Panoptic Feature Pyramid Networks 论文详解
论文链接:https://arxiv.org/abs/1901.02446
非官方复现代码:https://github.com/Ixuanzhang/panoptic-fpn-gluon
0. 摘要
当下用于语义分割和实例分割的方法使用的是完全不同的网络,二者之间没有很好的共享计算,该论文通过赋使用特征金字塔(FPN)的Mask R-CNN一个语义分割分支,在架构层面将这两种方法结合成一个单一网络来同时完成实例分割和语义分割的任务。
1. 介绍
该论文的目标是设计一个相对简单的单一网络来进行全景分割,即一种同时进行实例分割(for thing classes)和语义分割(for stuff classes)的分割任务,然而设计这样的一个网络面临着很大的挑战。对于语义分割任务来说,空洞卷积扩充的FCNs是目前主流的方法;对于实例分割来说,带有特征金字网络的基于区域提议的Mask R-CNN则比较常见。该论文避免了在两个任务各自的精度上做取舍,设计的模型能够同时产生实例分割中的区块输出和语义分割中的像素密集输出。
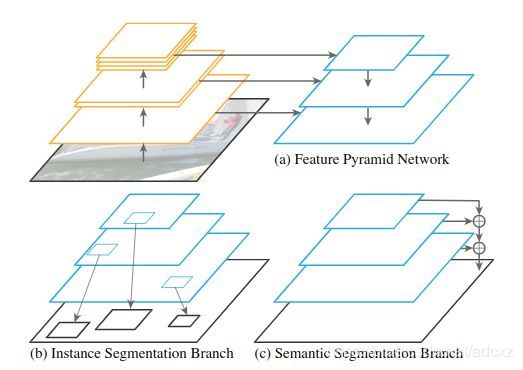
论文提出的模型结构如上图,保持FPN主干网络不变,在这个主干的基础上新增一个与实例分割分支并行的分支进行语义分割。要得到一个好的结果,同时合理训练两个分支是至关重要的。作者在如何平衡两个分支的损失函数,训练批次,学习率,数据增广等多方面进行了研究。
最终发现在coco数据集和Cityscapes数据集上,单独对每个分支进行训练最终会得到非常好的结果。实例分割效果和Mask R-CNN相同,附加在FPN后的dense-prediction(稠密预测)分支(即语义分割)的效果与重量级的模型DeepLabV3+相近。
对于全景分割来说,适当的训练单个FPN来同时解决两个问题和训练两个FPNs的效果相同,前者还能减少一半的计算量。Panoptic FPN在Mask R-CNN上加了一个轻量级的前端,内存占用和计算量上都非常高效,而且避免了使用空洞卷积。论文也可以移植使用不同的主干网络(backbone)来获得更好的性能,比如ResNeXt。
2、相关工作
2.1 全景分割(Panoptic segmentation)
stuff的语义分割和thing的实例分割的联合,成为了全景分割中的一个新的热点。本论文的任务是设计一个对两个任务都有效的single network,作为未来全景分割的一个baseline。
2.2 实例分割(Instance segmentation)
基于区域(region-based)的目标检测方法包括:Slow/Fast/ Faster / Mask R-CNN,这些都是应用deep networks去生成候选物体区域,这些已被证明很成功。带有FPN的Mask R-CNN获得了最近两年(2017、2018年)COCO检测挑战的winner。最近的一些新的创新:Cascade R-CNN、deformable convolution 、sync batch norm。带有FPN的Mask R-CNN给本文的工作提供了很好的baseline。
另一种基于区域的实例分割方法是从像素级语义分割开始,然后执行分组来提取实例。(对应论文:(1)
InstanceCut: from edges to instances with multi-cut (2)SGN:Sequential grouping networks for install segmentation (3)Pixelwise instance segmentation with a dynamically instantiated network)这一做法具有创新性、前景广阔。但这些方法倾向于使用单独的网络的来预测实例信息(例如:前面列出的方法中分别使用单独的网络来预测实例边缘、bounding boxes、object breakpoints)本文目标为联合任务设计一个单一网络。另一个有趣的方向是使用位置敏感的像素标签去全卷积编码实例信息。
2.3 语义分割(Semantic segmentation)
FCNs是现在语义分割的基础。为增加feature resolution(特征分辨率),使用dilated convolution(也叫atrous convolution空洞卷积)。一种可替代空洞卷积的方式是:encoder-decoder或‘U-Net’结构,也可增加feature resolution。编码器-解码器不断地向上采样,并将来自前馈网络的高级特征与来自下层网络的特征结合起来,最终生成语义上有意义、高分辨率的特征。但空洞卷积更长用于语义分割。
本论文采用的方法是一个encoder-decoder框架:FPN。不同于“symetric‘ decoder,FPN采用非对称的轻量级解码器。FPN作为Mask R-CNN默认的backbone,用于实例分割。FPN用于语义分割也很高效。
3. 全景分割特征金字塔网络
Panoptic FPN是一个简单的单一网络,它同时实现实例分割和语义分割并希望取得顶级的效果,两个任务一齐称为全景分割。设计原则:用一个强的实例分割做baseline:Mask R-CNN with FPN,做很小改变,生成一个语义分割的稠密像素结果输出。
3.1 模型架构
(1)特征金字塔网络:FPN网络使用一个标准的网络提取多个空间位置的特征,然后加一个轻量级的自顶而下的通路,并且和特征提取网络横向连接。自顶而下的通路在网络最深的层开始然后进行上采样,然后与其前层网络输出特征图进行相加,依次操作。最终生成原始图像的1/32,1/16,1/8,1/4四个分辨率的特征图,每个层级的通道数默认都是256.
(2)实例分割分支:FPN、相同通道数的设计都是为了基于区域提议的目标检测器更易于检测(易于附加到像Faster R-CNN这样基于区域提议的物体检测器上)。例如,FPN之后Faster R-CNN在不同的金字塔层级分别进行RoI池化,然后增加一个网络分支来为每个候选区域预测其类别得分和边界框位置。为了得到实例分割的结果,扩展Faster R-CNN新增一个FCN分支来为每一个候选区域生成一个二进制掩码图,即Mask R-CNN。
(3)Panoptic FPN:该论文的工作就是对带有FPN的Mask R-CNN进行修改使其能够进行逐像素的语义分割预测。然而为了得到这个逐像素的预测,有三个必须的条件:
一是分辨率适当高的特征图以便捕获细节信息
二是编码足够丰富的语义以准确预测类标签
三是捕获多尺度的信息
尽管FPN是为目标检测设计的,但是这三个条件FPN正好具备,因此只需要在FPN上添加一个简单的分支用于语义分割即可。

Segmetic FPN
(4)语义分割分支(Semantic segmentation branch):这个分支的构造如上图所示。开始于:最深层的FPN level(原图的1/32),执行3次上采样恢复至原图1/4的特征图。每次上采样阶段包括:3*3 convolution,group norm(分组归一化),Relu,2× bilinear upsampling(2倍的双线性插值)。这个策略在FPN的1/16、1/8、1/4尺度重复执行(逐渐上采样次数减少)。得到4个相同的1/4尺度的特征图,然后对其进行对应元素相加。最后执行1*1 convolution,4× bilinear upsampling(4倍的双线性插值),恢复至原始图片大小,使用softmax函数生成每个像素的class label(在原始图像分辨率下)。除了stuff类,这个分支也会输出一个特殊的‘other’类,针对那些属于物体的所有像素(为了避免把那些像素预测成stuff类)。
(5)其他实现细节:FPN每个金字塔层级都有256个输出通道,语义分割分支降到128个。对于FPN之前的主干网络,论文选择了带有BN(batch norm)的在ImageNet预训练的Resnet和ResNeXt。在进行微调的时候,将BN换成一个固定的信道仿射变换。
3.2 推断和训练
1) 全景分割输出结果:每个像素一个类别标签和一个实例id(stuff物体不给实例id)
实例分割和语义分割的输出会有部分重合,进行一个后处理以消除这种重合(该后处理思想和非极大值抑制思想相似):
(1)消除不同实例之间的重叠:根据它们的置信得分
(2)消除实例、语义分割见的重叠:有利于实例
(3)移除任何stuff标签为‘other’的,或者在给定的区域阈值之下的
2)联合训练:实例分割训练会产生三个损失函数即Lc (classification loss),Lb (bounding-box loss),Lm (mask loss) 。实例分割的损失就是此三者之和,前两个损失函数通过RoIs采样的数量进行归一化,后一个损失通过RoIs判定为前景的数量进行归一化。语义分割的损失为Ls,其计算了每个像素的预测和ground-truth标签间的交叉熵损失,通过已分类的像素点的数量进行归一化。
这两个分支的有不同的尺度和归一化策略,简单的 Lc+Lb+Lm+Ls 将降低其中任一项任务的最终性能。这可通过重新加权来校正。最终的损失函数为:
L= λi *(Lc+Lb+Lm)+ λs * Ls
通过精调 λi 和 λs ,可以训练一个与两个独立的任务特定模型相当的模型,但大约是计算的一半。
3.3 分析
本文使用FPN做语义分割预测的动机是创作一个简单、单一的baseline网络,其同时可做语义和实例分割。考虑我们方法和常用的语义分割的流行结构的内存和计算力是有趣的。最常用的产生高分辨率输出的设计是空洞卷积和symmetric encoder-decoder模型(对称的编码-解码模型),后者具有带有空洞连接的镜像解码器。然而我们的动机是和Mask R-CNN共存,作者认为FPN比典型的dilation-8网络更轻量化、比symmetric encoder-decoder快大约2倍、和dilation-16网络的鲁棒性相当(但产生了更高分辨率的输出)。
4. 实验和结果
论文的目标是证明Panoptic FPN可以作为一个简单有效的单网络baseline,用于实例分割、语义分割,以及他们的联合任务全景分割。因此,我们从测试语义分割方法(这个单任务变体称为Semantic FPN)开始分析,这个简单的模型在COCO和Cityscapes数据集上实现了具有竞争力的语义分割结果。接下来,分析了语义分割分支与Mask R-CNN的集成,以及联合训练的效果。最后,我们再次在COCO和Cityscapes数据集上展示了全景分割的结果。
4.1 实验步骤
单任务度量:(1)语义分割:mIoU (mean Intersection-over-Union)作为COCO、Cityscapes两个数据集的主要度量。同时对于COCO数据集,也记录了 fIoU(frequency weighted IoU),对于Cityscapes数据集,用 iIoU (instance-level IoU)(2)实例分割:AP(average precision averaged over categories and IoU thresholds)是主要的度量。主要选用的是AP50和 AP75.
全景分割度量:PQ(panoptic quality)度量Panoptic FPN的表现。PQ同时捕获识别和分割质量,并以统一的方式处理stuff和thing。同时,使用![]() 去分别记录stuff和thing的表现。
去分别记录stuff和thing的表现。
定性结果如下图:

4.2 FPN for 语义分割
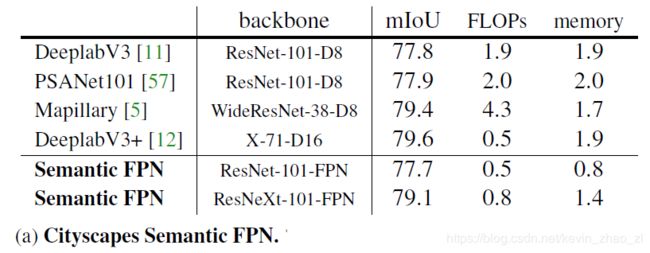
Cityscapes:在Cityscapes val split上将我们的Semantic FPN分支和其他现存方法进行比较。本文比较了最近表现最好的方法,但没有与通常使用集成、COCO预训练、test-time增强等方法进行比较。本文提出的方法与经历很多次迭代的方法,例如DeepLabV3+比也不逊色。本文的baseline有意避免了可能会带来改进的正交结构(例:Non-local、SE)的改进。就计算和内存而言,Semantic FPN比典型的空洞模型更轻量,但仍能获得高分辨率特征。比较结果图见上图a。
COCO:上图b是我们方法获得2017 coco-stuff挑战的结果。当时设计有别于现在,在语义分割分支有些微不同:每个上采样模块有2个3*3 卷ReLU、双线性插值,已得到最终的分辨率。特征是连接在一起,而不是加起来。我们的参赛作品是用彩色增强[38]训练的,在测试时平衡了类别分布,并使用多尺度推理。最后,我们注意到,当时我们使用了一个针对语义分割的培训计划,类似于Cityscapes计划(但学习速度提高了一倍,批处理大小减半)
Ablations:(模型简化测试)下图左展示了RestNet-50 Semantic FPN(语义分割分支)使用不同的通道数的效果,发现128 strikes能很好的平衡精确度和效率。下图右比较了对不同FPN layers进行sum 和 concatenation操作的效果,sum的效果更好。
4.3 多任务训练
下图展示的是:backbone为ResNet-50-FPN,对于λi 和 λs,固定其中一个,调整另一个。
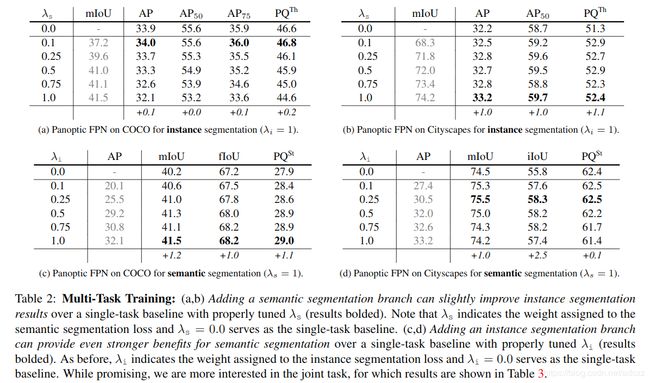
上表说明了:增加一个分支,会提高另一个分支的表现效果。
对于联合任务,结果如下图所示:其中c图:发现组合损失会有更好的效果。

4.4 Panoptic FPN
在下面的实验中λi 和 λs 从 {0.5,0.75,1.0}中选择。