计算速度必须要快!
比较出名的哈希算法有time33算法、Murmurhash算法,这些算法都在追求更好的均匀分布和更快的计算速度。
Java8中java.lang.String类的hashCode方法实现:

java.lang.String#hashCode()
现在来写一个简单的测试类来测试Java中的String类实现的hashCode:
String s1 = "abcde";
String s2 = "abcde";
String s3 = "abcdf";
System.out.println("s1.hashCode=" + s1.hashCode());
System.out.println("s2.hashCode=" + s2.hashCode());
System.out.println("s3.hashCode=" + s3.hashCode());
输出:
s1.hashCode=92599395
s2.hashCode=92599395
s3.hashCode=92599396
可以看出来s1和s2是相同的字符串,输出了相同的hash值,s3和s1、s2不同,输出的hash值也不同,但是也很接近。
说明java采用的hash算法分散性不好,如果用Murmurhash算法,差异就会很大,即哈希算法的剧烈度大,感兴趣的同学可以用Guava中Murmurhash方法试验一下。
通过Hash算法,我们可以计算出任何一种数据类型的哈希值且为整型,这样就满足了数组的下标必须为整数的要求了。
但是又来了一个问题,通过上面的实验我们拿到的hashCode值很大,无法作为数组的下标,否则我们的数组占用的内存就太大了!
所以就采用了根据hashCode取余的方式,比如Java中的HashMap默认size是16,那么92599395%16=3,那么实际上abcde这个字符串就存储在HashMap数组中下标为3的地方。
Hash冲突
上面已经讲过Hash算法无法做到完全均匀分布,也就是说可能会有那么两个不一样的字符串经过hash计算后得到相同的值,此时两个不同的字符串都得对应同一个数组下标上,这就造成了所谓的Hash冲突。
因此,为了解决Hash冲突问题,我们需要下标对应的元素不再仅仅是当前对应的字符串了,而应该是当前的字符串再加上它的next节点的对象地址,这样的一个对象应该如下:

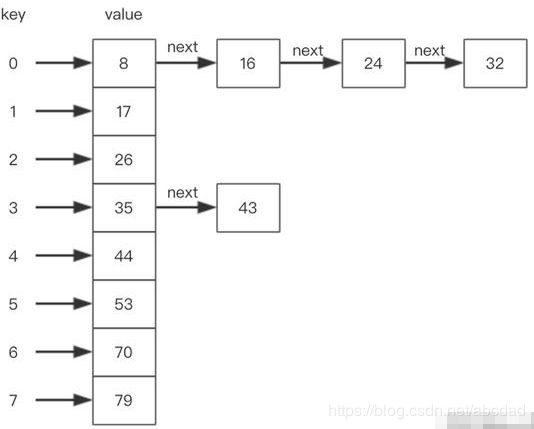
当根据key去找值时候,先计算出key的hash值再取余得到数组的下标,然后根据下标获取到元素,再判断该元素的key是否和当前的key相等(如何判断相等?equals方法!),如果不相等,继续取next节点,继续判断。
说到这里大家如果对HashMap熟悉的话,是不是发现这其实就是HashMap的简单版,一个数组+链表的实现:

JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间
再看HashMap源码
如果你已经看到这里,那么我相信你一定已经了解了HashMap的结构了,那么请回去看HashMap的源码吧,你会发现原来是这么简单!这个时候你已经达到了“看山不是山”的境界了!面试官问你任何关于HashMap的问题相信你都能回答了。
搞清楚了HashMap之后,HashTable和HashMap的区别?ConcurrentHashMap是线程安全的基于分段锁的HashMap?为了优化链表的性能,当链表的数超过8之后就变成平衡树了等等。。。
后面做的事情要么是为了线程安全要么就是为了性能。
原文地址:https://www.toutiao.com/a6782207335788970507/?tt_from=weixin&utm_campaign=client_share&wxshare_count=1×tamp=1587275061&app=news_article&utm_source=weixin&utm_medium=toutiao_android&req_id=202004191344210101290480370C18FD0D&group_id=6782207335788970507